一 Spark与hadoop
Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce
Spark 支持多种编程语言,包括 Java、Python、R 和 Scala,同时 Spark 也支持 Hadoop 的底层存储系统 HDFS,但 Spark 不依赖 Hadoop。
Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富
关系图如下:

Hadoop、Hive、Spark 之间是什么关系、什么是Yarn
二 spark生态组成
通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择利用spark集群强大的计算资源,并行化地计算,
Spark 除了 Spark Core 外,还有其它由多个组件组成,目前主要有四个组件:Spark SQL、Spark Streaming、MLlib、GraphX。这四个组件加上 Spark Core 组成了 Spark 的生态。通常,我们在编写一个 Spark 应用程序,需要用到 Spark
Core 和其余 4 个组件中的至少一个。Spark 的整体构架图如下图所示:

Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD(弹性分布式数据集resilient distributed dataset),Spark SQL查询被转换为Spark操作。
Spark Streaming:这个模块主要是对流数据的处理,支持流数据的可伸缩和容错处理,Spark Streaming允许程序能够像普通RDD一样处理实时数据,可以与 Flume(针对数据日志进行优化的一个系统)和 Kafka(针对分布式消息传递进行优化的流处理平台)等已建立的数据源集成。Spark Streaming 的实现,也使用 RDD 抽象的概念,使得在为流数据(如批量历史日志数据)编写应用程序时,能够更灵活,也更容易实现。
MLlib:主要用于机器学习领域,它实现了一系列常用的机器学习和统计算法,如分类、回归、聚类、主成分分析等算法。
GraphX:这个模块主要支持数据图的分析和计算,并支持图形处理的 Pregel API 版本。GraphX 包含了许多被广泛理解的图形算法,如 PageRank。
Spark Core:是 Spark 的核心,主要负责任务调度等管理功能。Spark
Core 的实现依赖于 RDDs(Resilient Distributed Datasets,
弹性分布式数据集)的程序抽象概念。
Spark 底层还支持多种数据源,能够从其它文件系统读取数据,如 HDFS、Amazon S3、Hypertable、HBase 等。Spark 对这些文件系统的支持,同时也丰富了整个 Spark 生态的运行环境。
spark架构简图

Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
Driver: 运行Application 的main()函数
Executor:执行器,是为某个Application运行在worker node上的一个进程
三 Spark的架构详解

1、Application:
Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个Driver 功能的代码和分布在集群中多个节点上运行的Executor代码;
2、Driver:
负责运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive;
3、Executor:
执行器,是为了执行Application而运行在Worker 节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了;
4、Cluster Manager:
指的是在集群上获取资源的外部服务,目前有:
Ø Standalone:Spark原生的资源管理,由Master负责资源的分配,控制整个集群,监控worker;
Ø Hadoop Yarn(目前最流行):由YARN中的ResourceManager负责资源的分配;
Yarn介绍
大数据生态中有很多乱七八糟的工具,都在同一个集群上运转,大家需要互相尊重有序工作。所以另外一个重要组件是,调度系统:现在最流行的是Yarn。你可以把他看作中央管理,好比你妈在厨房监工,哎,你妹妹切菜切完了,你可以把刀拿去杀鸡了。只要大家都服从你妈分配,那大家都能愉快滴烧菜。
你可以认为,大数据生态圈就是一个厨房工具生态圈。为了做不同的菜,中国菜,日本菜,法国菜,你需要各种不同的工具。而且客人的需求正在复杂化,你的厨具不断被发明,也没有一个万用的厨具可以处理所有情况,因此它会变的越来越复杂。你可以认为,大数据生态圈就是一个厨房工具生态圈。为了做不同的菜,中国菜,日本菜,法国菜,你需要各种不同的工具。而且客人的需求正在复杂化,你的厨具不断被发明,也没有一个万用的厨具可以处理所有情况,因此它会变的越来越复杂。
5、Worker:
集群中任何可以运行Application代码的节点,类似于YARN中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点;
6、作业(Job):
包含多个Task组成的并行计算,往往由Spark Action催生, 一个Application中往往会产生多个Job,一个JOB包含多个RDD及作用于相应RDD上的各种Operation;
7、阶段(Stage):
每个Job会被拆分很多组Task,作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
8、任务(Task):
被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
一图说明job、stage、task三者的关系

