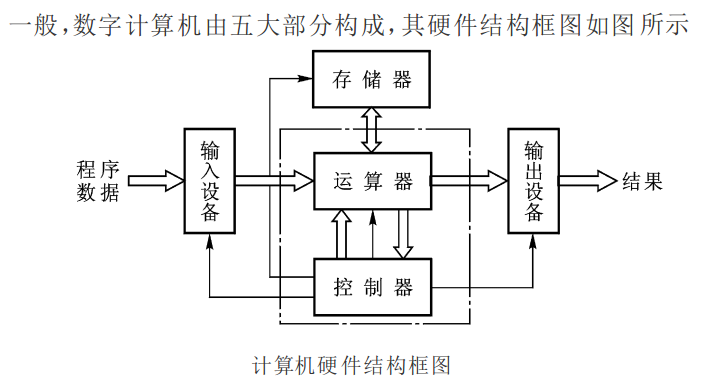
爬虫or数据分析

使用requests库爬取哔哩哔哩视频弹幕,结合BeautifulSoup解析爬取的数据
使用数据分析常用库pandas、numpy对数据做进一步处理
最后通过结巴分词以及词云库将分析结果展示出来
导入模块
import requests
from bs4 import BeautifulSoup
import datetime
import pandas as pd
import matplotlib.pyplot as plt
import re
import jieba
import numpy as np
from wordcloud import WordCloud, ImageColorGenerator爬取数据
url = "https://comment.bilibili.com/92542241.xml"
r = requests.get(url)
r.encoding = 'utf8'
soup = BeautifulSoup(r.text,'lxml')
d = soup.find_all('d')
dlst = []
n = 0
for i in d:
n += 1
danmuku = {}
danmuku['弹幕'] = i.text
danmuku['网址'] = url
danmuku['时间'] = datetime.date.today()
dlst.append(danmuku)
df = pd.DataFrame(dlst)
with open('sign.txt','w',encoding='utf8') as f:
for text in df['弹幕'].values:
pattern = re.compile(r'[一-龥]+')
filter_data = re.findall(pattern,text)
f.write("".join(filter_data))数据分析
with open('sign.txt', 'r', encoding='utf8') as f:
data = f.read()
segment = jieba.lcut(data)
words_df = pd.DataFrame({"segment": segment})
word_stat = words_df.groupby(by=['segment'])['segment'].agg({'计数':np.size})
words_stat = word_stat.reset_index().sort_values(by=['计数'],ascending=False)
color_mask = imread('01.jpg')
wordcloud = WordCloud(
# font_path="simhei.ttf", # mac上没有该字体
font_path="C:\Windows\Fonts\simkai.ttf",
# 设置字体可以显示中文
background_color="white", # 背景颜色
max_words=3000, # 词云显示的最大词数
mask=color_mask, # 设置背景图片
max_font_size=200, # 字体最大值
random_state=100,
width=1000, height=860, margin=2,
# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数
word_frequence = {x[0]: x[1] for x in words_stat.head(500).values}
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 从背景图片生成颜色值
# image_colors = ImageColorGenerator(color_mask)
# 重新上色
# wordcloud.recolor(color_func=image_colors)
# 保存图片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()