线性可分支持向量机
线性可分支持向量机学习目标
- 线性可分支持向量机、线性支持向量机、非线性支持向量机区别
- 函数间隔与几何间隔
- 目标函数与目标函数的优化问题
- 支持向量和间隔边界
- 线性可分支持向量机的步骤
支持向量机引入
支持向量机(support vector machines,SVM)诞生二十多年,由于它良好的分类性能席卷了机器学习领域,如果不考虑集成学习、不考虑特定的训练数据集,SVM由于泛化能力强,因此在分类算法中的表现排第一是没有什么异议的,通常情况下它也是首选分类器。近几年SVM在图像分类领域虽有被深度学习赶超的趋势,但由于深度学习需要大量的数据驱动因此在某些领域SVM还是无法替代的。
SVM是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大化也使它不同于感知机;SVM还有核技巧,也因此它也是一个非线性分类器。
SVM通过学得模型构建的难度由简至繁可以划分为以下三种:
- 线性可分支持向量机(linear support vector machine in linearly separable case):当训练数据线性可分时,通过硬间隔最大化(hard margin maximization)学习一个线性的分类器,即线性可分支持向量机,也称作硬间隔支持向量机
- 线性支持向量机(linear support vector machine):当训练数据近似线性可分时,通过软间隔最大化(soft margin maximization)也学习一个线性分类器,即线性支持向量机,也称作软间隔支持向量机
- 非线性支持向量机(non-linear support vector machine):当训练数据线性不可分时,通过使用核技巧(kernel trick)及软间隔最大化,学习一个非线性支持向量机
线性可分和线性不可分
由于感知机一文中详细的介绍过线性可分与线性不可分的区别,这里只给出图例便于理解线性支持向量机和非线性支持向量机。
# 线性可分与线性不可分图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
np.random.seed(1)
x1 = np.random.random(20)+1.5
y1 = np.random.random(20)+0.5
x2 = np.random.random(20)+3
y2 = np.random.random(20)+0.5
# 一行二列第一个
plt.subplot(121)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.vlines(2.8, 0, 2, colors="r", linestyles="-", label='$wx+b=0$')
plt.title('线性可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font)
# 一行二列第二个
plt.subplot(122)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.scatter(3.5, 1, s=50, color='b')
plt.scatter(3.6, 1.2, s=50, color='b')
plt.scatter(3.9, 1.3, s=50, color='b')
plt.scatter(3.8, 1.3, s=50, color='b')
plt.scatter(3.7, 0.6, s=50, color='b')
plt.title('线性不可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font)
plt.show()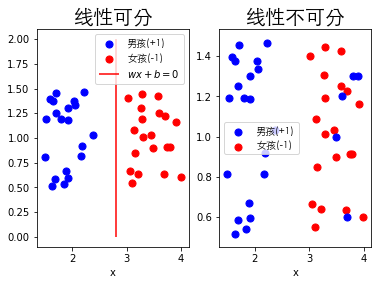
感知机模型和支持向量机
感知机一文中详细讲解过感知机模型的原理,此处不多赘述,简单概括。
在二维空间中,感知机模型试图找到一条直线能够把二元数据分隔开;在高维空间中感知机模型试图找到一个超平面$S$,能够把二元数据隔离开。这个超平面$S$为$\omega{x}+b=0$,在超平面$S$上方的数据定义为$1$,在超平面$S$下方的数据定义为$-1$,即当$\omega{x}>0$,$\hat{y}=+1$;当$\omega{x}<0$,$\hat{y}=-1$。
上张线性可分和线性不可分的区别图第一张图则找到了一条直线能够把二元数据分隔开,但是能够发现事实上可能不只存在一条直线将数据划分为两类,因此再找到这些直线后还需要找到一条最优直线,对于这一点感知机模型使用的策略是让所有误分类点到超平面的距离和最小,即最小化该式