9、DAGScheduler:
根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 根据RDD和Stage之间的关系找出开销最小的调度方法,然后把Stage以TaskSet的形式提交给TaskScheduler,下图展示了DAGScheduler的作用:
DAGScheduler决定了运行Task的理想位置,并把这些信息传递给下层的TaskScheduler。此外,DAGScheduler还处理由于Shuffle数据丢失导致的失败,这有可能需要重新提交运行之前的Stage(非Shuffle数据丢失导致的Task失败由TaskScheduler处理)。

10、TASKSedulter:
将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用

此外须知,在不同运行模式中TASKSedulter任务调度器具体为:
(1)Spark on Standalone模式为TaskScheduler
(2)YARN-Client模式为YarnClientClusterScheduler
(3)YARN-Cluster模式为YarnClusterScheduler
将上述术语串起来的运行层次图如下:

Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
四 Spark运行基本流程
1、不论 Spark 以何种模式进行部署,任务提交后,都会先启动 Driver 进程,即启动SparkContext,构建Spark Application的运行环境,随后 Driver(SparkContext )进程向资源管理器(可以是Standalone,Mesos,Yarn)注册应用程序、申请运行Executor资源
2、资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
3、Worker 上的 Executor 启动后会向 Driver 反向注册,SparkContext知晓具体的执行者有哪些之后,会依此构建生成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4、Task在Executor上运行,在任务执行的过程中,Executor 也会不断与 Driver 进行通信,报告任务运行情况。运行完释放所有资源
详细执行图

总结spark的运行特点:
1.每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统
2.Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了
3.提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换
4.Task采用了数据本地性和推测执行的优化机制
RDD运行原理
那么 RDD在Spark架构中是如何运行的呢?总高层次来看,主要分为三步:
1.创建 RDD 对象
2.DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG
3.每一个JOB被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销。

以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的。

步骤 1 :创建 RDD 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划。

步骤 3 :调度任务 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations 会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。

五 Spark运行模式
spark支持四种运行模式
1、本地运行模式(local模式),常用于本地开发测试
2、分布式集群模式之:独立运行模式(Standalone模式)
是Spark 自带的一种集群管理模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。它是 Spark 实现的资源调度框架,其主要的节点有 Driver 节点、Master 节点和 Worker 节点。Standalone模式也是最简单最容易部署的一种模式。
3、分布式集群模式之:Spark on Mesos模式
即 Spark 运行在Apache Mesos框架之上的一种模式。Apache Mesos是一个更强大的分布式资源管理框架,负责集群资源的分配,它允许多种不同的框架部署在其上,包括YARN。它被称为是分布式系统的内核。
4、分布式集群模式之:Spark on YARN模式
即 Spark 运行在Hadoop YARN框架之上的一种模式。Hadoop YARN(Yet Another Resource
Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。
针对三种分布式集群模式,都采用了Master/Worker(Slave)的架构,Spark 分布式运行架构大致如下:

Spark客户端直接连接Mesos,不需要额外构建Spark集群,国内用的少;
Spark客户端直接连接Yarn,不需要额外构建Spark集群。国内生产上用的多。
而集群模式又根据Driver运行在哪又分为客Client模式和Cluster模式。用户在提交任务给 Spark 处理时,以下两个参数共同决定了 Spark 的运行方式。
· –master MASTER_URL :决定了 Spark 任务提交给哪种集群处理。
· –deploy-mode DEPLOY_MODE:决定了 Driver 的运行方式,可选值为 Client或者 Cluster。

5.1 standalone独立集群运行模式
Standalone模式使用Spark自带的资源调度框架,Standalone 集群有四个重要组成部分,分别是:
1、Driver:
是一个进程,我们编写的 Spark 应用程序就运行在 Driver 上,由Driver 进程执行;
Driver既可以运行在Master节点上中,也可以运行在本地Client端。
当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;
当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用
”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
2、aster:
是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
3、Worker:
是一个进程,一个 Worker 运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储 RDD 的某个或某些 partition;另一个是启动其他进程和线程(Executor),对 RDD 上的 partition 进行并行的处理和计算。
4、Executor:
是一个进程,一个 Worker 上可以运行多个 Executor,Executor通过启动多个线程(task)来执行对 RDD 的 partition 进行并行计算,也就是执行我们对 RDD 定义的例如 map、flatMap、reduce 等算子操作。
5.1.1 Standalone的client模式

解析:
在 Standalone Client 模式下,Driver 在任务提交的本地机器上运行,Driver 启动后向 Master 注册应用程序,Master 根据 submit 脚本的资源需求找到内部资源至少可以启动一个 Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker上的 Executor 启动后会向 Driver 反向注册,所有的 Executor 注册完成后,Driver 开始执行 main 函数,之后执行到 Action 算子时,开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个 Executor 上执行。
运行流程详解

