kd树
k近邻算法中讲到它有一个较为致命的缺点就是每个实例到未来新数据之间都需要计算一次距离,如果实例数趋于无穷,那么计算量是很庞大的。但是我们要知道的是计算距离是为了找到距离目标点最近的$k$个实例,那么是不是有另外一种更好的方法,能够更快速找到这$k$个最近的实例呢?由此kd树被发明了出来。
kd树(k-dimensional tree)简单而言就是$k$个特征维度的二叉树,要注意这里的$k$值和k近邻算法中的$k$值不同。

kd树学习目标
- kd树的构造与搜索
- kd树流程
- kd树优缺点
kd树引入
# kd树引入图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
# 测试点
plt.scatter(5, 6, marker='s', c='k', s=50)
plt.text(5, 5, s='《未知类型的电影》(5,6)', fontproperties=font, ha='center')
# 生成动作片
np.random.seed(1)
action_x1 = np.random.randint(1, 7, 15)
action_x2 = np.random.randint(8, 17, 15)
plt.scatter(action_x1, action_x2, marker='o', s=30, c='r', label='动作片')
# 生成爱情片
romance_x1 = np.random.randint(8, 17, 15)
romance_x2 = np.random.randint(1, 7, 15)
plt.scatter(romance_x1, romance_x2, marker='x', s=30, c='g', label='爱情片')
# 测试文本标记
plt.text(4, 11, s='A', ha='center')
plt.text(5, 7, s='B', ha='center')
plt.text(1, 14, s='C', ha='center')
plt.xlim(0, 18)
plt.ylim(0, 18)
plt.xlabel('接吻镜头(次)', fontproperties=font)
plt.ylabel('打斗场景(次)', fontproperties=font)
plt.title('kd树引入图例', fontproperties=font, fontsize=20)
plt.legend(prop=font)
plt.show()
这里将继续沿用k近邻算法的例子。
如上图所示,假设现有一部《未知类型的电影》,k近邻的思想是计算出数据集中每一部电影到《未知类型的电影》的距离,之后找到$k$个近邻对《未知类型的电影》分类。但是可以发现如电影C这样偏僻位置的电影明显是可以不用计算它们与《未知类型的电影》的距离的。
那现在假设有没有这么一种可能?我们不再计算每部电影到《未知类型的电影》的距离,而是直接得到《未知类型的电影》最近的$k$部电影?首先这种假设应该不可能,其次真的有,那还要其他机器学习算法作甚?那么再想想能不能通过某种方法找到离《未知类型的电影》较近的电影呢?我们假设有这种方法,并且这种方法被称作kd树,我们看看它是如何实现的。
- 比如kd树找到电影A即离《未知类型的电影》较近的某部电影,然后把距离大于电影A到《未知类型的电影》之间的电影排除掉,或者是继续找找看有没有哪部电影到《未知类型的电影》的距离更近?
- 如果可以找到电影A,则也可以kd树找到电影B
- 递归使用kd树搜索直到找到最近的某几部电影,停止搜索
上述整个过程其实就是kd树实现的一个过程,接下来将从理论层面抽象的讲解kd树。
kd树详解
构造kd树
kd树主要是不断地划分$k$维空间。
在一个二维空间平面中,kd树则是不断地使用垂直于$x$轴或$y$轴的直线把平面划分成一系列较小的矩形。在$k$维空间中,kd树则是不断地用垂直于坐标轴的超平面将$k$维空间切分成一系列的$k$维超矩形区域。
假设有$m$个实例$n$维特征的数据集
$$
T={(x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m)}
$$
其中$x_i$是实例的特征向量即$({x_i}^{(1)},{x_i}^{(2)},\cdots,{x_i}^{(n)})$,$y_i$是实例的类别,数据集有${c_1,c_2,\cdots,c_j}$共$j$个类别。
- 构造k维空间的超矩形区域。如果是有两个特征$x_1$和$x2$的二维空间,则是由$(x1{min},x1{max},x2{min},x2_{max})$构成的矩形区域
- 选择特征$x^{(1)}$为坐标轴,以$T$中所有实例的$x^{(1)}$坐标的中位数作为切分点,将根结点对应的超矩形区域切分成左右两个子区域。将$x^{(1)}$对应值小于切分点的实例划入左子区域;将$x^{(1)}$对应值大于切分点的实例划入右子区域;将切分点保留在根结点
- 重复2步骤,即选择$x^{(l)}, \quad (l=1,2,\cdots,n)$为切分的坐标轴,以该结点中还剩下的$k$个实例的$x^{(l)}$坐标的中位数作为切分点,将该结点对应的超矩形区域切分成左右两个子区域。将$x^{(l)}$对应值小于切分点的实例划入左子区域;将$x^{(l)}$对应值大于切分点的实例划入右子区域;将切分点保留在该结点
