分析1880到2017年出生的美国婴儿姓名
- 获取数据
- 数据规整
- 分析数据
1、获取数据
链接:https://pan.baidu.com/s/1wIyRZfgR7EjQ_KFP5-cnaA
提取码:g0zy 2、数据规整
因为获取到的数据是根据出生年份分为了多个文件,其中文件内部的数据也是简单的通过逗号分隔而成的,所以需要规整一下:
years = range(1880,2018)
pieces = []
columns = ['name','sex','births'] # 字段参数
for year in years:
path = "D:\\data\\names\\yob%s.txt"%year # 加入自己相应的文件路径
frame = pd.read_csv(path,names=columns)
frame['year'] = year # 添加出生年份列
pieces.append(frame)
names = pd.concat(pieces,,ignore_index=True) # 合并数据集,ignore_index=True删除原索引,生成新索引通过以上操作就可以将所有的数据文件合并为一个数据集,接下来就可以进行具体的数据分析
3、分析数据
有了以上数据集就可以利用他们完成很多工作,例如:
1、以性别和出生年份分析总出生数
2、分析命名趋势
3、分析名字中最后一个字母的变化趋势接下来就主要以以上几种方式进行分析,有其他方案也可以自己添加
3.1、以性别和出生年份分析总出生数
首先,通过groupby或pivot_table在year和sex上对其进行聚合:
total_births = names.pivot_table('births',index='year',columns='sex',aggfunc=sum)
total_births.tail() # 展示最后几列数据
运行结果:
sex F M
year
2013 1750321 1886989
2014 1781072 1915239
2015 1778883 1909804
2016 1763916 1889052
2017 1711811 1834490现在就可以通过以上得到的total_births将历年出生孩子总数走势图绘制出来
# 补充(修改走势图标题为中文):
import matplotlib as mpl
mpl.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei为黑体
mpl.rcParams['axes.unicode_minus']=False #用来正常显示负号
-----------------------------------------------
total_births.plot(title='以性别和出生年份分组的出生总数')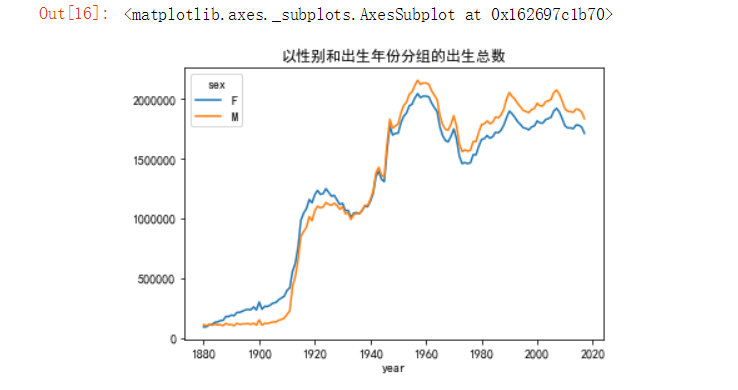
3.2、分析命名趋势
以上数据总量相对来说还是比较大的,所以接下来可以通过一系列操作只取每年取名频率前1000的数据进行分析。
# 插入一个prop列,用于存放指定名字的婴儿数相对于总出生数的比例。先按year和sex分组,然后再将新列加到各个分组上:
def add_prop(group):
group['prop'] = group.births / group.births.sum()
return group
names = names.groupby(['year','sex').apply(add_prop)
-----------------------------------------------
运行结果:
name sex births year prop
0 Mary F 7065 1880 0.077643
1 Anna F 2604 1880 0.028618
2 Emma F 2003 1880 0.022013
3 Elizabeth F 1939 1880 0.021309
4 Minnie F 1746 1880 0.019188
... ... ... ... ... ...
1924660 Zykai M 5 2017 0.000003
1924661 Zykeem M 5 2017 0.000003
1924662 Zylin M 5 2017 0.000003
1924663 Zylis M 5 2017 0.000003
1924664 Zyrie M 5 2017 0.000003接下来,就以上数据做一个简单的小检查,验证所有分组的prop的1
names.groupby(['year','sex']).prop.sum() # 验证所有分组的总和是否为1
运行结果:
year sex
1880 F 1.0
M 1.0
1881 F 1.0
M 1.0
1882 F 1.0
...