1.SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory);
2.Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;
3.StandaloneExecutorBackend向SparkContext注册;
4.SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
5.StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
6.所有Task完成后,SparkContext向Master注销,释放资源。
5.1.2 Standalone的cluster模式

解析
在 Standalone Cluster 模式下,任务提交后,Master 会找到一个 Worker 启动 Driver进程, Driver 启动后向 Master 注册应用程序,Master 根据 submit 脚本的资源需求找到内部资源至少可以启动一个 Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker 上的 Executor 启动后会向 Driver 反向注册,所有的 Executor注册完成后,Driver 开始执行 main 函数,之后执行到 Action 算子时,开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个 Executor 上执行。注意,Standalone 的两种模式下(client/Cluster),Master 在接到 Driver 注册Spark 应用程序的请求后,会获取其所管理的剩余资源能够启动一个 Executor 的所有 Worker,然后在这些 Worker 之间分发 Executor,此时的分发只考虑 Worker 上的资源是否足够使用,直到当前应用程序所需的所有 Executor 都分配完毕,Executor反向注册完毕后,Driver 开始执行 main 程序。
5.1.3 YARN框架原理
何框架与YARN的结合,都必须遵循YARN的开发模式。在分析Spark on YARN的实现细节之前,有必要先分析一下YARN框架的一些基本原理。
Yarn框架的基本运行流程图为:

其中,ResourceManager负责将集群的资源分配给各个应用使用,而资源分配和调度的基本单位是Container,其中封装了机器资源,如内存、CPU、磁盘和网络等,每个任务会被分配一个Container,该任务只能在该Container中执行,并使用该Container封装的资源。NodeManager是一个个的计算节点,主要负责启动Application所需的Container,监控资源(内存、CPU、磁盘和网络等)的使用情况并将之汇报给ResourceManager。ResourceManager与NodeManagers共同组成整个数据计算框架,ApplicationMaster与具体的Application相关,主要负责同ResourceManager协商以获取合适的Container,并跟踪这些Container的状态和监控其进度。
5.1.4 YARN的client运行模式
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问。
YARN-client的工作流程分为以下几个步骤:

1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。
同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到请求后
,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后
,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,
便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,
CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,
Client的SparkContext向ResourceManager申请注销并关闭自己。
5.1.5 YARN的cluster运行模式
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
1.第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;
2.第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
1. Spark Yarn Client向YARN中提交应用程序,
包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2. ResourceManager收到请求后,
在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3. ApplicationMaster向ResourceManager注册,
这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4. 一旦ApplicationMaster申请到资源(也就是Container)后,
便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5. ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,
CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6. 应用程序运行完成后,
ApplicationMaster向ResourceManager申请注销并关闭自己。
5.1.6 YARN-Client 与 YARN-Cluster 区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
l YARN-Cluster模式下,
Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
l YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。

