一 储备知识
-
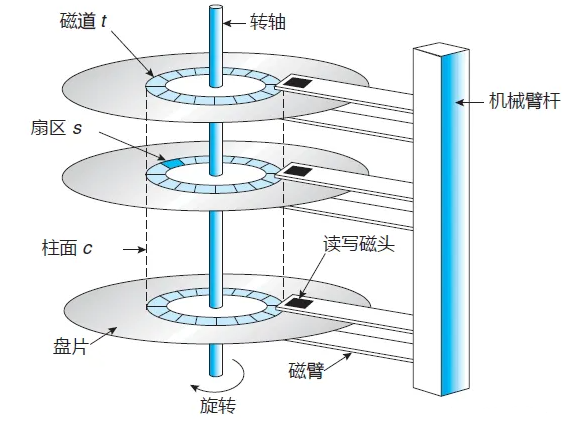
1、磁盘的结构

-
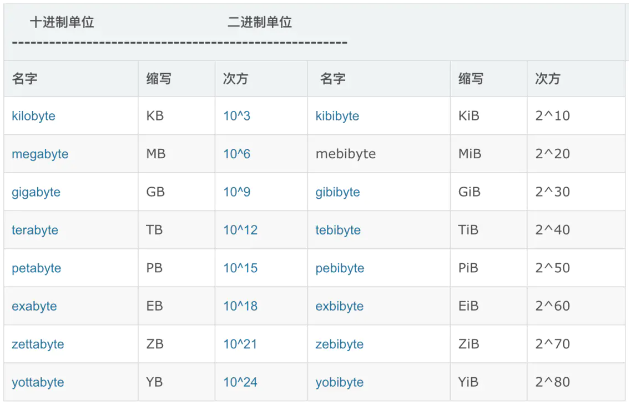
2、MB和MIB的区别
MB等单位以10为底数的指数。
MiB是以2为底数的指数。
如:1KB=10^3=1000, 1MB=10^6=1000000=1000KB,1GB=10^9=1000000000=1000MB
而 1KiB=2^10=1024,1MiB=2^20=1048576=1024KiB
换算单位如图:
-
3、机械磁盘一次I/O耗费的时间由三部分构成
(1)对于磁盘来说一个完整的IO操作是这样进行的:当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带读写磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻址(Seeking),对应消耗的时间被称为寻址时间(Seek Time); (2)但是找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正上方的之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Delay); (3)接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后一次IO操作也就完成了。总结:
一次磁盘I/O耗费的时间 = 平均寻道 + 平均延迟 + 传输时间(数据从磁盘读入内存的时间,这个是本地传输,速度很快,耗费时间几乎可以忽略不计) -
4、衡量磁盘性能的两个常见的指标
(1)IOPS :英文全称 Input/Output Operations Per Second ,翻译过来就是每秒钟磁盘读或写的次数,即一秒内,磁盘完成了多少次读/写操作。这个数值越大,当然也就表示性能越好。
(2)BPS:是指每秒钟磁盘的I/O流量,即一秒内,磁盘写入加上读出的数据总量。,一般以 MB/s 为单位。这个BPS有时候也被称为Throughput吞吐量,或者带宽Bandwidth,简称 BWIOPS与吞吐量直接的关系,可以简单的大概理解为:吞吐量 = 数据块大小 *IOPS
从上面的简略公式中可以看出来,如果IOPS固定,那么数据块越大,吞吐量自然越大
最大IOPS的理论计算方法如下。买来一块磁盘我们可以根据其转速大概预估一下它可能达到的理论IOPS值(1)常见磁盘平均物理寻道时间为: 7200转/分的STAT硬盘平均物理寻道时间是9ms 10000转/分的STAT硬盘平均物理寻道时间是6ms 15000转/分的SAS硬盘平均物理寻道时间是4ms (2)常见硬盘的旋转延迟时间为: 7200 rpm的磁盘平均旋转延迟大约为转半圈耗费的时间(1/7200/60s) / 2 = 4.17ms 10000 rpm的磁盘平均旋转延迟大约为转半圈耗费的时间(1/10000/60s) / 2 = 3ms, 15000 rpm的磁盘其平均旋转延迟约为转半圈耗费的时间(1/15000/60s) / 2 = 2ms。 (3) 最大IOPS的理论计算方法 IOPS = 1000 ms/ (寻道时间 + 旋转延迟)。可以忽略数据传输时间。 7200 rpm的磁盘IOPS = 1000 / (9 + 4.17) = 76 IOPS 10000 rpm的磁盘IOPS = 1000 / (6+ 3) = 111 IOPS 15000 rpm的磁盘IOPS = 1000 / (4 + 2) = 166 IOPS最大IOPS的实际计算方法如下。上面的理论值终究不会特别准确,后期我们还是用专门的测试工具比如fio,参考实际的读/写量与完成时间来进行计算,简单举例如下
示例1:例1:完成10000个1KB的I/O请求,用时10秒 在10秒内完成了10000个I/O请求,那么1秒内完成了1000个,所以IOPS=1000 在10秒内完成了总共10000 * 1KB大小的数据量,那么Throught(吞吐量) = 1MB/s示例1:
完成1个10MB的I/O请求,用时0.2秒 IOPS=5 Throught(吞吐量)=50MB/s -
5、磁盘的读写单位:block块与扇区
文件系统不是一个扇区一个扇区的来读数据,那样太慢了,所以有了block(块)的概念,它是一个块一个块的读取的.block才是文件存取的最小单位.
