HDFS Namenode 高可用
在 Hadoop 2.0.0 之前,一个集群只有一个Namenode,这将面临单点故障问题。如果 Namenode 机器挂掉了,整个集群就用不了了。只有重启 Namenode ,才能恢复集群。另外正常计划维护集群的时候,还必须先停用整个集群,这样没办法达到 7 * 24小时可用状态。Hadoop 2.0 及之后版本增加了 Namenode 高可用机制,下面详细介绍。
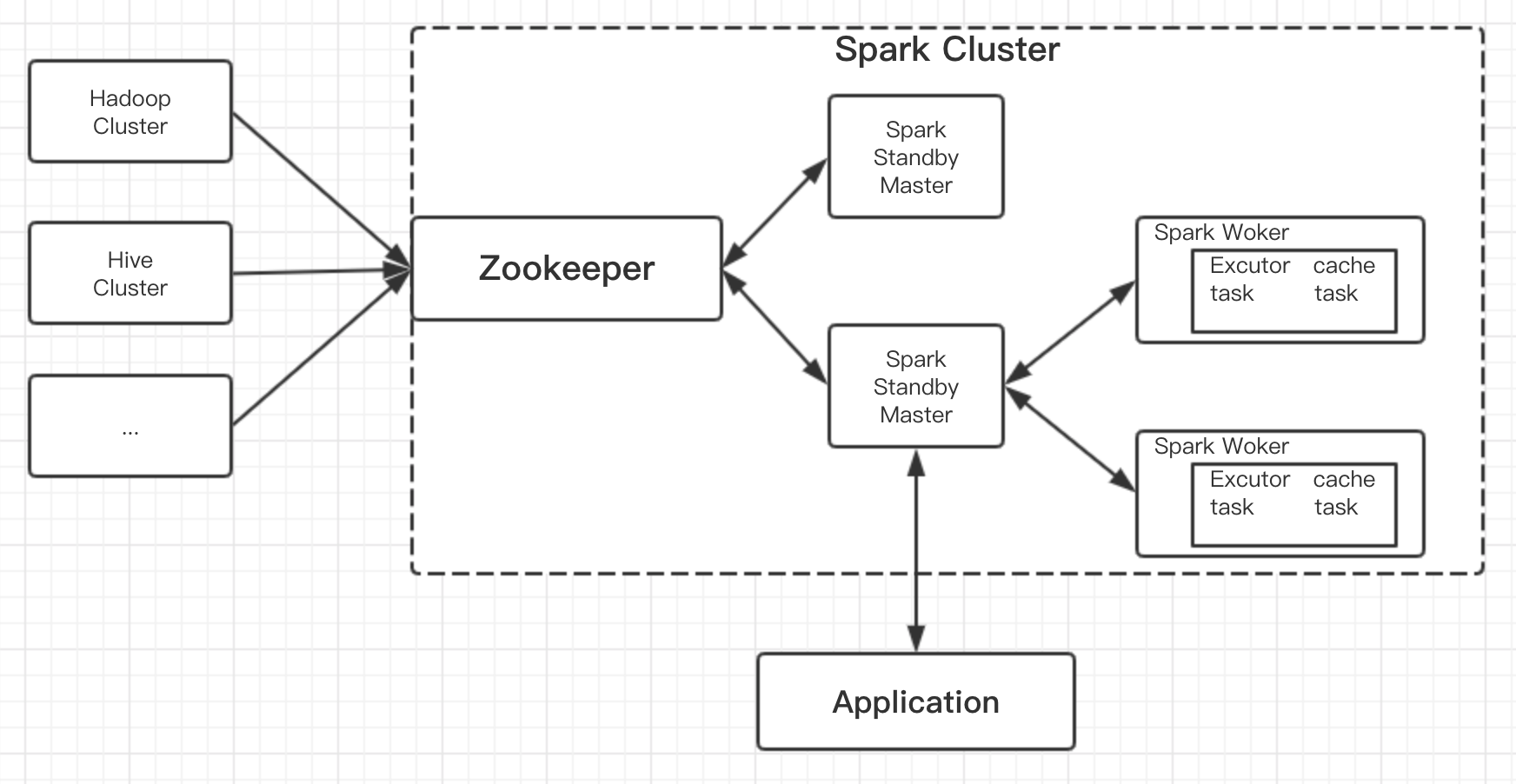
Hadoop Namenode 高可用架构
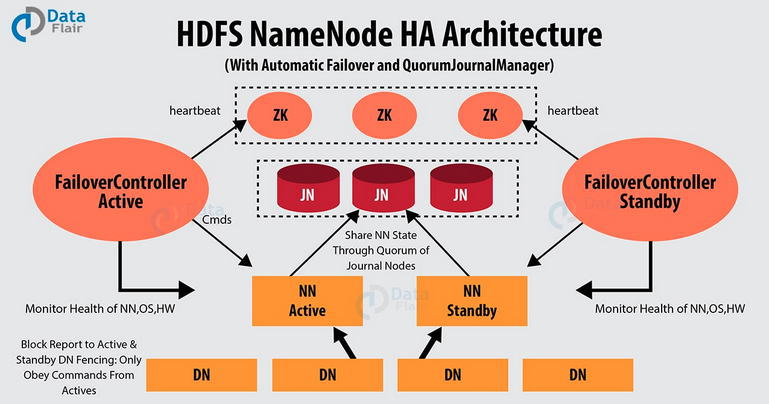
Hadoop 2.0 克服了 Namenode 单点故障问题,即在一个集群中有2个 Namenode 节点,一个是活动的Namenode节点(Active Namenode),即主节点,一个是备用 Namenode(Passive Namenode),即备用节点,而且支持热备份和故障切换。
活动 Namenode:负责处理集群中所有客户端请求。
备用 Namenode:备用节点,拥有和活动的 Namenode 一样的元数据。在活动 Namenode 失效后,会接管它的工作。
活动 Namenode 和备用 Namenode 之间是如何同步数据的呢?即他们是怎么保持一致性的,主要有下面几点:
活动和备用 Namenode 两者总是同步的,例如,他们存储着一样的元数据,这可以把集群恢复到系统奔溃时的状态。而且基于此还能实现自动故障切换。
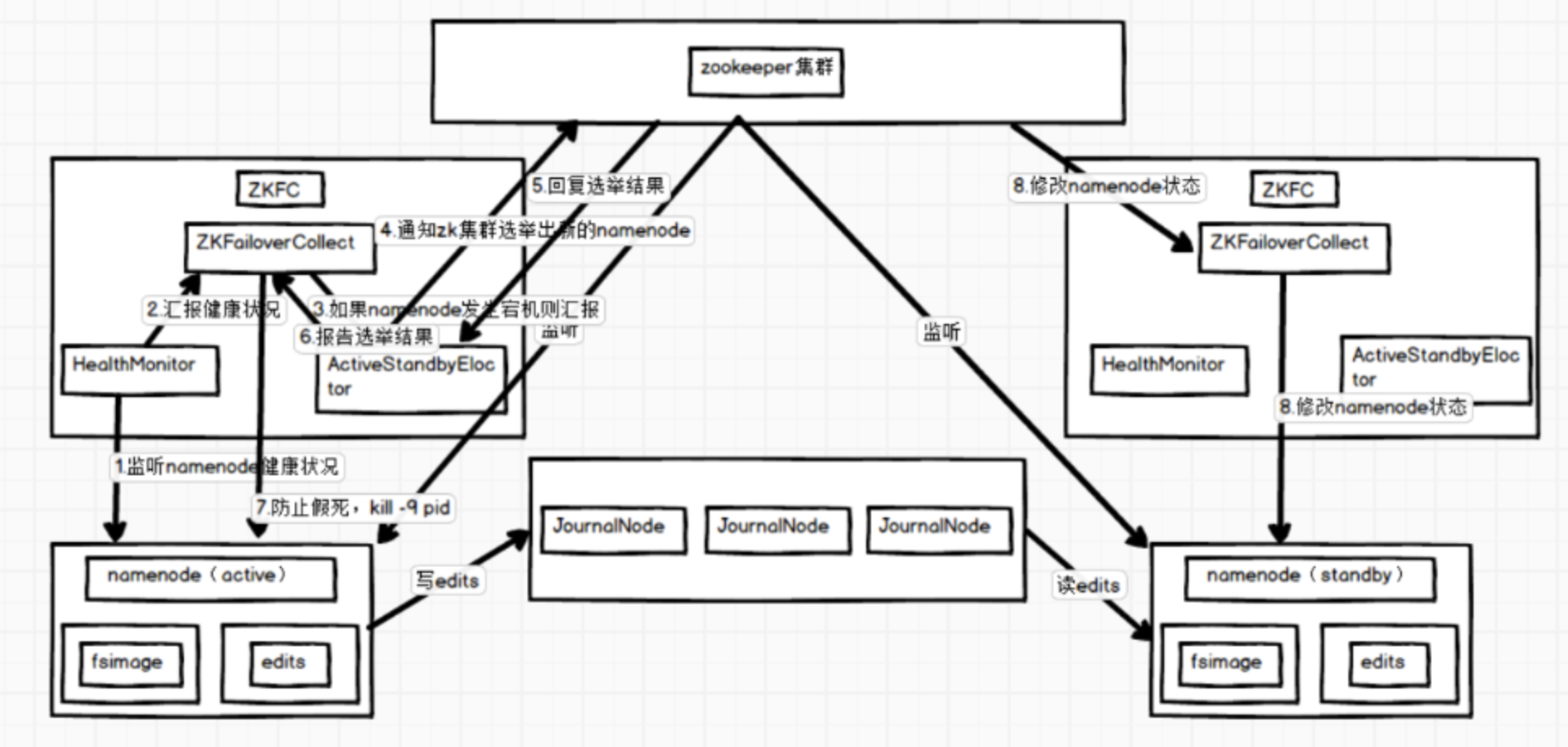