- 切割后的子区域没有实例时,即无法划分时结束
构造kd树时需要注意左子结点对应坐标$x^{(l)}$小与切分点的$x^{(l)}$坐标,右子结点对应坐标$x^{(l)}$大于切分点的$x^{(l)}$坐标。

示例
假设有一个二维空间$(x_1,x_2)$的数据集
$$
T = {(2,3)^T,(5,4)^T,(9,6)^T,(4,7)^T,(8,1)^T,(7,2)^T}
$$
首先$x$轴上的数据有$(2、4、5、7、8、9)$,中位数为$7$(注:如果以$5$划分也行,但是本文都是以较大的作为切分点,但是不能以${\frac{5+7}{2}}$划分,总之划分点符合kd树的构造要求即可),则以$x=7$划分一次矩形区域;左子区域$y$轴上的数据有$(3、4、7)$,中位数为$4$,则以$y=4$划分一次数据,接着以$x$轴上的数据划分,而$x$轴数据只剩下$(2,4)$,直接以$x=4$划分左子区域的右子区域,以$x=2$划分左子区域的左子区域;右子区域$y$轴上数据有$(1、6)$,由于划分点需要大于左子结点的,因此右子结点为$(9,6)$,即以$y=6$划分左子区域,接着只剩下一个点$(8,1)$,又以$x$轴划分,则以$x=8$划分。
通过以上划分,即可得以下特征空间划分图。
# kd树的构造示特征空间划分图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
plt.scatter(2, 3, c='r', s=30)
plt.text(2, 3.5, s='$(2,3)$', ha='center')
plt.scatter(5, 4, c='r', s=30)
plt.text(5, 4.5, s='$(5,4)$', ha='center')
plt.scatter(9, 6, c='r', s=30)
plt.text(9, 6.5, s='$(9,6)$', ha='center')
plt.scatter(4, 7, c='r', s=30)
plt.text(4, 7.5, s='$(4,7)$', ha='center')
plt.scatter(8, 1, c='r', s=30)
plt.text(8, 1.5, s='$(8,1)$', ha='center')
plt.scatter(7, 2, c='r', s=30)
plt.text(7, 2.5, s='$(7,2)$', ha='center')
plt.hlines(4, 0, 7, linestyle='-', color='k')
plt.hlines(6, 7, 10, linestyle='-', color='k')
plt.vlines(2, 0, 4, linestyle='-', color='k')
plt.vlines(4, 4, 10, linestyle='-', color='k')
plt.vlines(7, 0, 10, linestyle='-', color='k')
plt.vlines(8, 0, 6, linestyle='-', color='k')
plt.xlim(0, 10)
plt.ylim(0, 10)
plt.title('kd树构造-示例图例1', fontproperties=font, fontsize=20)
plt.show()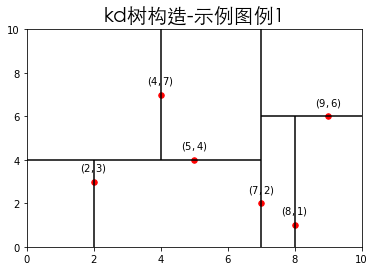
同超矩形区域划分一样可以构造如下图所示的kd二叉树
首先以$x$轴作为划分轴,$x$轴上的数据有$(2、4、5、7、8、9)$,中位数为$7$,根结点为$(7,2)$,左子结点$(2,3)、(4,7)、(5,4)$,右子结点$(8,1)、(9,6)$;之后以$y$轴作为划分轴,左子结点$y$轴有数据$(3、4、7)$,则左子结点的中位数为$4$,则左子结点$(5,4)$,左子结点的左孙子结点$(2,3)$,左子结点的右孙子结点$(4,7)$;右子结点$y$轴有数据$(1、6)$,则有右子结点$(9,6)$,右子结点的左孙子结点$(8,1)$。
# kd树的构造kd二叉树形成图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
plt.scatter(20, 15, c='white', edgecolor='k', s=2000)
plt.text(20, 14.5, s='$(7,2)$', ha='center',
fontsize=15, color='k', fontweight='bold')
plt.annotate(s='', xytext=(18.5, 13.5), xy=(13.5, 11.5),
arrowprops=dict(arrowstyle="-", color='b'))
plt.scatter(12, 10, c='white', edgecolor='k', s=2000)
plt.text(12, 9.5, s='$(5,4)$', ha='center',
fontsize=15, color='k', fontweight='bold')
plt.annotate(s='', xytext=(12, 8), xy=(9, 5),
arrowprops=dict(arrowstyle="-", color='b'))
plt.scatter(8, 3, c='white', edgecolor='k', s=2000)
