Go语言内存对齐
一 内存访问粒度
内存空间是以字节为单位连续编址的。如果把内存单元比喻为小柜子,那么内单元的地址就相当于柜子的编号,如下所示

重点来了:
1、大多数小伙伴都会错误地认为:内存的小柜子是一个萝卜一个坑,每个小柜子都存放一个字节,但实际上,内存中存放的数据是一块一块存放的,一块内存包含了n个连续的小柜子,这一块内存包含的n个小柜子里可能有的并未存放数据。
2、这是因为CPU并不会以一个一个字节去读取和写入内存,相反,CPU读取内存数据就是一块一块读取的,块的大小可以是:2、4、6、8、16个字节等大小。
3、块大小称为“内存访问粒度”你以为的cpu访问内存数据的方式:一个一个字节地访问
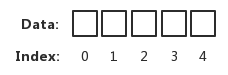
真正的访问方式:一块一块(一组一组)字节地访问,如下所示内存访问粒度为4字节
二 内存对齐介绍
内存对齐指的是计算机会将我们要存入内存中的、连续的、多个数据加以整理,整齐地放入内存中,以此来迎合cpu对内存的访问粒度,即保证cpu按照内存的访问粒度每次读取到一组数据全都是有用的,不必读无用的数据再舍弃。
为何要内存对齐呢?或者说内存不对齐带来的问题是什么呢?
- 1、内存对齐的情况下,cpu一次读取就可以拿到所有数据,而在内存未对齐情况下,cpu需要访问两次内存,并且cpu需要花费额外的时钟周期来处理对齐及运算
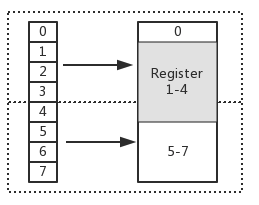
在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下:
- (1)、 CPU读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
- (2)、CPU读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
- (3)、合并 1-4 字节的数据
- (4)、合并后放入寄存器
- 从上述流程可得出,不做 “内存对齐” 是一件有点 "麻烦" 的事。因为它会增加许多耗费时间的动作
- 而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。这显然高效很多,是标准的空间换时间换时间的做法
- 2、平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
我们为何要了解内存对齐:
- 1、你正在编写的代码在性能(CPU、Memory)方面有一定的要求
- 2、你正在处理向量方面的指令
- 3、某些硬件平台(ARM)体系不支持未对齐的内存访问
三 内存对齐规则
先来看一个示例1
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
ppp:=Part1{} // 零值初始化
fmt.Println(ppp) // {false 0 0 0 0}
fmt.Printf("bool size: %d\n", unsafe.Sizeof(ppp.a))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(ppp.b))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(ppp.c))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(ppp.d))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(ppp.e))输出结果
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1结构体Part1的实例ppp是由其内部的字段组成的,所以其内部字段占据内存的大小也正是该结构体的大小。ppp内所有字段占用内存大小为 1+4+1+8+1 = 15 个字节,也就是说结构体实例ppp的内存大小为15个字节,看上去一点毛病也没有,但实际情况是
fmt.Printf("%d",unsafe.Sizeof(ppp)) // 32最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。这充分地说明了先前的计算方式是错误的。为什么呢?答案就是:因为 “内存对齐” 的影响,数据在内存中的存放超出了其本身的大小
储备知识:默认系数
在不同平台上的编译器都有自己默认的 “对齐系数”,又称为编译器的默认对齐长度,可通过预编译命令 #pragma pack(n) 进行变更,n 就是代指 “对齐系数”。一般来讲,我们常用的平台的系数如下:
32 位:4
64 位:8
另外要注意,不同硬件平台占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,调试的时候需按本机的实际情况考虑内存对齐规则:
-
1、结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(#pragma pack(n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍
-
2、结构体本身,对齐值必须为编译器默认对齐长度(#pragma pack(n))或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值
-
补充:
// 结合以上两点 可得知若编译器默认对齐长度(#pragma pack(n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
四 内存对齐流程分析
针对示例1,我们来分一下结构体ppp到底经历了什么
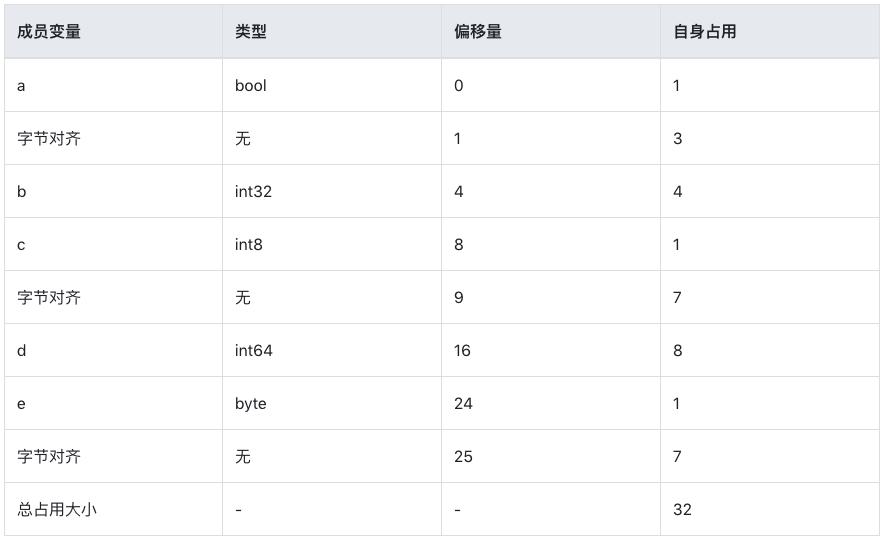
流程1:成员对齐
- 第一个成员 a
- 类型为 bool
- 大小/对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 第二个成员 b
- 类型为 int32
- 大小/对齐值为 4 字节
- 根据规则 1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此 2-4 位为 Padding。而当前数值从第 5 位开始填充,到第 8 位。如下:axxx|bbbb
- 第三个成员 c
- 类型为 int8
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 8。不需要额外对齐,填充 1 个字节到第 9 位。如下:axxx|bbbb|c…
- 第四个成员 d
- 类型为 int64
- 大小/对齐值为 8 字节
- 根据规则 1,其偏移量必须为 8 的整数倍。确定偏移量为 16,因此 9-16 位为 Padding。而当前数值从第 17 位开始写入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd
- 第五个成员 e
- 类型为 byte
- 大小/对齐值为 1 字节
- 根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 24。不需要额外对齐,填充 1 个字节到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e…
流程2:整体对齐
在每个成员变量进行对齐后,根据规则 2,整个结构体本身也要进行字节对齐,因为可发现它可能并不是 2^n,不是偶数倍。显然不符合对齐的规则
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐
流程3:结果
ppp内存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
小结
通过本节的分析,可得知先前的 “推算” 为什么错误?