$$
J(\omega)=\sum_{{x_i}\in{M}} {\frac{- y_i(\omega{x_i}+b)}{||\omega||_2}}
$$
上式中可以看出如果$\omega$和$b$成比例的增加,则分子的$\omega$和$b$扩大$n$倍时,分母的L2范数也将扩大$n$倍,也就是说分子和分母有固定的倍数关系,既可以分母$||\omega||2$固定为$1$,然后求分子的最小化作为代价函数,因此给定感知机的目标函数为
$$
J(\omega)=\sum{{x_i}\in{M}} – y_i(\omega{x_i}+b)
$$
既然分子和分母有固定倍数,那么可不可以固定分子,把分母的倒数作为目标函数呢?一定是可以的,固定分子就是支持向量机使用的策略。
线性可分支持向量机详解
确信度
# 确信度图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
x1 = [1, 2, 2.5, 3.2]
x11 = [4.5, 5, 6]
x2 = [1, 1.2, 1.4, 1.5]
x22 = [1.5, 1.3, 1]
plt.scatter(x1, x2, s=50, color='b', label='+1')
plt.scatter(x11, x22, s=50, color='r', label='-1')
plt.vlines(3.5, 0.8, 2, colors="g", linestyles="-", label='$w*x+b=0$')
plt.text(2, 1.3, s='A', fontsize=15, color='k', ha='center')
plt.text(2.5, 1.5, s='B', fontsize=15, color='k', ha='center')
plt.text(3.2, 1.6, s='C', fontsize=15, color='k', ha='center')
plt.legend()
plt.show()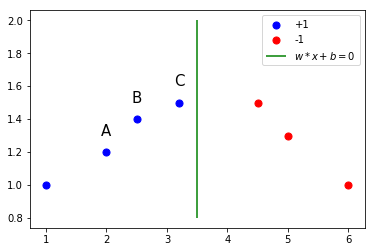
上图有均在超平面正类的A,B,C三个点。因为点A距离超平面远,如果预测为正类点,就比较确信预测时正确的;点C距离超平面较近,如果预测为正类点就不那么确信,因为超平面可能存在着多条,有可能有另一条更优的超平面$\omega{x}+b=0$;点B介于A和C之间,则其预测为正类点的确信度介于A和C之间。
函数间隔和几何间隔
函数间隔
一个点距离超平面的远近可以表示分类预测的确信程度。在超平面固定位$\omega{x}+b=0$的情况下,$|\omega+b=0|$表示点$x$到超平面的相对距离,而$\omega{x}$和$y$是否同号能够判断分类是否正确,所以可以用量$y(\omega{x}+b)$表示分类的正确性和确信度,这就是函数间隔(functional margin)的概念。
给定数据集$T$和超平面$(\omega,b)$,定义超平面$(\omega,b)$关于样本点$(x_i,y_i)$的函数间隔为
$$
\hat{\gamma_i} = y_i(\omega{xi}+b)
$$
对于训练集$T$中$m$个样本点对应的$m$个函数间隔的最小值,就是整个训练集的函数间隔,即
$$
\hat{\gamma} = \underbrace{min}{i=1,\ldots,m}\hat{\gamma_i}
$$
函数间隔并不能正常反应点到超平面的距离,因为只要成比例的改变$\omega$和$b$,超平面却并没有改变,但函数间隔却会变为原来的两倍。
几何间隔
由于函数间隔不能反应点到超平面的距离,因此可以对超平面的法向量$\omega$加上约束条件,例如感知机模型中规范化$||\omega||=1$,使得间隔是确定的。此时的函数间隔将会变成几何间隔(geometric margin)。
对于某一实例$x_i$,其类标记为$y_i$,则改点的几何间隔的定义为
$$
\gamma_i = {\frac{y_i(\omega{xi}+b)}{||\omega||}}
$$
对于训练集$T$中$m$个样本点对应的$m$个函数间隔的最小值,就是整个训练集的几何间隔,即
$$
\gamma = \underbrace{min}{i=1,\ldots,m}\gamma_i
$$
几何间隔才是点到超平面的真正距离,感知机模型用到的距离就是几何间隔。
函数间隔和几何间隔的关系
由函数间隔和几何间隔的定义可知函数间隔和几何间隔有以下的关系
$$
\gamma = {\frac{\hat{\gamma}}{||\omega||}}
$$
支持向量和间隔边界