磁盘的一次io的最小读写单位是一个扇区,默认512Bytes,操作系统的文件系统如果按照一个扇区一个扇区的读写,那就太慢了,于是有了block块的概念,block块才是文件系统的最小存取单位
一个block块中扇区的个数依文件系统而不同,如一个block有8个扇区,那一个block块的大小为4K.[root@test05 ~]# stat / |grep -i 'io' # 查看默认一个block块大小为4096个字节,即8个扇区 大小:224 块:0 IO 块:4096 目录 -
6、程序使用的块地址与磁盘的物理地址是两个概念
为了方便理解下面的顺序访问与随机访问的概念先来储备两个知识:
PBA(physical block address物理块地址):物理地址是数据在磁盘上的实际地址。
LBA(logical block address 逻辑块地址):逻辑地址是程序中认识的块地址,编号顺序递增,一般逻辑和物理地址会有一个对应关系(例如:对于硬盘来说LBA与PBA就是一一对应的)
-
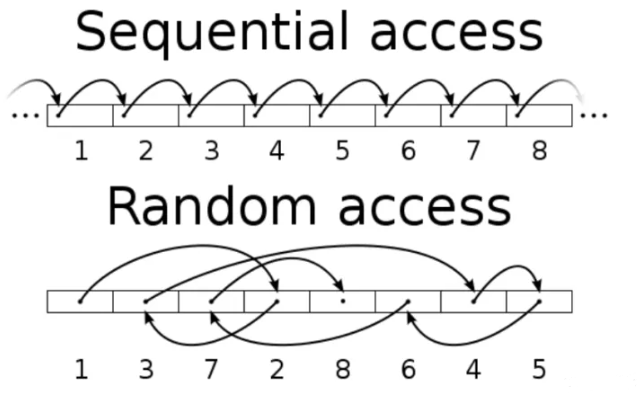
7、磁盘的顺序访问和随机访问是怎么定义的呢?
如果一次IO操作起始的逻辑块地址logical block address (LBA)紧挨着上一次IO操作的终止 LBA,就是顺序访问,否则就是随机访问
只有顺序写才能保证顺序读
(1)随机IO:当读取第一个block时,要经历寻道,旋转延迟,传输三个步骤才能读取完这个block的数据.而对于下一个block,如果它在磁盘的某个位置,访问它会同样经历寻道,旋转,延时,传输才能读取完这个block的数据, 我们把这种方式的IO叫做随机IO.