plt.text(8, 2.5, s='$(2,3)$', ha='center',
fontsize=15, color='k', fontweight='bold')
plt.scatter(16, 3, c='white', edgecolor='k', s=2000)
plt.text(16, 2.5, s='$(4,7)$', ha='center',
fontsize=15, color='k', fontweight='bold')
plt.annotate(s='', xytext=(12, 8), xy=(16, 5),
arrowprops=dict(arrowstyle="-", color='b'))
plt.scatter(28, 10, c='white', edgecolor='k', s=2000)
plt.text(28, 9.5, s='$(9,6)$', ha='center',
fontsize=15, color='k', fontweight='bold')
plt.annotate(s='', xytext=(21.5, 13.5), xy=(26, 11),
arrowprops=dict(arrowstyle="-", color='b'))
plt.scatter(24, 3, c='white', edgecolor='k', s=2000)
plt.text(24, 2.5, s='$(8,1)$', ha='center',
fontsize=15, color='k', fontweight='bold')
plt.annotate(s='', xytext=(27, 8), xy=(24.5, 5),
arrowprops=dict(arrowstyle="-", color='b'))
plt.hlines(15, 24, 38, linestyle='--', color='r')
plt.text(39, 14.5, ha='center', color='r', s='X', fontsize=15)
plt.hlines(10, 32, 38, linestyle='--', color='b')
plt.text(39, 9.5, ha='center', color='b', s='Y', fontsize=15)
plt.hlines(3, 28, 38, linestyle='--', color='r')
plt.text(39, 2.5, ha='center', color='r', s='X', fontsize=15)
plt.xlim(-1, 40)
plt.ylim(-1, 20)
plt.title('kd树构造-示例图例2', fontproperties=font, fontsize=20)
plt.show()
kd树搜索
从根结点出发,递归的向下访问kd树,如果目标点$x$的$x^{(l)}$维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶子结点为止,并假设该叶子结点为目标点的当前最近点。
递归的从该叶子结点向上回退,对每个结点上的实例都进行如下操作:
- 如果该实例到目标点的距离更近,则以该实例点为当前最近点
- 检查当前最近点父结点的另一子结点对应的区域是否有更近的点,即另一子结点的超矩形区域是否与以目标点为球心、以目标点到当前最近点的半径形成的超球体是否相交
- 如果相交,则另一子结点对应的超矩形区域内存在离目标点更近的点,移到另一子结点继续递归搜索
- 如果不相交,则向上回退
- 当回退到根结点时结束,目标点的最近邻点为当前最近点
上述kd树搜索的过程可以看出,由于很多实例点所在的超矩形区域和超球体不相交,压根不需要计算距离,打打节省了计算时间。
但是值得注意的是kd树的平均计算复杂度为$O(\log{N})$,当特征维数接近训练集实例数时,kd树的搜索效率则会迅速下降,几乎接近线性扫描。
示例
接下来将拿上一节构造的kd树举例kd树搜索的整个过程,假设目标点为$(2,4.5)$。
- 搜索目标点对应的叶子结点
- 从根结点$(7,2)$开始查找,由于$(7,2)$是由$x=7$划分的,并且目标点的$x$值为$2$,由于$2<7$则到左子$(5,4)$结点
- 由于$(5,4)$是由$y=4$分隔超平面的,并且目标点的$y$值为$4.5$,由于$4.5>4$则到右子$(4,7)$叶子结点
- 假设$(4,7)$叶子结点为当前最近结点
- 目标掉搜索到叶子结点的路径为$(7,2)\rightarrow(5,4)\rightarrow(4,7)$
- 搜索目标点对应的当前最近点
- 当前最近结点$(4,7)$到目标点的距离为$3.2$,而当前最近结点的父节点$(5,4)$到目标点的距离为$3.0$,则当前最近结点更新为$(5,4)$
- 以下图蓝色五角星目标点$(2,4.5)$为圆心,以当前最近结点$(5,4)$到目标点的距离$3.0$为半径做一个超球体,即下图的红色圆圈
- 可以发现红色圆圈和$y=4$超平面相交,因此进入$(5,4)$的左子结点查找,即找到$(2,3)$
- 计算$(2,3)$到目标点的距离为$1.5$,则当前最近结点更新为$(2,3)$
- 以下图蓝色五角星目标点$(2,4.5)$为圆心,以当前最近结点$(2,3)$到目标点的距离$1.5$为半径做一个超球体,即下图的绿色圆圈