2015 M 1.0
2016 F 1.0
M 1.0
2017 F 1.0
M 1.0
Name: prop, Length: 276, dtype: float64然后就可以取出一个以上数据的子集,每对sex/year组合的前1000个名字。
def get_top_1000(group):
return group.sort_values(by='births',ascending=False)[:1000]
grouped = names.groupby(['year','sex'])
top_1000 = grouped.apply(get_top_1000)
top_1000.reset_index(inplace=True,drop=True)接下来分析的数据集相对来说就比较小了。
# 将要分析的数据分为男女两个部分
boys = top_1000[top_1000.sex == 'M']
girls = top_1000[top_1000.sex == 'F']创建一个透视表,以年份为索引,名字为聚合列
total_births = top_1000.pivot_table('births',index='year',columns='name',aggfunc=sum)然后就可以以几个常用名字绘制曲线图:
subset = total_births[['John','Harry','Mary','Marilyn']]
subset.plot(subplots=True,title='命名趋势')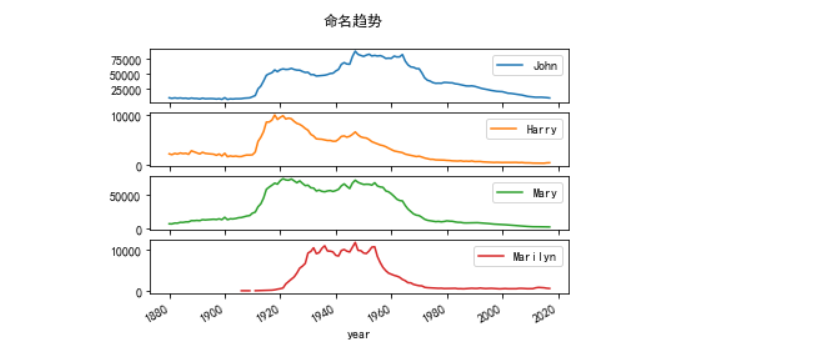
根据以上数据可以发现美国家长对于给孩子起这些常见名字的趋势。
3.3、分析名字中最后一个字母的变化趋势
# 从名称中取出最后一个字母
get_last_letter = lambda x:x[-1]
last_letters = names.name.map(get_last_letter) # 取出每个名字最后一个字母
last_letters.name = 'last_letter' # 定义新列的名字
table = names.pivot_table('births',index=last_letters,columns=['sex','year'],aggfunc=sum)
----------------------------------------------
# 取出每隔45年的数据
subtable = table.reindex(columns=[1880,1925,1970,2015],level='year') # 只取部分数据查看针对性数据
subtable.head() # 查看前几行
运行结果:
sex F M
year 1910 1960 2010 1910 1960 2010
last_letter
a 108397.0 691250.0 676646.0 977.0 5212.0 28859.0
b NaN 694.0 455.0 411.0 3914.0 39264.0
c 5.0 49.0 955.0 482.0 15460.0 23341.0
d 6751.0 3730.0 2640.0 22113.0 262136.0 44817.0
e 133600.0 435043.0 316665.0 28665.0 178785.0 130228.0
----------------------------------------------
letter_prop = subtable / subtable.sum() # 各性别各末位字母占总出生人数的比例
letter_prop
运行结果:
sex F M
year 1910 1960 2010 1910 1960 2010
last_letter
a 0.273383 0.341861 0.381261 0.005031 0.002444 0.015063
b NaN 0.000343 0.000256 0.002116 0.001836 0.020493
c 0.000013 0.000024 0.000538 0.002482 0.007250 0.012183
d 0.017026 0.001845 0.001488 0.113860 0.122932 0.023392
e 0.336947 0.215153 0.178427 0.147596 0.083844 0.067971
... ... ... ... ... ... ...
