前言
完全分布式就是把Hadoop核心组件分开部署到不同的服务器节点上运行。
通常,建议HDFS和YARN以单独的用户身份运行。在大多数安装中,HDFS进程以“hdfs”执行。YARN通常使用“yarn”帐户。
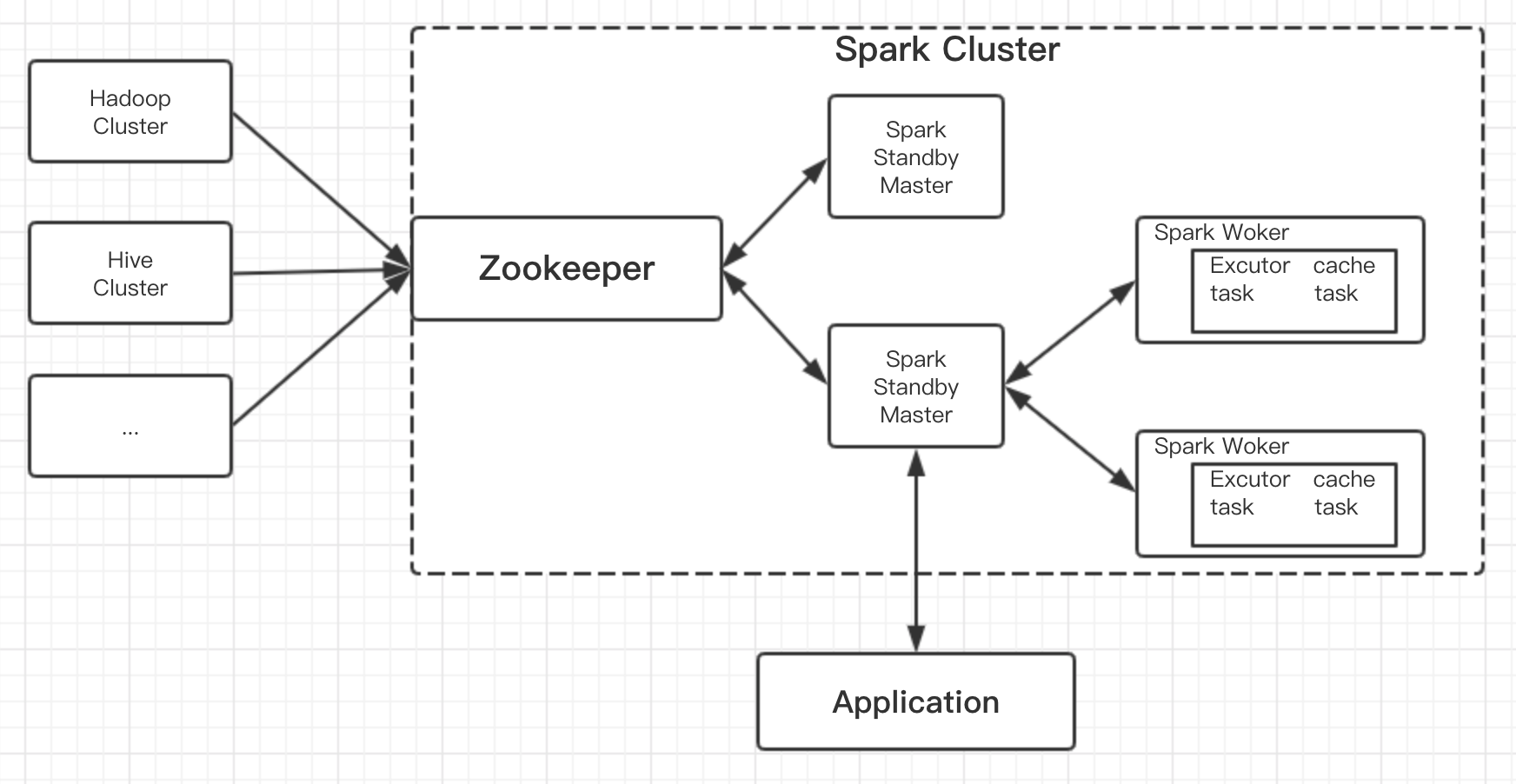
hadoopHA集群的工作机制如下图:
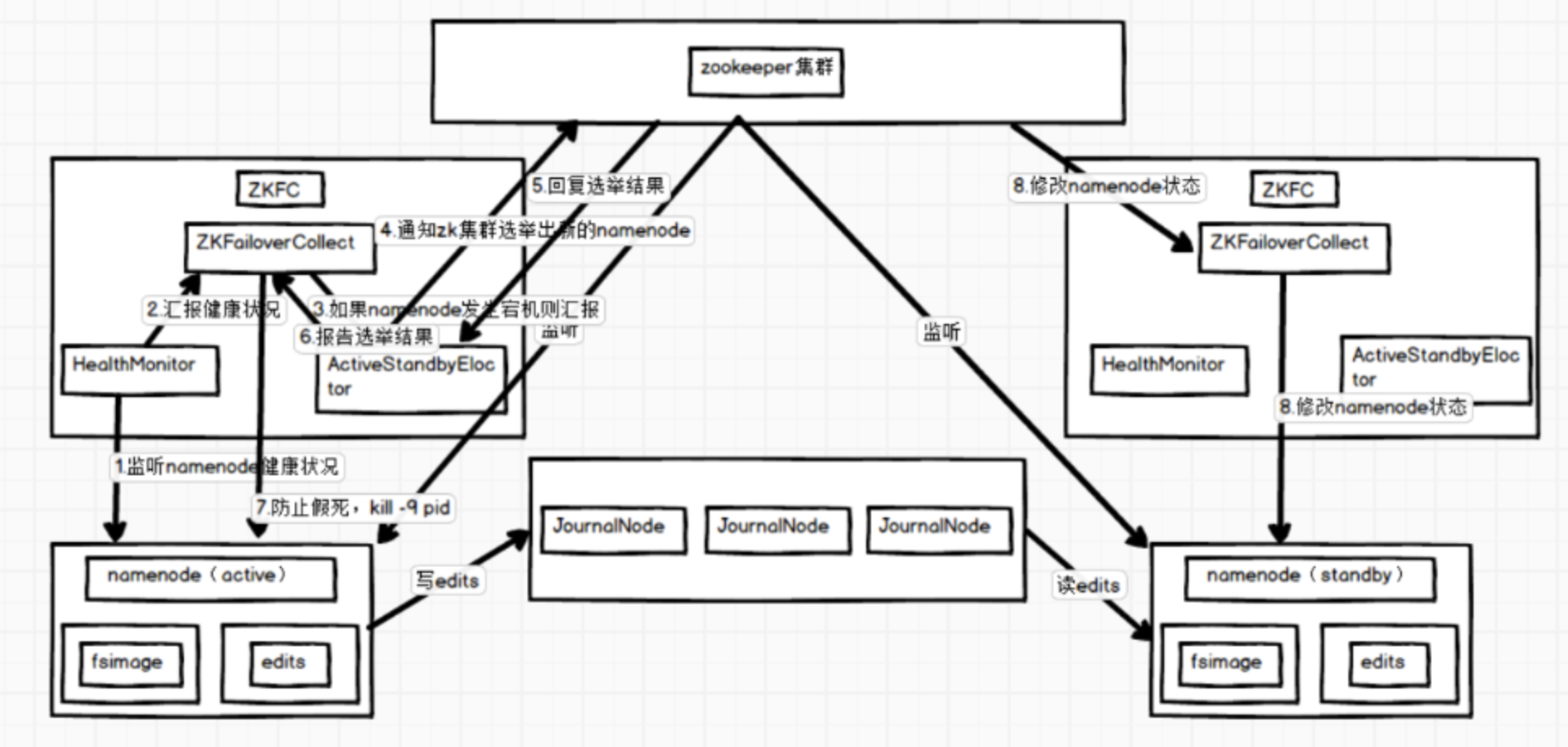
Hadoop HA集群总体上可以分为三部分:NameNode集群、JournalNode集群和Zookeeper集群。NameNode在某一时刻只有一个处于活跃状态,其他的都处于standby状态;JournalNode负责把edits文件传到standby的NameNode上;Zookeeper负责监控NameNode宕机情况,ZKFC(ZookeeperFailoverController)是专门监控NameNode健康的。
为了同步NameNode的元数据一致,有专门的JournalNode来同步元数据文件,活跃的NameNode的edits文件会写入journalnode集群,其他standby的结点会去读取journalnode上的edits文件,以此来同步自身的元数据。
详细过程如下:
1、ZKFC的HealthyMonitor是监控NameNode的进程,是专门监控NameNode将康情况的进程。
2、HealthyMonitor会定时向ZKFC进程报告NameNode情况。
3、当HealthyMonitor出现汇报了NameNode,ZKFC就会向AcitveStandbyEloctor报告。
4、AcitveStandbyEloctor接到NameNode宕机报告就会通知zk集群选举出新的NameNode。
5、zk集群经过内部选举,返回一个standby的NameNode给AcitveStandbyEloctor。
6、AcitveStandbyEloctor想ZKFC报告选举结果。
7、ZKFC为了防止是网络原因导致NameNode假死,就会结束NameNode进程。
8、zk集群就会通知另一个ZKFC要求它修改它监控的NameNode的进程为活跃节点。图中涉及到的角色介绍
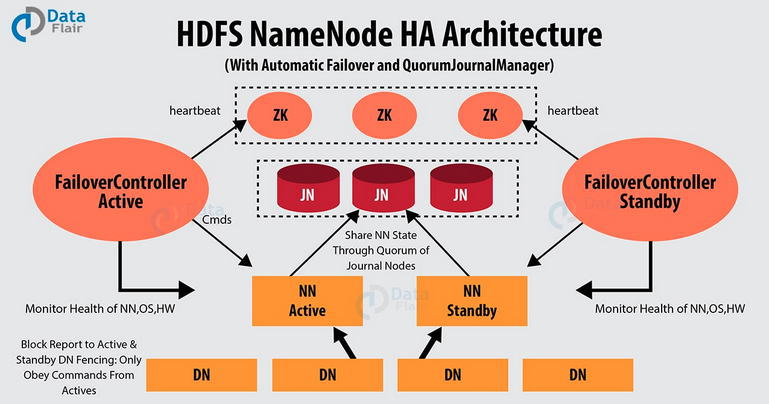
在Hadoop 1.x的时候,NameNode存在单点故障问题。如果NameNode进程或者所在的机器有故障,会导致整个集群不可用,直到NameNode进程重启或者所在的机器恢复。在hadoop 2.x之后,增加了NameNode的HA机制。即在一个HDFS集群中运行两个NameNode节点,一个是Active状态的,一个是Standby状态的。当Active状态的NameNode挂掉后,Standby状态的NameNode会切换成Active状态。