(2)顺序IO:但是如果这个block的起始扇区刚好在我刚才访问的block的后面,磁头就能立刻遇到.不需等待,直接传输.这种IO就叫顺序IO.举例:
把磁盘看成一个光盘,上边有一个磁头用来写东西,就像钢笔头一样,要在一个位置写东西,需要先将磁头移动到那个位置,这个操作叫seek(旋转+寻道),接下来就是将数据顺序写下去(write)。写完数据之后磁头自动向后移动,如果继续挨着写就不需要 seek 了。
举个例子,以一个汉字为单位,那么顺序写一句话 “小孩儿你好呀”,只需要将磁头 seek 一次到“小”要写的位置,然后 write “小”,接下来直接把“孩儿你好呀” 一个个 write 到后边就可以了,这些字在磁盘上都存在了一起。随机写就是把这几个字分开存,互相不挨着。那么共需要 6 次 seek,6次 write。顺序写总是比随机写要好的,因为随机写多了 5 次 seek 的时间。
一个 HDD 的 seek 耗时是 10ms,吞吐率是 100MB/s,也就是每秒能 write 100MB 的数据。那么以 1KB 为单位,纯 write 这 1KB 的数据只需要 10us ,是seek 的 1/1000。 可以看到 seek 是很不友好的。
由于HDD 可以覆盖写,所以 LBA 和 PBA 是一一对应的,连续的逻辑地址也对应了连续的物理地址,所以有随机访问和顺序访问的区别。 -
8、磁盘上的记录是顺序存储还是随机的存储
老式的磁带是典型的顺序存储设备,特点是存储信息量大,但读取和写入数据都要求必须是从头一路下去,不能想读哪个数据就读哪个。
而现在的磁盘本身是随机存取的存储设备,它不会像老式磁带那样强制要求你记录数据必须按顺序存储(存储特点是其为每个存储单元都有一个唯一的编号,就门牌号码,这样想存取哪个数据都可以,只要按编号找就是了),但是我们是可以控制写数据时按顺序写入的,对于大型文件,按顺序存储记录会提高存取效率,因为降低了寻道的时间 -
9、那如何实现顺序写呢?
即如何实现一个文件的连续分配呢?详见:https://egonlin.com/?p=7663第3.1小节
对于磁盘来说,默认都是随机写,如果你想控制磁盘实现顺序写入,怎么做呢?
与随机读写不同的是,连续分配的方式要求每个文件在磁盘上占有一组连续的块,即顺序读写是优先分配一块文件空间,然后后续内容追加到对应空间内以此保证顺序。连续分配的优缺点
- 优点:
支持顺序访问和直接访问(或者叫随即访问),当然了,连续分配的文件在顺序访问时的速度是最快的,因为通常情况下读取某个磁盘块时,需要移动磁头进行寻道,如果访问的两个磁盘块相隔越远,寻道时间久会越长,而如果是连续分配的,读的时候也采用顺序读,就会降低很多寻道时间,速度自然是快 - 缺点:
- (1)、存储空间利用率低,会产生磁盘碎片
- (2)、不方便文件拓展
在使用顺序IO进行文件读写时候,需要知道上次写入的地方,所以需要维护一个索引或者轮询获得一个没有写入位置。
切记:只有顺序写才能保证顺序读,顺序读写省去了寻道的开销,通常读写效率必随机读写会高
示例:
假设存在一个文件尺寸为1024个字节的文件,如果按照顺序存取原则的话,我们需要优先申请一块文件空间,然后只能采用类似于FileStream.read()或者FileReader.readLine()的方式来一段一段,或者一行一行地读取,从而保证顺序。
而RandomAccessFile类的核心价值在于RandomAccessFile.seek()方法,通过这个方法,可以任意地指定当前存取文件的指针位置。随时调用RandomAccessFile类的getFilePionter()方法,获取文件指针当前距离文件起始位置的偏移量。
小结:在日常项目开发中在设计存储时,一定要考虑顺序和随机,优化其性能达到最高。例如,当前大多数数据库使用的都是传统的机械磁盘,因此,整个系统设计要尽可能顺序I/O,避免昂贵的寻道时间和旋转延迟的开销.