由于可以找到多个超平面将数据分开导致离超平面近的点不确信度高,因此感知机模型优化时希望所有的点都离超平面远。但是离超平面较远的点已经被正确分类,让它们离超平面更远毫无意义。由于是离超平面近的点容易被误分类,因此次可以让离超平面较近的点尽可能的远离超平面,这样才能提升模型的分类效果,这正是SVM思想的起源。
# 间隔最大化图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn import svm
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
np.random.seed(8) # 保证数据随机的唯一性
# 构造线性可分数据点
array = np.random.randn(20, 2)
X = np.r_[array-[3, 3], array+[3, 3]]
y = [0]*20+[1]*20
# 建立svm模型
clf = svm.SVC(kernel='linear')
clf.fit(X, y)
# 构造等网个方阵
x1_min, x1_max = X[:, 0].min(), X[:, 0].max(),
x2_min, x2_max = X[:, 1].min(), X[:, 1].max(),
x1, x2 = np.meshgrid(np.linspace(x1_min, x1_max),
np.linspace(x2_min, x2_max))
# 得到向量w: w_0x_1+w_1x_2+b=0
w = clf.coef_[0]
# 加1后才可绘制 -1 的等高线 [-1,0,1] + 1 = [0,1,2]
f = w[0]*x1 + w[1]*x2 + clf.intercept_[0] + 1
# 绘制H1,即wx+b=-1
plt.contour(x1, x2, f, [0], colors='k', linestyles='--')
plt.text(2, -4, s='$H_2={\omega}x+b=-1$', fontsize=10, color='r', ha='center')
# 绘制分隔超平面,即wx+b=0
plt.contour(x1, x2, f, [1], colors='k')
plt.text(2.5, -2, s='$\omega{x}+b=0$', fontsize=10, color='r', ha='center')
plt.text(2.5, -2.5, s='分离超平面', fontsize=10,
color='r', ha='center', fontproperties=font)
# 绘制H2,即wx+b=1
plt.contour(x1, x2, f, [2], colors='k', linestyles='--')
plt.text(3, 0, s='$H_1=\omega{x}+b=1$', fontsize=10, color='r', ha='center')
# 绘制数据散点图
plt.scatter(X[0:20, 0], X[0:20, 1], cmap=plt.cm.Paired, marker='x')
plt.text(1, 1.8, s='支持向量', fontsize=10, color='gray',
ha='center', fontproperties=font)
plt.scatter(X[20:40, 0], X[20:40, 1], cmap=plt.cm.Paired, marker='o')
plt.text(-1.5, -0.5, s='支持向量', fontsize=10,
color='gray', ha='center', fontproperties=font)
# plt.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1) # 绘制支持向量点
plt.xlim(x1_min-1, x1_max+1)
plt.ylim(x2_min-1, x2_max+1)
plt.show()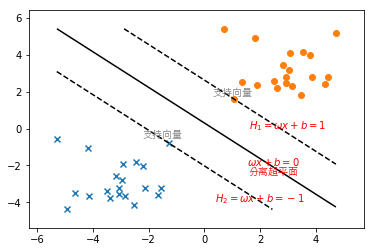
如上图所示,分离超平面为$\omega{x}+b=0$。如果所有的样本不光可以被分离超平面分开,还和分离超平面保持一定的函数间隔(上图的函数间隔为1)。
对于$y_i=1$的正例点,支持向量在超平面$H_1:\omega{x}+b=1$上;对于$y_i=-1$的负例点,支持向量在超平面$H_2:\omega{x}+b=-1$上,即在$H_1$和$H_2$上的点就是支持向量(support vector)。
