一、plabook结构说明
一个playbook就好比是你编排的一场大戏
这场大戏由于很多小片段构成,一个片段就称之为一个play
一个play的本质就是为一组主机关联上多个task任务,对应的就是tasks字段,tasks下面有很多小task任务
一个小的task任务本质就是对ansible某一个模块的调度
把上面的内容按照你想要的顺序组织在一起,就称之为编排,像排练一场演出一场电影一样。
流程大致如下
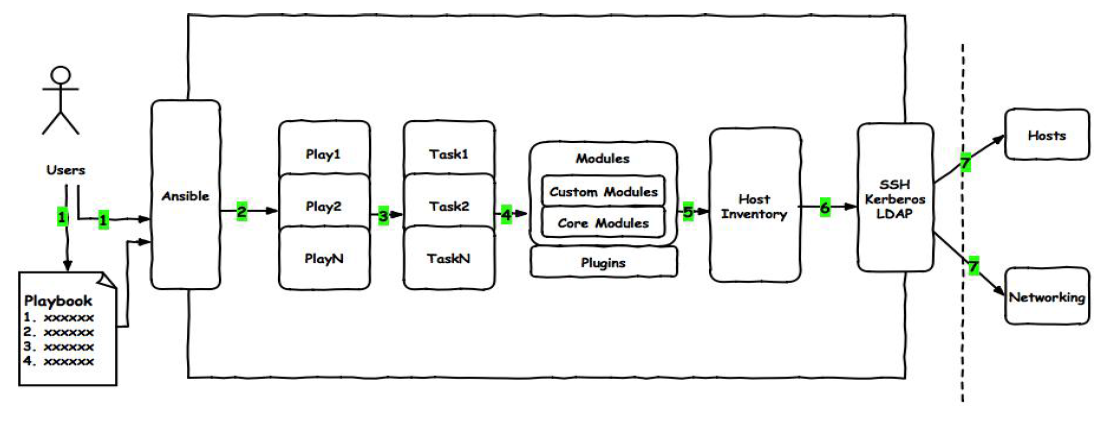
plabook由四部分构成
1、Target section: 定义远程主机、用户、连接信息
2、Variable section: 定义playbook运行时需要使用的变量
3、Task section: 定义将要在远程主机上执行的任务列表
4、Handler section: 定义task执行完成以后需要触发的任务
参考我们的主机配置信息,开展后续讲解
[root@lb ansible]# cat /etc/ansible/hosts
[group1]
192.168.71.12 ansible_ssh_pass='1'
192.168.71.13 ansible_ssh_pass='1'
[group2]
192.168.71.12 ansible_ssh_pass='1'
192.168.71.13 ansible_ssh_pass='1'
192.168.71.14 ansible_ssh_pass='1'
[group3]
192.168.71.12 ansible_ssh_pass='1'
192.168.71.13 ansible_ssh_pass='1'
192.168.71.15 ansible_ssh_pass='1'
[group4]
192.168.71.13 ansible_ssh_pass='1'
[group5]
192.168.71.16 ansible_ssh_pass='1'二、Target Section
1、hosts:即inentory中的定义主机与主机组,你在ad-doc模式里学习到的host-pattern,在这里也完全适用
- name: 创建目录
hosts: group1:&group2
tasks:
- name: 测试
file:
path: /tmp/xxx
state: directory2、用户部分如果未定义,则默认使用/etc/ansible/ansible.cfg中用户相关配置
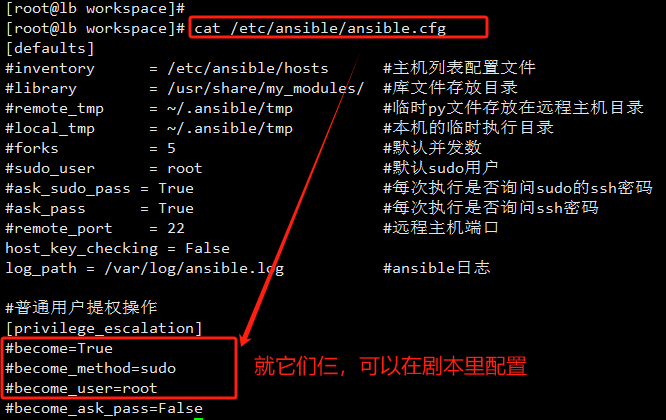
鉴于安全性和审计原因,Ansible可能需要先以非特权用户身份连接远程主机,然后再通过特权升级获得root用户身份的管理权限。
这可以在Ansible配置文件的[privilege_escalation]部分中设置,代表升级特权
# /etc/ansible/ansible.cfg # 每一行末尾不要加注释,会无法识别 [defaults] # 1、指定主机清单文件 inventory = /etc/ansible/hosts # 2、以什么用户远程被管理主机 remote_user = egon666 [privilege_escalation] # 3、是否需要切换用户 become = true # 4、如何切换用户 become_method = sudo # 5、切换成什么用户 become_user = root # 6、sudo是否需要输入密码 become_ask_pass = False # 7、建议:制作ssh秘钥登录,这样就不用输入密码了,并且在目标主机中设置sudo以root用户身份运行命令而不必输入密码,非常方便且安全
在剧本中自己配置的话,优先级更高
- hosts: group5
name: /etc/hosts is up to date
remote_user: egon666
become: true
become_method: sudo
become_user: root
tasks:
- name: www.egon.com in /etc/hosts
lineinfile:
path: /etc/hosts
line: '192.168.71.200 www.egon.com'