是因为实际内存管理并非 “一个萝卜一个坑” 的思想。而是一块一块。通过空间换时间(效率)的思想来完成这块读取、写入。另外也需要兼顾不同平台的内存操作情况
五 内存对齐优化
内存对齐优化经验:尽可能将大小比较小的那些数据类型往前放
在上一小节,可得知根据成员变量的类型不同,其结构体的内存会产生对齐等动作。那假设字段顺序不同,会不会有什么变化呢?我们一起来试试吧
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
e byte
c int8
a bool
b int32
d int64
}
ppp1 := Part1{}
ppp2 := Part2{}
fmt.Printf("ppp1 size: %d, align: %d\n", unsafe.Sizeof(ppp1), unsafe.Alignof(ppp1))
fmt.Printf("ppp2 size: %d, align: %d\n", unsafe.Sizeof(ppp2), unsafe.Alignof(ppp2))输出
ppp1 size: 32, align: 8
ppp2 size: 16, align: 8通过结果可以惊喜的发现,只是 “简单” 对成员变量的字段顺序进行改变,就改变了结构体占用大小
接下来我们一起剖析一下 ppp2,看看它的内部到底和上一位之间有什么区别,才导致了这样的结果?
分析流程
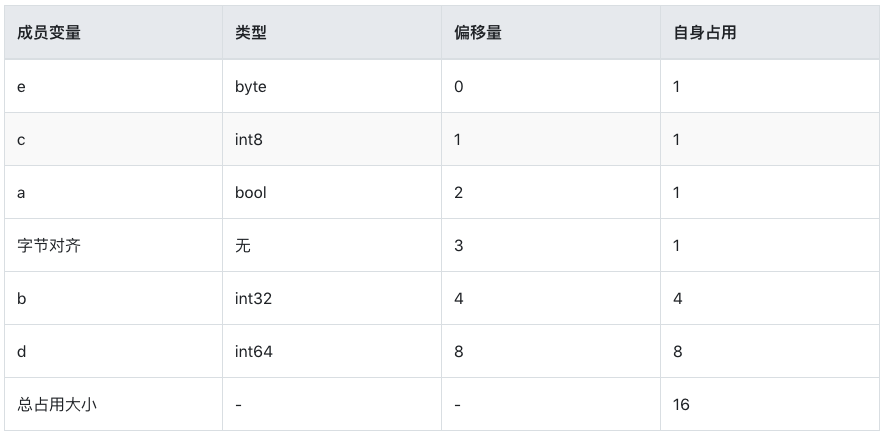
流程1:成员对齐
- 第一个成员 e
- 类型为 byte
- 大小/对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 第二个成员 c
- 类型为 int8
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 2。不需要额外对齐
- 第三个成员 a
- 类型为 bool
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 3。不需要额外对齐
- 第四个成员 b
- 类型为 int32
- 大小/对齐值为 4 字节
- 根据规则1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此第 3 位为 Padding。而当前数值从第 4 位开始填充,到第 8 位。如下:ecax|bbbb
- 第五个成员 d
- 类型为 int64
- 大小/对齐值为 8 字节
- 根据规则1,其偏移量必须为 8 的整数倍。当前偏移量为 8。不需要额外对齐,从 9-16 位填充 8 个字节。如下:ecax|bbbb|dddd|dddd
流程2:整体对齐
符合规则 2,不需要额外对齐
流程3:结果
ppp2 内存布局:ecax|bbbb|dddd|dddd
总结
通过对比 ppp1 和 ppp2 的内存布局,你会发现两者有很大的不同。如下:
- ppp1:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
- ppp2:ecax|bbbb|dddd|dddd
仔细一看,ppp1 存在许多 Padding。显然它占据了不少空间,那么 Padding 是怎么出现的呢?
通过本文的介绍,可得知是由于不同类型导致需要进行字节对齐,以此保证内存的访问边界
那么也不难理解,为什么调整结构体内成员变量的字段顺序就能达到缩小结构体占用大小的疑问了,是因为巧妙地减少了 Padding 的存在。让它们更 “紧凑” 了。这一点对于加深 Go 的内存布局印象和大对象的优化非常有帮
当然了,没什么特殊问题,你可以不关注这一块。但你要知道这块知识点