图中虚线所示的两个平行的超平面$H_1$和$H_2$之间的距离称为间隔(margin),间隔依赖于分离超平面的法向量$\omega$,等于${\frac{2}{||\omega||}}$。
由此可以看出只有支持向量决定分离超平面的位置,即其他实例点对分离超平面没有影响。正式由于支持向量在确定分离超平面的时候起着决定性的作用,所以将这种分类模型称作支持向量机。由于支持向量的个数一般很少,因此支持向量机由很少的重要的样本确定。
线性可分支持向量机目标函数即硬间隔最大化
上一节讲到了SVM的模型其实就是让所有点到分离超平面的距离大于一定的距离,即所有已被分类的点要在各自类别的支持向量的两边,即希望最大化超平面$(\omega,b)$关于训练数据集的几何间隔$\gamma$,这个问题可以表示为下面的约束最优化问题
$$
\begin{align}
& \underbrace{\max}_{\omega,b} \gamma \
& s.t. \quad {\frac{y_i(\omega{x_i}+b)}{||\omega||}}\geq\gamma, \quad i=1,2,\ldots,m
\end{align}
$$
其中$m$表示$m$个样本,$s.t.$表示“subject to(使得…满足…)”,即约束条件,该约束条件指的是超平面$(\omega,b)$关于每个训练样本的集合间隔至少是$\gamma$。
通过函数间隔和几何间隔的关系,可以把上述式子改写成
$$
\begin{align}
& \underbrace{\max}_{\omega,b} {\frac{\hat{\gamma}}{||\omega||}} \
& s.t. \quad y_i(\omega{x_i}+b)\geq\hat{\gamma}, \quad i=1,2,\ldots,m
\end{align}
$$
如果将$\omega$和$b$按比例改变成$\lambda{\omega}$和$\lambda{b}$,此时的函数间隔为$\lambda{\hat{\gamma}}$,即$y_i(\omega{xi}+b)\geq\hat{\gamma}$一定成立,因此函数间隔$\hat{\gamma}$并不影响最优化问题的解,即函数间隔对上面的最优化问题的不等式约束没有影响,因此可以取$\hat{\gamma}=1$。这样最优化问题变成了
$$
\begin{align}
& \underbrace{\max}{\omega,b} {\frac{1}{||\omega||}} \
& s.t. \quad y_i(\omega{x_i}+b)\geq1, \quad i=1,2,\ldots,m
\end{align}
$$
可以看出这个最优化问题和感知机的优化问题是不同的,感知机是固定分母优化分子,而SVM在加上了支持向量的同时固定分子优化分母。
注意最大化${\frac{1}{||\omega||}}$即最小化$||\omega|||$,考虑到二范数的性质,因此加个平方,即最小化${\frac{1}{2}}{||\omega||}^2$,则可以得到线性可分支持向量机的最优化问题,即目标函数的最优化问题,即硬间隔最大化为
$$
\begin{align}
& \underbrace{\min}_{\omega,b} {\frac{1}{2}}{||\omega||}^2 \
& s.t. \quad y_i(\omega{x_i}+b)\geq1, \quad i=1,2,\ldots,m
\end{align}
$$
其中${\frac{1}{2}}{||\omega||}^2$为目标函数
凸最优化问题
由于目标函数的最优化问题中的目标函数是连续可微的凸函数,约束函数是仿射函数(注:如果$f(x)=a*x+b$,则$f(x)$称为仿射函数),则该问题是一个凸最优化问题。又由于目标函数是二次函数,则该凸最优化问题变成了凸二次规划问题。
如果求出了目标函数最优化问题中的解$\omega^,b^$,则可以得到最大间隔分离超平面${\omega^}^Tx+b^=0$和分类决策函数$f(x)=sign({\omega^}^Tx+b^)$(注:sign函数即符号函数,类似于Sigmoid函数的图形),即线性可分支持向量机模型。
线性可分支持向量机的最优化问题
根据凸优化理论,可以通过拉格朗日函数把优化有约束的目标函数转化为优化无约束的目标函数。既应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解,进而把线性可分支持向量机的最优化问题作为原始最优化问题,有时也称该方法为线性可分支持向量机的对偶算法(dual algorithm)。
首先引进拉格朗日乘子(Lagrange multiplier)$\alphai\geq0, \quad i=1,2,\ldots,m$,然后构建拉格朗日函数(Lagrange function)