了解了顺序访问之后,你可以再看看https://egonlin.com/?p=7663,了解一下文件的三种分配方式,顺序访问、随机访问时啥意思你就都懂了
- 优点:
-
10、机械盘和固态盘的区别
机械盘:数据是存储的扇区的,读写是依靠磁头的摆动寻址的。顺序读写主要时间花费在了传输时间,随机读写需要多次寻道和旋转延迟。
固态盘:是由控制单元和固态存储单元(DRAM或FLASH芯片)组成,存储单元负责存储数据,控制单元负责读取、写入数据。
由于固态硬盘没有普通硬盘的机械结构,也不存在机械硬盘的寻道问题。
一般情况下SAS机械硬盘主要是看顺序读写性能,SSD固态盘主要看随机读写性能。 -
11、随机读写与顺序读写的性能说明
(1)、性能比较-机械硬盘
机械硬盘在顺序读写场景下有相当出色的性能表现,但一遇到随机读写性能则直线下降。
顺序读是随机读性能的400倍以上。顺序读能达到84MB/S
顺序写是随机读性能的100倍以上。顺序写性能能达到79M/S
原因:是因为机械硬盘采用传统的磁头探针结构,随机读写时需要频繁寻道,也就需要磁头和探针频繁的转动,而机械结构的磁头和探针的位置调整是十分费时的,这就严重影响到硬盘的寻址速度,进而影响到随机写入速度。
(2)、性能比较-固态硬盘
顺序读:220.7MB/s。随机读:24.654MB/s。
顺序写:77.2MB/s。随机写:68.910MB/s。
总结:对于固态硬盘,顺序读的速度仍然能达到随机读的10倍左右。但是随机写还是顺序写,差别不大。 -
12、什么场景下关注随机访问?什么场景关注顺序访问?
(1)随机读写频繁的应用,如小文件存储(图片)、OLTP数据库、邮件服务器,关注随机读写性能,IOPS是关键衡量指标。
(2)顺序读写频繁的应用,传输大量连续数据,如电视台的视频编辑,视频点播VOD(Video On Demand),关注连续读写性能。数据吞吐量是关键衡量指标。 -
13、读/写文件的完整流程
(1)读文件
用户程序通过编程语言提供的读取文件api发起对某个文件读取。此时程序切换到内核态,用户程序处于阻塞状态。由于读取的内容还不在内核缓冲区中,导致触发OS缺页中断异常。然后由OS负责发起对磁盘文件的数据读取。读取到数据后,先存放在OS内核的主存空间,叫PageCache。然后OS再将数据拷贝一份至用户进程空间的主存ByteBuffer中。此时程序由内核态切换至用户态继续运行程序。程序将ByteBuffer中的内容读取到本地变量中,即完成文件数据读取工作。
(2)写文件
用户程序通过编程语言提供的写入文件api发起对某个文件写入磁盘。此时程序切换到内核态用户程序处于阻塞状态,由OS负责发起对磁盘文件的数据写入。用户写入数据后,并不是直接写到磁盘的,而是先写到ByteBuffer中,然后再提交到PageCache中。最后由操作系统决定何时写入磁盘。数据写入PageCache中后,此时程序由内核态切换至用户态继续运行。
用户程序将数据写入内核的PageCache缓冲区后,即认为写入成功了。程序由内核态切换回用于态,可以继续后续的工作了。PageCache中的数据最终写入磁盘是由操作系统异步提交至磁盘的。一般是定时或PageCache满了的时候写入。如果用户程序通过调用flush方法强制写入,则操作系统也会服从这个命令。立即将数据写入磁盘然后由内核态切换回用户态继续运行程序。但是这样做会损失性能,但可以确切的知道数据是否已经写入磁盘了。





二、测试硬盘读写
方式一(了解即可):基于dd命令,dd命令可以通用,基本上×NIX系统上都有安装,但不够专业,也没有考虑到缓存和物理读的区分,测试的数据也是仅作参考,不能算是权威,平时可以使用来对磁盘的读写速度作一个简单的评估
# 输出到空/dev/null,只测试读
[root@aliyun ~]# time dd if=/dev/sda of=/dev/null bs=8k count=10000
# 测试根分区磁盘的写,写一个a.txt,如果要测试实际速度 还要在末尾加上 oflag=direct测到的才是真实的IO速度
[root@aliyun ~]# time dd if=/dev/zero of=/a.txt bs=8k count=10000 oflag=direct方式二(推荐使用):fio
FIO是测试IOPS的非常好的工具,用来对磁盘进行压力测试和验证。磁盘IO是检查磁盘性能的重要指标,可以按照负载情况分成照顺序读写,随机读写两大类。FIO是一个可以产生很多线程或进程并执行用户指定的特定类型I/O操作的工具,FIO的典型用途是编写和模拟的I/O负载匹配的作业文件。也就是说FIO 是一个多线程io生成工具,可以生成多种IO模式,用来测试磁盘设备的性能(也包含文件系统:如针对网络文件系统 NFS 的IO测试)。
另外还有GFIO则是FIO的图形监测工具,它提供了图形界面的参数配置,和性能监测图像。
fio在github上的坐标:https://github.com/axboe/fio 。
安装
yum install fio libaio-devel -y #后者为异步io引擎依赖包强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强调:千万不能在系统所在的分区测试硬盘性能
强烈建议不要使用-filename参数指定某个要测试的裸设备(硬盘或分区),例如,你指定了-filename=/dev/sda,而/dev/sda是系统的根分区所在,在你测试读时没问题,但是你测试write操作时,会写入数据到/dev/sda里,这会破坏系统分区,而导致系统崩溃。