state: present
一、执行剧本前,目标主机必须
#1、创建用户并设置好密码
useradd egon666
passwd egon666 # 设置好密码
# 2、添加sudo收取
cat /etc/sudoers里添加
egon666 ALL=(ALL) NOPASSWD:ALL
二、然后在控制机上做秘钥登录
ssh-keygen
ssh-copy-id -i egon666@目标主机的ip地址
三、Variable section
四、Task section
一个plabook文件中可以包含很多play,每个play都可以选中自己的主机然后执行其下的tasks,如下playbook中定义了两个play
[root@lb workspace]# cat 1.yaml
- hosts: group1
name: "我是playbook下的第一个play"
tasks:
- name: 命令1
shell: "echo 111 > /tmp/1.txt"
- name: 命令2会出错
shell: "cat /xxxxx > /tmp/2.txt"
- name: 命令3
shell: "echo 333 > /tmp/3.txt"
- hosts: group5
name: "我是playbook下的第二个play"
tasks:
- name: 命令4
shell: "echo 444 > /tmp/4.txt"
- name: 命令5会出错
shell: "cat /xxxxx > /tmp/5.txt"
- name: 命令6
shell: "echo 666 > /tmp/6.txt"执行的时候,会先执行完第一个play后再执行第二个play
执行每个play的时候
1、会对所有hosts选中的主机,执行tasks下的命令1
2、然后对所有hosts选中的主机,执行tasks下的命令2
3、最后对所有hosts选中的主机,执行tasks下的命令3
如果中途发生错误,则整个playbook都会终止掉,有时后你想忽略错误,继续后续执行,那就需要用到忽略错误,有两种方式实现
1、在命令末尾加|| /bin/true让其返回的状态码永远为0,此时ansible并不将任何报错信息打印出来,(该方案对command模块就不适用了,因为要用到特殊符号,所以下一个方案更通用,本方案了解即可)
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand || /bin/true2、使用ignore_errors来忽略错误信息,此时ansible会将报错信息打印出来
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand
ignore_errors: True你可以用上面的案例进行测试,当你忽略错误后,后续的task,已经下一个play都会得到正常的执行
补充:
1、即便你不忽略错误,你也要知道一点,由于playbook的幂等性,playbook可以被反复执行,所以即使发生了错误,在修复错误后,再执行一次也不会有问题
2、ignore_errors: True 通常会跟上一小节介绍的变量register一起使用,在忽略错误后,拿到错误结果,在后续的逻辑中进行判断处理
- hosts: web_group
tasks:
- name: Check Httpd Server
#使用命令检查服务启动状态时,如果服务没有启动则会得到错误结果,剧本会停止运行
command: systemctl is-active httpd
#配置忽略错误可以继续执行剧本
ignore_errors: yes
register: check_httpd
- name: debug outprint
debug:
msg: "{{ check_httpd }}"
- name: Httpd Restart
service:
name: httpd
state: restarted
when: check_httpd.rc == 0五、Handler section
5.1、什么是handlers?
handler也是一种task,只不过该task默认并不会执行,只有在被通知时才会执行,所以又可称之为触发器
什么时候handler收到通知呢?
