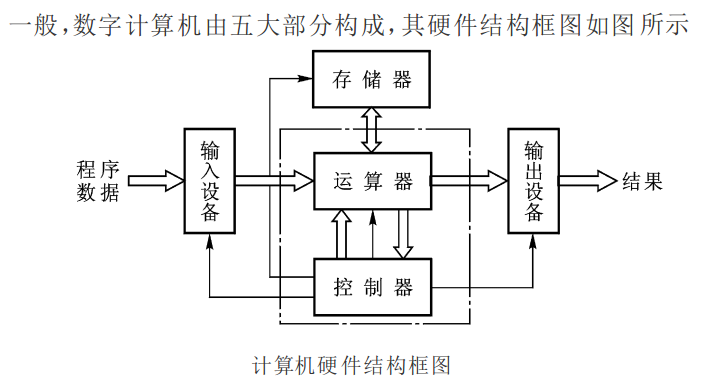
前不久有好几家数据相关的公司被抓了,再加上一些媒体对爬虫技术相关的 “吃牢饭” 报道,弄得人心惶惶——这…爬虫玩得好,牢饭吃得早?数据玩得 6 ,牢饭吃个够?

因为之前小帅b分享过一些爬虫相关的教程,所以有些 b 友会来问我爬虫相关的 “安全” 问题,想了下,今天就给大家说道说道吧,也没什么,就是想跟你说说:如何通过爬虫让你更快的进去吃吃牢房。

去爬取一个网站资源的时候,当然是对他们的 robots 协议当做屁啦,直接无视里面的 Disallow ,你爱爬啥就爬啥,协议只不过是几个字符而已。
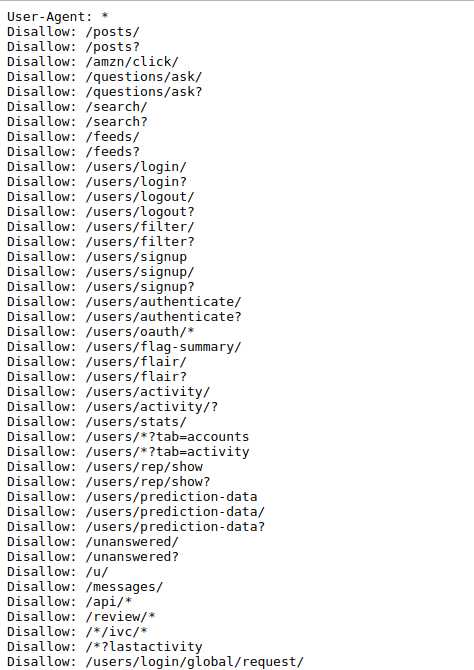
对于一些网站的用户协议,看都不看一眼,眼睛都不带眨的,请求数据包抓起,代码撸起,程序跑起…嗨起来呀喂。

(来自今日头条)
什么?有人找你接单?爬取别人的手机号码、姓名、住址?对你来说洒洒水啦,什么侵犯个人隐私数据?什么别人会被各种诈骗和推销电话轰炸?盘它!
什么?想通过爬虫赚点小钱,去爬取别的网站各种盗版视频图片,然后一股脑上传到自己的网站给别人下载,这用户访问量多了,那就在网站上面投放广告啊。什么是版权?管他呢,被动收入,想想就开心。
啥?想搞擦边球?女优?国产?欧美?还想在里面整点 du(二声) 和 du(三声)?
可以可以,比别人更早一步进去。

想要快点抓取数据?多进程搞起,并发搞起,分布式搞起。什么控制访问?sleep是什么哦?对方服务器宕机怎么了?
人家要的就是速度与激情,要的那种唰唰唰的感觉。

(来自中国网信网)
听说你还想动别人的奶酪?人家不提供开放 API 也不管,直接把别人的私有商业数据爬取下来,然后换个壳整起来,要的就是效率,培养用户太慢了,要刷量?要牛逼?那就整起!
…

转载自公众号:学习Python的正确姿势