fio -name=mytest -direct=1 -rw=read -bs=4k -size=5G -ioengine=libaio -iodepth=64 -thread -numjob=1 -filename=/dev/sda -runtime=60若一定要测试系统分区较为安全的方法是:在根目录下创建一个空目录,在测试命令中使用directory参数指定该目录,而不使用-filename参数。
cd / # 切到根分区下,创建目录来测试
mkdir test/
fio -directory=/test/ ……
参数说明
-name=mytest 指定本次测试任务名,自定义即可
-filename: 指定文件(设备)的名称。可以通过冒号分割同时指定多个文件,如filename=/dev/sda:/dev/sdb。
-directory: 设置filename的路径前缀。在后面的基准测试中,采用这种方式来指定设备。
-direct: bool类型,如果设置成true或1,表示不使用io buffer,代表从内存直接写入磁盘,测试过程绕过OS自带的buffer,使测试磁盘的结果更真实,即采用O_DIECT的方式,规避buffer写缓冲区带来的影响(实际测试的时候发现即便设置-direct=1也会使使用buffer,但确实设置为1与设置为0的写速度,前者更快,难道是设置direct=1之后会写入buffer然后立即刷入磁盘以此来模拟O_DIECT的方式?这个有待进一步研究)
-rw=read 测试顺序读
-rw=randread 测试随机读
-rw=write 测试顺序写
-rw=randwrite 测试随机写
-rw=randrw 测试混合随机读写模式
-ioengine: I/O引擎,现在fio支持19种ioengine(sync,mmap,libaio,posixaio,SG v3,splice,null,network,syslet,guasi,solarisaio等)。默认值是sync同步阻塞I/O,libaio代表异步读取,提交完io请求后可以继续提交下一个
iodepth=16 则代表总共提交了多少个io请求,结合上一个参数的异步提交,此处的io提交是提交完一个立即提交下一个
-bs=4k -size=5G 代表单次IO块大小为4k,总共读取5G数据
-thread=1 代表使用pthread_create创建线程,另一种是使用fork创建进程。进程的开销比线程要大,一般都采用thread测试。
-numjob=1 代表启动一个任务来执行上述的IO测试,一个任务代表一个线程
-runtime=60 代表测试多长时间,测试时间为60秒,如果不写则一直将5g文件分4k每次写完为止。
group_reporting: 当同时指定了numjobs了时,输出结果按组显示,汇总每个进程的信息。
bsrange=512-2048 同上-bs=4k类似,此处为指定数据块的大小范围
Block Devices(RBD) 无需使用内核RBD驱动程序(rbd.ko)。该参数包含很多ioengine,如:libhdfs/rdma等
rwmixwrite=30 在混合读写的模式下,写占30%
此外
lockmem=1g 只使用1g内存进行测试。
zero_buffers 用0初始化系统buffer。
nrfiles=8 每个进程生成文件的数量。磁盘读写常用测试点,需要储备知识:顺序IO与随即IO:https://egonlin.com/?p=7230
1. Read=100% Ramdon=100% rw=randread (100%随机读)
2. Read=100% Sequence=100% rw=read (100%顺序读)
3. Write=100% Sequence=100% rw=write (100%顺序写)
4. Write=100% Ramdon=100% rw=randwrite (100%随机写)
5. Read=70% Sequence=100% rw=rw, rwmixread=70, rwmixwrite=30
(70%顺序读,30%顺序写)
6. Read=70% Ramdon=100% rw=randrw, rwmixread=70, rwmixwrite=30
(70%随机读,30%随机写)
示例
100%随机,100%读, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
100%随机,100%写, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
100%顺序,100%读 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
100%顺序,100%写 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
100%随机,70%读,30%写 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4kFIO测试实例:测试读
[root@docker sda]# fio -ioengine=libaio -bs=4k -direct=1 -thread -numjobs=1 -rw=read -filename=/dev/sda -name="BS 4KB read test" -iodepth=16 -runtime=60
BS 4KB read test: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
fio-3.7
Starting 1 thread