只有在 playbook 中的某个任务改变了系统状态后,才会触发其notify指定的 handler
"系统状态改变"是指任务执行的结果导致了实际的改变(如配置改变、文件内容变化、服务状态变化),是通过比较模块执行前后的状态来判断的
在执行任务的过程中,如果模块发现它的操作导致了状态的变化(例如,执行前和执行后的状态不同),
则 Ansible 会将这个任务标记为 "changed",如果仅仅是查看或获取状态信息的操作,则不会被视为 "changed"。简单示例
[root@m01 project]# cat nginx.yml
- hosts: nginx
tasks:
- name: Config Nginx Server
copy:
src: /etc/nginx/nginx.conf
dest: /etc/nginx/
notify: restart_nginx # 名字与handlers中定义的某个name一致
handlers:
- name: restart_nginx
systemd:
name: nginx
state: restarted5.2、什么场景用handler
主要在以下场景中使用:
1、配置改变后需要重启服务:这可能是使用 handler 的最常见场景。例如,如果你修改了某个服务的配置文件,你可能需要重启该服务以使新的配置生效。你可以在修改配置文件的任务中使用 notify 指令触发一个 handler,这个 handler 的任务是重启相应的服务。
2、在多个任务完成后执行一次操作:如果你有多个任务都可能触发相同的操作,但你只希望在所有任务完成后执行一次,那么你可以使用 handler。无论有多少任务通知了同一处理器,该处理器只会在所有任务完成之后执行一次。
3、在长期运行的任务完成后执行操作:如果你有一个需要长时间运行的任务,当这个任务完成后,你可能需要执行一些清理工作,例如删除临时文件。你可以将删除临时文件的任务作为一个 handler,当长期运行的任务完成时触发这个 handler。
这也是 handler 的一个关键特征:无论它被通知多少次,每次 playbook 运行,每个 handler 只会执行一次,并且只有在所有任务都执行完毕后,handler 才会执行。
5.3、配置触发器
每个play的tasks全部执行完后才会触发1次handler的执行,然后执行下一个play
[root@lb workspace]# cat test.yaml
#第一个play
- hosts: group5
tasks:
- name: 命令111111
copy:
src: /etc/hosts
dest: /tmp/1.txt
notify: say_ok
- name: 命令222222
shell: "sleep 5"
notify: say_ok
handlers:
- name: say_ok
shell: "echo ok >> /tmp/play1.log"
#第二个play
- hosts: group5
tasks:
- name: 命令4444444
copy:
src: /etc/hosts
dest: /tmp/2.txt
notify: say_hello
- name: 命令5555555
shell: "sleep 5"
notify: say_hello
handlers:
- name: say_hello
shell: "echo hello >> /tmp/play2.log"
5.4、触发器使用注意事项
1.无论多少个task通知了相同的handlers,handlers仅会在所有tasks结束后运行一次。
2.Handlers只有在其所在的任务被执行时,才会被运行;如果一个任务中定义了notify调用Handlers,但是由于条件判断等原因,该任务未被执行,那么Handlers同样不会被执行。
3.Handlers只会在每一个play的末尾运行一次;如果想在一个playbook中间运行Handlers,则需要使用meta模块来实现。例如: -meta: flush_handlers。
4.如果一个play在运行到调用Handlers的语句之前失败了,那么这个Handlers将不会被执行。我们可以使用meta模块的--force-handlers选项来强制执行Handlers,即使Handlers所在的play中途运行失败也能执行。
5.不能使用handlers替代tasks5.5、具体应用示例
应用示例1
[root@m01 project]# cat php.yml
- hosts: web_group
tasks:
- name: Tar php Package
unarchive:
src: /project/package/php.tar.gz
dest: /tmp/
- name: Check php Install Status
shell: "rpm -qa | grep php | wc -l"
register: get_php_instll_status
- name: Install php Server
shell: "yum localinstall -y /tmp/*.rpm"
when: get_php_instll_status.stdout_lines == 0
- name: Config php Server
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
with_items:
- { src: "/project/conf/php.ini", dest: "/etc" }
- { src: "/project/conf/www.conf", dest: "/etc/php-fpm.d/" }
notify: restart_php
- name: Start php Server
systemd:
name: php-fpm
state: started
handlers:
- name: restart_php
systemd:
name: php-fpm
state: restarted应用示例2
tasks:
- name: template configuration file
template:
src: template.j2
dest: /etc/foo.conf
notify:
- restart memcached
- restart apache
- name: start memcached
service:
name: memcached
state: started
- name: start apache
service
name: httpd
state: started
handlers:
- name: restart memcached
service:
name: memcached
state: restarted
- name: restart apache
service:
name: httpd
state: restarted
5.6 强制handler执行
如果tasks下某个task出错了,并且你也没用用||/bin/true或者ignore_errors的方式把错误忽略掉,那么程序崩溃,handler自然不会执行,
想要强制执行需要设置:force_handlers: yes
[root@lb workspace]# cat 1.yaml
- hosts: group1
name: "我是playbook下的第一个play"
force_handlers: True
tasks:
- name: 命令1
shell: "echo 111 > /tmp/1.txt"
notify: test
- name: 命令2会出错
shell: "cat /xxxxx > /tmp/2.txt"
# ignore_errors: True
- name: 命令3
shell: "echo 333 > /tmp/3.txt"
handlers:
- name: test
shell: "echo test > /tmp/ttttttt.txt"
- hosts: group5
name: "我是playbook下的第二个play"
tasks:
- name: 命令4
shell: "echo 444 > /tmp/4.txt"
- name: 命令5会出错
shell: "cat /xxxxx > /tmp/5.txt"
- name: 命令6
shell: "echo 666 > /tmp/6.txt"