熵和信息增益
熵(Entropy)
熵表示随机变量不确定性的度量。假设离散随机变量$X$可以取到$n$个值,其概率分布为
$$
P(X=x_i)=pi, \quad i = 1,2,\ldots,n
$$
则$X$的熵定义为
$$
H(X) = -\sum{i=1}^n p_i log{pi}
$$
由于熵只依赖$X$的分布,与$X$本身的值没有关系,所以熵也可以定义为
$$
H(p) = -\sum{i=1}^n p_i log{p_i}
$$
熵越大,则随机变量的不确定性越大,并且$0\geq{H(p)}\leq\log{n}$。
当随机变量只取两个值$0$和$1$的时候,$X$的分布为
$$
P(X=1)=p, \quad P(x=0)=1-p, \quad 0\geq{p}\leq{1}
$$
熵则是
$$
H(p) = -p\log_2 p-(1-p) \log_2(1-p)
$$
此时随机变量为伯努利分布,熵随概率变化的曲线如下图所示
import numpy as np
from math import log
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
p = np.arange(0.01, 1, 0.01)
entro = -p*np.log2(p) - (1-p)*np.log2(1-p)
plt.plot(p, entro)
plt.title('伯努利分布时熵和概率的关系', fontproperties=font)
plt.xlabel('p')
plt.ylabel('H(p)')
plt.show()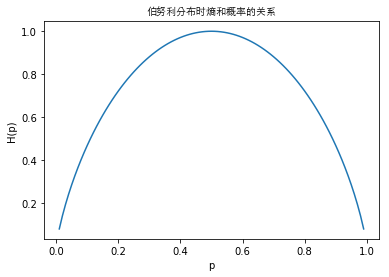
当$p=0$和$p=1$时熵值为$0$,此时随机变量完全没有不确定性;当$p=0.5$时的熵值最大,随机变量的不确定性最大。
条件熵(Conditional Entropy)
假设有随机变量$(X,Y)$,其联合概率为
$$
p(X=x_i,Y=yi), \quad i=1,2,\ldots,n; \quad j=1,2,\ldots,m
$$
条件熵$H(Y|X)$表示在已知随机变量$X$的条件下随机变量$Y$的不确定性,定义为
$$
H(Y|X) = \sum{i=1}^n P(X=x_i) H(Y|X=x_i)
$$
通过公式可以把条件熵理解为在得知某一确定信息的基础上获取另外一个信息时所获得的信息量。
当熵和条件熵中的概率由数据估计获得时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。