$$
L(\omega,b,\alpha) = {\frac{1}{2}}{||\omega||}^2-\sum{i=1}^m\alpha_iy_i(\omega{xi}+b)+\sum{i=1}^m\alpha_i
$$
其中$\alpha=(\alpha_1,\alpha_2,\ldots,\alpha_m)^T$为拉格朗日乘子向量。
因此优化问题变成
$$
\underbrace{\min}{\omega,b} \underbrace{\max}{\alphai\geq0} L(\omega,b,\alpha)
$$
由于这个优化问题满足Karush-Kuhn-Tucker(KKT)条件,既可以通过拉格朗日对偶性把上述的优化问题转化为等价的对偶问题,即优化目标变成
$$
\underbrace{\max}{\alphai\geq0} \underbrace{\min}{\omega,b} L(\omega,b,\alpha)
$$
从上式中,则可以先求优化函数对于$\omega$和$b$的极小值,接着再求拉格朗日乘子$\alpha$的极大值。
- 求$\underbrace{\min}_{\omega,b}L(\omega,b,\alpha)$
通过对$\omega$和$b$分别求偏导并令其等于$0$即可得$L(\omega,b,a)$的极小值
$$
\begin{align}
& \nabla\omega{L}(\omega,b,\alpha) = \omega – \sum{i=1}^m\alpha_iy_ix_i = 0 \
& \nablabL(\omega,b,\alpha) = -\sum{i=1}^m\alpha_iyi =0
\end{align}
$$
得
$$
\begin{align}
& \omega = \sum{i=1}^m \alpha_iy_ixi \
& \sum{i=1}^m \alpha_iy_i = 0
\end{align}
$$
从$\omega$和$b$求偏导等于$0$的结果可以看出$\omega$和$\alpha$的关系,只要后面能接着求出优化函数极大化对应的$\alpha$,即可以求出$\omega$,由于上述上式已经没有了$b$,因此最后的$b$可能有多个。
将上述式子即可代入拉格朗日函数(注:由于推导过程十分复杂,对接下来的讲解无意,此处不给出推导过程,有兴趣的同学可以自行尝试,其中会用到范数的定义即${||\omega||}^2=\omega\omega$以及乘法运算法则$(a+b+c+\ldots)(a+b+c+\ldots)=aa+ab+ac+ba+bb+bc+\ldots$以及一些矩阵的运算),即得
$$
\begin{align}
\underbrace{\min}{\omega,b}L(\omega,b,\alpha) & = {\frac{1}{2}}\sum{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j(x_ixj) – \sum{i=1}^m\alpha_iyi((\sum{i=1}^m\alpha_jy_jx_j)xi+b)+\sum{i=1}^m\alphai \
& = – {\frac{1}{2}}\sum{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j(x_ixj)+\sum{i=1}^m\alphai
\end{align}
$$
从上式可以看出通过对$\omega$和$b$极小化以后,优化函数只剩下$\alpha$做参数,只要能够极大化$\underbrace{\min}{\omega,b}L(\omega,b,\alpha)$即可求出相应的$\alpha$,进而求出$\omega$和$b$。
- 求$\underbrace{\min}_{\omega,b}L(\omega,b,\alpha)$对$\alpha$的极大化
对$\underbrace{\min}{\omega,b}L(\omega,b,\alpha)$求极大化的数学表达式为
$$
\begin{align}
& \underbrace{\max}{\alpha} – {\frac{1}{2}} \sum{i=1}^m\sum{j=1}^m\alpha_i\alpha_jy_iy_j(x_ixj)+\sum{i=1}^m\alphai \
& s.t. \sum{i=1}^m \alpha_iy_i =0 \
& \quad \alphai\geq0, \quad i=1,2,\ldots,m
\end{align}
$$