- 由于结点$(2,3)$为叶子结点,开始沿父结点回溯,父结点$(5,4)$已经考虑过,继续往上回溯到$(7,2)$
- 绿色圆圈和$x=7$没有相交,又由于$(7,2)$为根节点,搜索结束
- 通过上述搜索目标点最近点为$(2,3)$,最近距离为$1.5$
值得注意的是上述都是以最近邻展开讨论kd树的,如果想得到$k$个近邻,只需要最后保留$k$个最近邻的结点上的实例点即可,之后依据多数表决法即可获得目标点的类别;如果是回归问题,取$k$个近邻点的标记值的平均数或中位数即可。
# kd树的构造示特征空间划分图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
plt.scatter(2, 3, c='r', s=30)
plt.text(2, 3.5, s='$(2,3)$', ha='center')
plt.scatter(5, 4, c='r', s=30)
plt.text(5, 4.5, s='$(5,4)$', ha='center')
plt.scatter(9, 6, c='r', s=30)
plt.text(9, 6.5, s='$(9,6)$', ha='center')
plt.scatter(4, 7, c='r', s=30)
plt.text(4, 7.5, s='$(4,7)$', ha='center')
plt.scatter(8, 1, c='r', s=30)
plt.text(8, 1.5, s='$(8,1)$', ha='center')
plt.scatter(7, 2, c='r', s=30)
plt.text(7, 2.5, s='$(7,2)$', ha='center')
plt.hlines(4, 0, 7, linestyle='-', color='k')
plt.hlines(6, 7, 10, linestyle='-', color='k')
plt.vlines(2, 0, 4, linestyle='-', color='k')
plt.vlines(4, 4, 10, linestyle='-', color='k')
plt.vlines(7, 0, 10, linestyle='-', color='k')
plt.vlines(8, 0, 6, linestyle='-', color='k')
plt.scatter(2, 4.5, s=30410, c='white', edgecolor='r')
plt.scatter(2, 4.5, s=15000, c='white', edgecolor='g')
plt.scatter(2, 4.5, s=50, c='b', marker='*')
plt.text(2, 5, s='目标点$(2,4.5)$', ha='center',fontproperties=font)
plt.scatter(2, 3, c='r', s=30)
plt.scatter(4, 7, c='r', s=30)
plt.xlim(0, 10)
plt.ylim(0, 10)
plt.title('kd树搜索-示例图例', fontproperties=font, fontsize=20)
plt.show()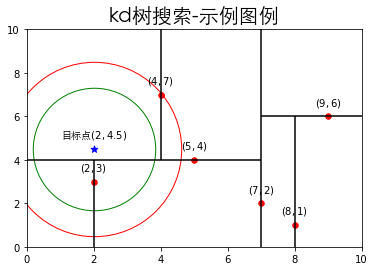
kd树流程
输入
有$m$个实例$n$维特征的数据集
$$
T={(x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m)}
$$
其中$x_i$是实例的特征向量即$({x_i}^{(1)},{x_i}^{(2)},\cdots,{x_i}^{(n)})$。
输出
距离目标点最近的$k$个实例及$k$个实例到目标点的距离。
流程
- 构造kd树
- 搜索离目标点最近的$k$个实例点
- 分类问题依据多数表决法即可获得目标点的类别;如果是回归问题,取 ? 个近邻点的标记值的平均数或中位数即可。
kd树优缺点
优点
- 简单易懂,容易实现,可以做分类也可以做回归
- 基于实例学习,对数据没有假设,不需要通过模型训练获得参数
- 较于k近邻算法计算量减少了
缺点
- 无论哪一种距离度量方式都需要使用到特征值之间的差值,如果某些特征值之间的差值过大会掩盖差值较小特征对预测值的影响(一般使用数据预处理中的归一化方法处理特征值)
- kd树的建立需要大量的内存消耗(换内存吧!!!)
- 相比较决策树,解释型不强(客户真的想要解释性强的模型可以换决策树试一试)
小结
kd树更多的使用了二叉树的思路,当然它也很好的实现了我们想要实现的,这就可以了。
如果你细心的话,可以发现在搜索的过程中,如果超球体碰到了超矩形的一点棱角就需要去搜索超矩形区域内有没有离目标点更近的点,当然有解决方法,可以使用球树(ball tree),但是其实较kd树并没有那么明显的优化,这里就不多叙述了。简而言之就是球树相较于kd树使用的是超球体切割数据集,有兴趣的可以自己思考思考(先构造一个最小球体包含所有数据,然后递归构造小球体——先选择一个离第一个球体中心最远的点A,再选择一个离点A最远的点B,那个数据离哪个点近则属于哪一个点的那一类,这样就完美把一个球体切分成两个球体)。
kd树讲完,k近邻也就告一段落了。下一篇的机器学习算法听起来可能和传统算法中的树结构有关,但它到底是不是一个树结构的机器学习算法呢?看完了就知道了——决策树。