Jobs: 1 (f=1): [R(1)][100.0%][r=89.3MiB/s,w=0KiB/s][r=22.9k,w=0 IOPS][eta 00m:00s]
BS 4KB read test: (groupid=0, jobs=1): err= 0: pid=18557: Thu Apr 11 13:08:11 2019
read: IOPS=22.7k, BW=88.5MiB/s (92.8MB/s)(5313MiB/60001msec) # IOPS:每秒的io次数,越大性能越好。BW:bandwidth即带宽,妹妹
slat (nsec): min=901, max=168330, avg=6932.34, stdev=1348.82 #提交延迟
clat (usec): min=90, max=63760, avg=698.08, stdev=240.83 #完成延迟
lat (usec): min=97, max=63762, avg=705.17, stdev=240.81 #响应时间
clat percentiles (usec):
| 1.00th=[ 619], 5.00th=[ 627], 10.00th=[ 627], 20.00th=[ 635],
| 30.00th=[ 635], 40.00th=[ 685], 50.00th=[ 717], 60.00th=[ 725],
| 70.00th=[ 725], 80.00th=[ 725], 90.00th=[ 734], 95.00th=[ 816],
| 99.00th=[ 1004], 99.50th=[ 1020], 99.90th=[ 1057], 99.95th=[ 1057],
| 99.99th=[ 1860]
bw ( KiB/s): min=62144, max=91552, per=100.00%, avg=90669.02, stdev=3533.77, samples=120
iops : min=15536, max=22888, avg=22667.27, stdev=883.44, samples=120
lat (usec) : 100=0.01%, 250=0.01%, 500=0.01%, 750=93.85%, 1000=5.14%
lat (msec) : 2=0.99%, 4=0.01%, 10=0.01%, 50=0.01%, 100=0.01%
cpu : usr=5.35%, sys=23.17%, ctx=1359692, majf=0, minf=17
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% #单个IO提交要提交的IO数
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=1360097,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=16 #IO完延迟的分布
Run status group 0 (all jobs):
READ: bw=88.5MiB/s (92.8MB/s), 88.5MiB/s-88.5MiB/s (92.8MB/s-92.8MB/s)范围, io=5313MiB (5571MB), run=60001-60001msec
Disk stats (read/write):
sda: ios=1357472/0(所有group总共执行的IO数), merge=70/0(总共发生的IO合并数), ticks=949141/0(Number of ticks we kept the disk busy), in_queue=948776(花费在队列上的总共时间), util=99.88%(磁盘利用率)FIO实例:测试写
mkdir /test
fio -directory=/test -direct=0 -iodepth 1 -thread -rw=write -iodepth=64 -ioengine=psync -bs=16k -size=5G -numjobs=30 -runtime=60 -group_reporting -name=mytest其他指标
io=执行了多少M的IO
bw=平均IO带宽
iops=IOPS
runt=线程运行时间
slat=提交延迟,提交该IO请求到kernel所花的时间(不包括kernel处理的时间)
clat=完成延迟, 提交该IO请求到kernel后,处理所花的时间
lat=响应时间
bw=带宽
cpu=利用率
IO depths=io队列
IO submit=单个IO提交要提交的IO数
IO complete=Like the above submit number, but for completions instead.
IO issued=The number of read/write requests issued, and how many of them were short.
IO latencies=IO完延迟的分布
io=总共执行了多少size的IO
aggrb=group总带宽
minb=最小.平均带宽.
maxb=最大平均带宽.
mint=group中线程的最短运行时间.
maxt=group中线程的最长运行时间.
ios=所有group总共执行的IO数.
merge=总共发生的IO合并数.
ticks=Number of ticks we kept the disk busy.
io_queue=花费在队列上的总共时间.
util=磁盘利用率其他测试磁盘IO的方式可以自行了解,如hdparm