NameNode的HA架构如上图
涉及到几个主要角色如下:
Active NameNode: 与Standby NameNode形成互备,只有处于Active状态的NameNode节点才能对外提供读写服务。
Standby NameNode: 承接原来SecondaryNameNode的checkpoint功能。Standby NameNode从JN拉取edit log,合并到自己的fsimage上。在Active NameNode故障时,Standby会切换成Active状态。
JournalNode: 必须奇数个节点(3,5,7…),至少3个节点。当有N个JN时,可以允许(N-1)/2个NameNode发生故障。Active NameNode发送edit log到JN的绝大部分节点上。
ZKFailoverController: ZKFC作为独立的进程运行,对NameNode的主备切换进行总体控制。每个运行NameNode的机器上,都需要同时运行一个ZKFC。ZKFC定期监测它本机的NameNode的健康状态,会与Zookeeper之间维护一个session,当本机的NameNode是Active状态时,会把某个znode“加锁”(创建znode)。如果session过期,这个znode会被删除。当其他ZKFC看到这个znode不存在,会去请求“加锁”(创建znode),如果成功“加锁”,也就是所谓的赢得了选举(won the election),它所在机器上的NameNode成为了Active状态。当然,NameNode也支持不依赖Zookeeper的手动主备切换。
DataNode: 同时向Active NameNode和Standby NameNode上报数据块位置信息和心跳包。搭建分为四个阶段,每一个是环境准备,第二个是Zookeeper集群的搭建,第三是Hadoop集群的搭建,第四是Spark集群的搭建。
一、准备
1、软件及版本
centOS-7.3.1611
jdk1.8.0_131
scala-2.11.11.tgz(可选)
zookeeper-3.4.10.tar.gz
hadoop-2.10.1.tar.gz
spark-2.4.8-bin-hadoop2.7.tgz软件包下载:
链接: https://pan.baidu.com/s/1WS10UlQ6sN_W5ZX5k1cYMA 提取码: 854q
2、服务器
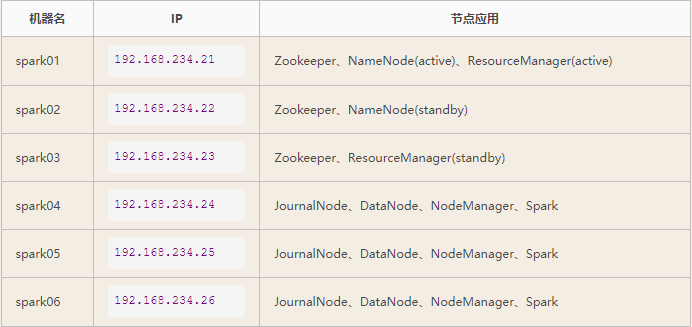
这里将使用六台服务器进行搭建。分别命名spark01、spark02、spark03、spark04、spark05、spark06。