v NaN 0.000060 0.000117 0.000113 0.000036 0.001449
w 0.000020 0.000031 0.001189 0.006323 0.007709 0.016176
x 0.000015 0.000037 0.000729 0.003965 0.001851 0.008597
y 0.110975 0.152552 0.116769 0.077343 0.160976 0.058182
z 0.002436 0.000658 0.000700 0.000170 0.000184 0.001825
----------------------------------------------
fig,axes = plt.subplots(2,1,figsize=(15,10)) # 生成两个子图,分别绘制男女生趋势
letter_prop['M'].plot(kind='bar',rot=0,ax=axes[0],title='Male')
letter_prop['F'].plot(kind='bar',rot=0,ax=axes[1],title='Female')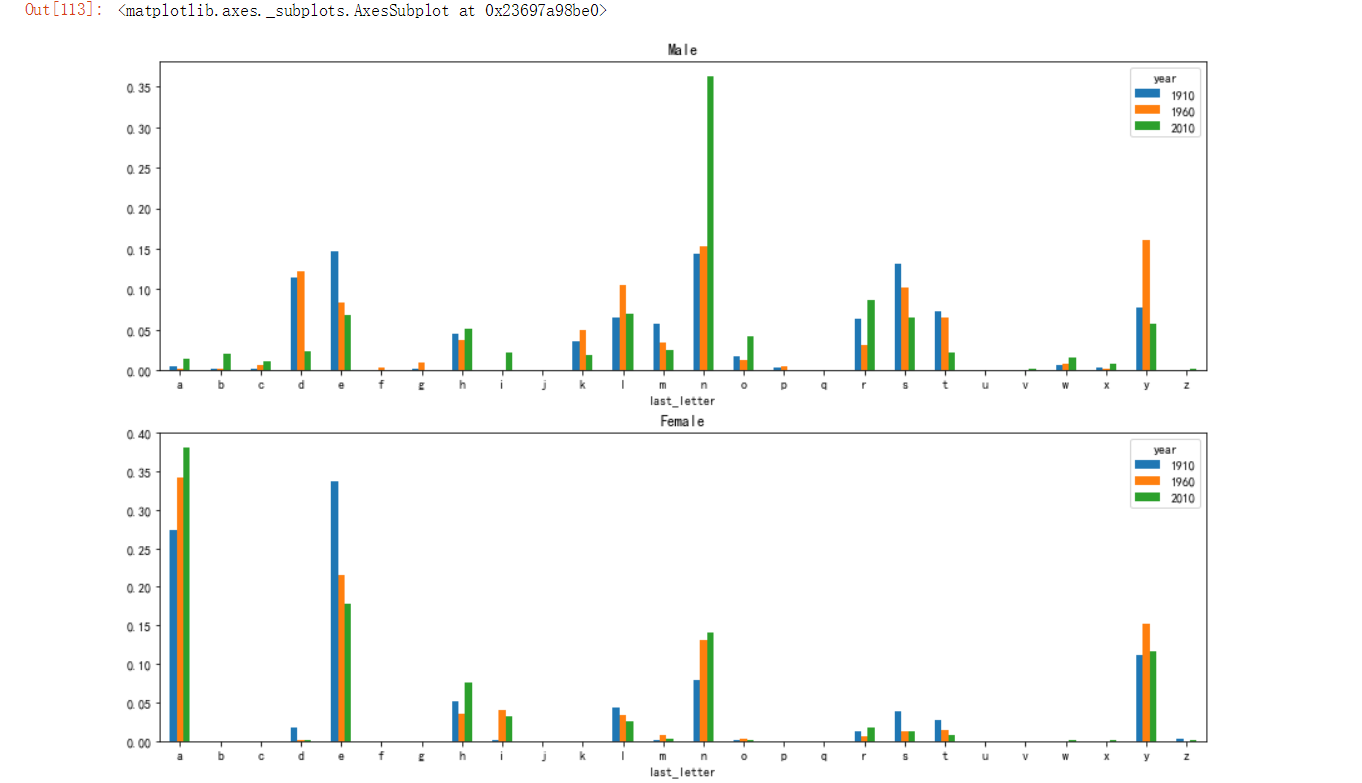
接下来就可以以出现几率最高的三个字母对男生进行分析:
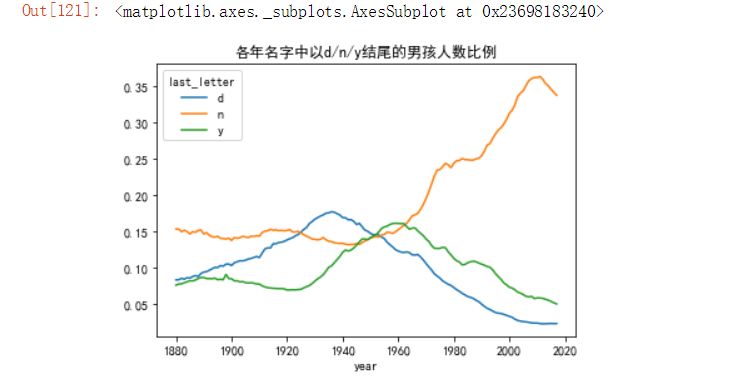
letter_prop_sum = table / table.sum() # 以之前创建的完整表计算
dny_ts = letter_prop_sum.loc[['d','n','y'],'M'].T # 以标签索引取出的d,n,y字母的数据,最后进行转置
dny_ts.plot(title='各年名字中以d/n/y结尾的男孩人数比例')