同一时间,集群只能有一个活动的 Namenode 节点,否则,两个 Namenode 会导致数据发生错乱并且无法恢复。我们把这种情况称为“脑裂”现象,即一个集群被分成两个小集群,并且两边都认为自己是唯一活动的集群。Zookeeper 社区对这种问题的解决方法叫做 fencing,中文翻译为隔离,也就是想办法把旧的 活动 NameNode 隔离起来,使它不能正常对外提供服务,使集群始终只有一个活动的 Namenode。了解完 Hadoop 高可用架构之后,让我们来看一下 Hadoop Namenode 高可用是怎么实现的。
Namenode 高可用的实现
这里主要介绍通过隔离(fencing)和Quorum Journal Manager(QJM)共享存储实现的 HDFS 高可用。
一 隔离(Fencing)
隔离(Fencing)是为了防止脑裂,就是保证在任何时候HDFS只有一个Active NN,主要包括三个方面:
共享存储fencing:确保只有一个NN可以写入edits。QJM中每一个JournalNode中均有一个epochnumber,匹配epochnumber的QJM才有权限更新 JN。当 Namenode 由 standby 状态切换成 active 状态时,会重新生成一个 epochnumber,并更新 JN 中的 epochnumber,以至于以前的 Active Namenode 中的QJM 中的 epoch number 和 JN 的 epochnumber 不匹配,故而原 Active Namenode上的 QJM 没法往 JN 中写入数据(后面会介绍源码),即形成了 fencing。
客户端f encing:确保只有一个 Namenode 可以响应客户端的请求。
DataNode fencing:确保只有一个 Namenode 可以向 Datanode 下发命令,譬如删除块,复制块,等等。QJM 的 Fencing 方案只能让原来的 Active Namenode 失去对 JN 的写权限,但是原来的 Active Namenode 还是可以响应客户端的请求,对 Datanode 进行读。对客户端和 DataNode 的 fence 是通过配置 dfs.ha.fencing.methods 实现的。