补充
因为在Spark作业运行过程中,一般情况下会有大量数据在Driver和集群中进行交互,
所以如果是基于yarn-client的模式,则会在程序运行过程中产生大量的网络数据传输,
造成网卡流量激增;而基于yarn-cluster这种模式,因为driver本身就在集群内部,
所以数据的传输也是在集群内部来完成,那么网络传输压力相对要小;
所以在企业生产环境下多使用yarn-cluster这种模式,测试多用yarn-client这种模式。
但是带来一个问题,就是不方便监控日志,yarn-cluster这种模式要想监控日志,
必须要到每一台机器上面去查看,但这都不是问题,因为我们有sparkUI,同时也有各种各样的日志监控组件
六 spark使用与不同模式的部署
官方:https://spark-reference-doc-cn.readthedocs.io/zh_CN/latest/deploy-guide/spark-standalone.html
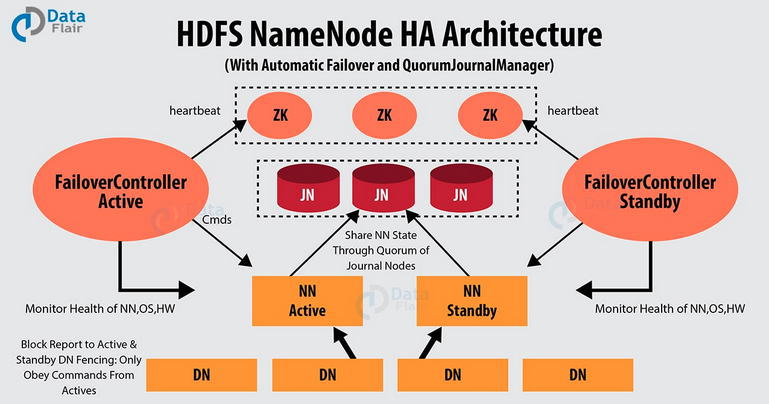