通过去掉负号,即可转化为等价的极小问题如下
$$
\begin{align}
& \underbrace{\min}{\alpha} {\frac{1}{2}} \sum{i=1}^m\sum{j=1}^m\alpha_i\alpha_jy_iy_j(x_ixj) – \sum{i=1}^m\alphai \
& s.t. \sum{i=1}^m \alpha_iy_i =0 \
& \quad \alphai\geq0, \quad i=1,2,\ldots,m
\end{align}
$$
一般通过SMO算法求出上式极小化对应的$\alpha$,假设通过SMO算法得到了该$\alpha$值记作$\alpha^*$,即可根据$\omega=\sum{i=1}^m\alpha_iy_ixi$求得原始最优化问题的解$\omega^$为
$$
\omega^ = \sum{i=1}^m {\alpha_i}^ y_ixi
$$
由于对$b$求偏导得$\sum{i=1}^m \alpha_iy_i = 0$,因此有多少个支持向量则有多少个$b^$,并且这些$b^$都可以作为最终的结果,但是对于严格的线性可分支持向量机,$b^$的值是唯一的,即这里所有的$b^*$都是一样的。
根据KKT条件中的对偶互补条件${\alpha_j}^(y_j(\omega^x_j+b)-1)=0$,如果${\alpha_j}^>0$,则有$y_j(\omega^x_j+b^)-1=0$即点都在支持向量机上,否则如果${\alpha_j}^=0$,则有$y_j(\omega^x_j+b^)-1\geq0$即已被正确分类。由于对于任意支持向量$(x_j,y_j)$都有$y_j(\omega^x_j+b^)-1=0$即$y_j(\omega^x_j+b^)y_j-y_i=0$,代入$\omega^$即可得$b^$为
$$
b^ = yj – \sum{i=1}^m{\alpha_i}^y_i(x_ix_j)
$$
线性可分支持向量机流程
输入
有$m$个样本的线性可分训练集$T={(x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m)}$,其中$x_i$为$n$维特征向量,$y_i$为二元输出即值为$1$或者$-1$。
输出
分离超平面的参数$w^$和$b^$以及分类决策函数
流程
- 构造约束优化问题为
$$
\begin{align}
& \underbrace{\min}{\alpha} {\frac{1}{2}} \sum{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j(x_ixj) – \sum{i=1}^m\alphai \
& s.t. \sum{i=1}^m \alpha_iy_i =0 \
& \quad \alpha_i\geq0, \quad i=1,2,\ldots,m
\end{align}
$$ - 使用SMO算法求出上式最小时对应的$\alpha^*$
- 计算$w^$为
$$
w^ = \sum_{i=1}^m \alpha^*y_ix_i
$$ - 找到一个支持向量,即满足$\alpha_s>0$对应的样本$(x_s,y_s)$,计算$b^$为
$$
b^ = yj – \sum{i=1}^m \alpha^*y_i(x_ix_j)
$$ - 求得分离超平面为
$$
w^x+b^ = 0
$$ - 求得分类决策函数为
$$
f(x) = sign(w^x+b^)
$$
在线性可分支持向量机中可以发现$w^$和$b^$只依赖于训练数据中对应的$\alpha^>0$的样本点$(x_j,y_j)$,而其他样本点对$w^$和$b^$没有影响,而$\alpha^>0$的样本点即为支持向量。
由KKT互补条件可得对于$\alpha^>0$样本点$(x_j,y_j)$有$y_j(w^x_j+b)-1=0$,并且间隔边界$H_1$和$H_2$分别为$w^x_j+b^=1$和$w^x_j+b^=-1$,即支持向量一定在间隔边界上。
线性可分支持向量机优缺点
优点
- 决策函数的计算取决于支持向量的数量,而不是样本空间的维数
- 增删非支持向量对模型没有影响
缺点
- 无法处理异常点
- 不支持线性不可分数据的分类
- 属于二分类分类器,如果需要多分类需要使用OVR等方法
小结
支持向量机是基于感知机模型演化而来的,解决了感知机模型可能会得到多个分类直线的问题,由于使用了硬间隔最大化支持向量机的目标函数只和支持向量的位置有关,大大降低了计算量。
线性可分支持向量机是支持向量机最原始的形式,由于使用了硬间隔最大化,因此无法做到对异常值和非线性可分数据的处理,此处不多赘述,让我们看他的升级版——线性支持向量机。