Hadoop 公共库中有两种Fencing实现:sshfence、shell
sshfence:ssh到原Active NN上,使用fuser结束进程(通过tcp端口号定位进程 pid,该方法比 jps 命令更准确)。
shell:即执行一个用户事先定义的shell命令(脚本)完成隔离。二 QJM共享存储
Qurom Journal Manager(QJM)是一个基于 Paxos 算法实现的 HDFS 元数据共享存储的方案。QJM 的基本原理就是用 2N+1 台 JournalNode 存储 EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据不会丢失。这个算法所能容忍的是最多有 N 台机器挂掉,如果多于 N 台挂掉,这个算法就失效了。这个原理是基于 Paxos 算法的。
用QJM的方式来实现HA的主要好处有:
不需要配置额外的高共享存储,这样对于基于商用硬件的云计算数据中心来说,降低了复杂度和维护成本;
不在需要单独配置 fencing 实现,因为 QJM 本身内置了 fencing 的功能;
不存在单点故障问题;
系统鲁棒性的程度是可配置的( QJM 基于 Paxos 算法,所以如果配置 2N+1 台 JournalNode 组成的集群,能容忍最多 N 台机器挂掉);
QJM 中存储日志的 JournalNode 不会因为其中一台的延迟而影响整体的延迟,而且也不会因为 JournalNode 的数量增多而影响性能(因为 Namenode 向 JournalNode 发送日志是并行的)。