机器数为6台,但因为分布式算法的需要,集群通常部署在奇数台服务器上,所有主机共用上述6台机器,如下角色划分
1、Zookeeper集群分配三台。
2、Hadoop分配需要分开说:
2.1、HDFS:两个主节点,三个从节点,5台。
2.2、JN集群:三台
2.3、Yarn集群:两个主节点,三个从节点,5台。3、Spark集群分配三台。
将以上各个集群的节点合并,具体分配如下:
服务器设置
每台服务器都要进行如下的配置。
1、关闭防火墙与selinux
systemctl stop firewalld
systemctl disable firewalld
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
setenforce 02、配置主机名
hostnamectl set-hostname xxx
配置hosts
vim /etc/hosts # 填入以下内容
127.0.0.1 localhost
::1 localhost
192.168.234.21 spark01
192.168.234.22 spark02
192.168.234.23 spark03
192.168.234.24 spark04
192.168.234.25 spark05
192.168.234.26 spark06配置好此文件之后可以通过远程命令将配置好的hosts文件scp到其他5台节点上,执行命令如下:
scp /etc/hosts spark02: /etc/hosts
scp /etc/hosts spark03: /etc/hosts
scp /etc/hosts spark04: /etc/hosts
scp /etc/hosts spark05: /etc/hosts
scp /etc/hosts spark06: /etc/hosts配置免密登录
集群中所有主机都要互相进行免密登录,包括自己和自己。
生成密钥:
ssh-keygen
发送公钥:
ssh-copy-id root@spark01
此时在远程主机的/root/.ssh/authorized_keys文件中保存了公钥,在known_hosts中保存了已知主机信息,当再次访问的时候就不需要输入密码了。
通过以下命令远程连接,检验是否可以不需密码连接:
ssh spark01
记得免密登录一定要给本机发送。
此次集群数量,互相发送免密登录的次数为36次。注意注意注意:做完密钥登陆后,一定要每台主机ssh root@来登陆一遍,把该输入的yes都输入完毕,保证ssh可以直接连接上,不在需要交互,否则后续hadoop脚本启服务时会出现问题
安装Jdk
1、将jdk安装包上传、解压安装包,并更名,命令如下:
tar -zxvf jdk-8u65-linux-x64.tar.gz