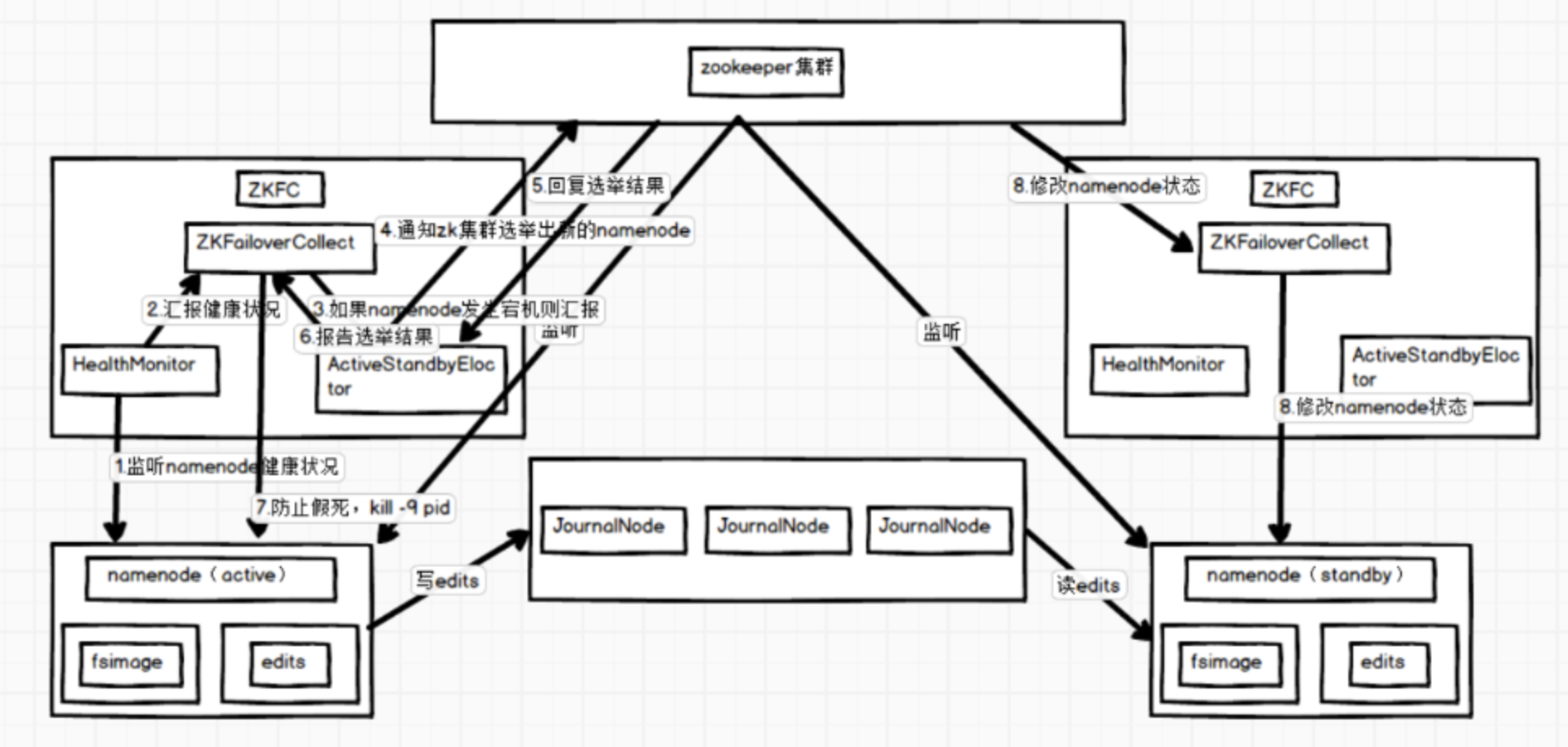
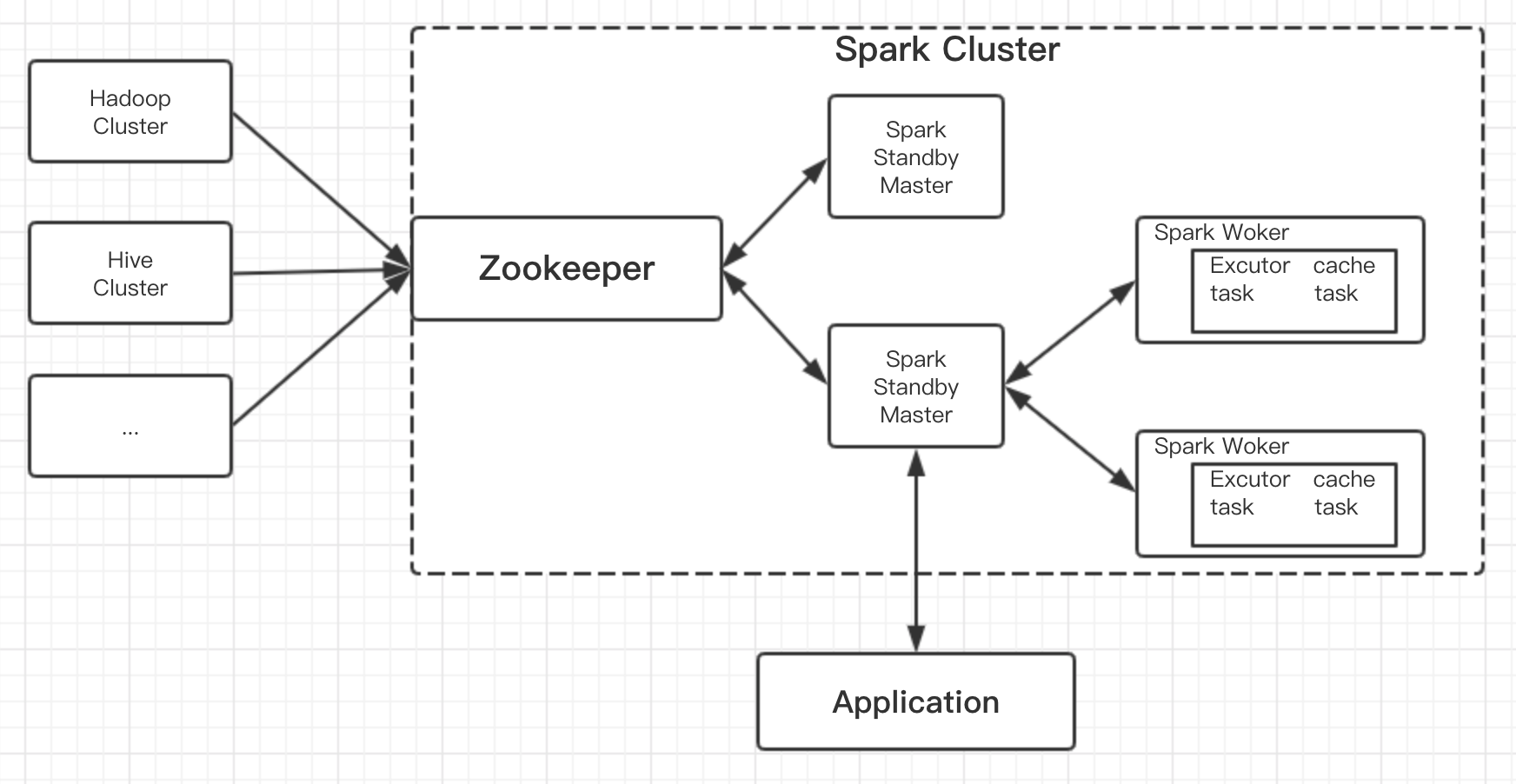
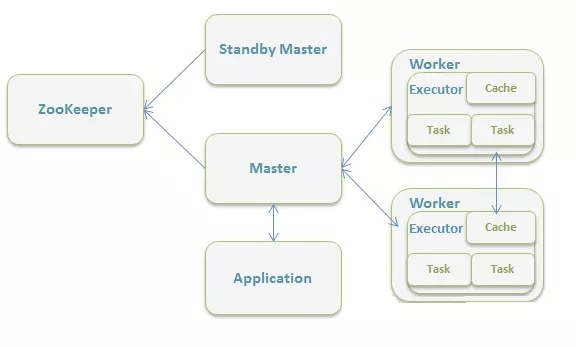
Standalone spark自带的集群模式。需要构建一个由Master+Slave构成的Spark集群,选用ZooKeeper来实现Master的HA,框架结构图如下:
https://zhuanlan.zhihu.com/p/99398378
推荐阅读:
https://www.cnblogs.com/shishanyuan/p/4721326.html
https://blog.csdn.net/shuimofengyang/article/details/100124601
https://www.cnblogs.com/jinggangshan/p/8063970.html
https://blog.csdn.net/github_26054561/article/details/46344889