mv jdk1.8.0_65 jdk1.82、修改/etc/profile, 在文件行尾加入以下内容后保存退出。
JAVA_HOME=/home/software/jdk1.8/
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH安装Scala
1、上传解压scala-2.11.0.tgz,并更名,命令如下:
tar -zxvf scala-2.11.0.tgz
mv scala-2.11.0 scala2.112、修改/etc/profile,配置如下:

注:上图将Hadoop的环境变量也一起配置了,下面也有Hadoop的环境变量配置。
3、重新加载profile使配置生效:
source /etc/profileps:java、python、scala介绍
下面只是说说spark研发团队为什么选择scala,不是对比语言好坏。
第一:java与scala
1、当涉及到大数据Spark项目场景时,Java就不太适合,与Python和Scala相比,Java太冗长了,一行scala可能需要10行java代码。
2、当大数据项目,Scala支持Scala-shell,这样可以更容易地进行原型设计,并帮助初学者轻松学习Spark,而无需全面的开发周期。但是Java不支持交互式的shell功能。
第二:Python与Scala
虽然两者都具有简洁的语法,两者都是面向对象加功能,两者都有活跃的社区。
1、Python通常比Scala慢,Scala会提供更好的性能。
2、Scala是static typed. 错误在编译阶段就抛出,它使在大型项目中开发过程更容易。
3、Scala基于JVM,因为Spark是基于Hadoop的文件系统HDFS的。 Python与Hadoop服务交互非常糟糕,因此开发人员必须使用第三方库(如hadoopy)。 Scala通过Java中的Hadoop API来与Hadoop进行交互。 这就是为什么在Scala中编写本机Hadoop应用程序非常简单。
总之:选择哪种语言,要看作者的个人想法着重点,当然想“玩”spark,python也是非常好的。
Spark专注于数据的"transformation"和"mapping"的概念,这非常适合于完美支持像scala这样的概念的功能编程语言。 另外scala在JVM上运行,这使得更容易集成hadoop、YARN等框架。二、Zookeeper完全分布式搭建
为什么要部署ZooKeeper
可以通过ZooKKeeper完成Hadoop NameNode的监控,发生故障时做到自动切换,从而达到高可用
部署在spark01、spark02、spark03上即可
三、Hadoop2.0 HA集群搭建步骤
此示例以spark01节点服务器为示例。
3.1、安装
直接解压Hadoop压缩包即可。