一、思维导图

二、文件块、磁盘块


其实和程序与内存的分块类似
三、文件分配方式
3.1 连续分配
连续分配的方式要求每个文件在磁盘上占有一组连续的块
连续分配的方式要求每个文件在磁盘上占有一组连续的块
连续分配的方式要求每个文件在磁盘上占有一组连续的块
连续分配的方式要求每个文件在磁盘上占有一组连续的块
连续分配的方式要求每个文件在磁盘上占有一组连续的块
连续分配的方式要求每个文件在磁盘上占有一组连续的块
连续分配的方式要求每个文件在磁盘上占有一组连续的块
- 核心原理:存入磁盘时是连续存放的,文件目录里存放的是起始块号与长度,因为数据存放在磁盘中的是连续的,所以在读的时候你拿到起始块号再加一个长度就能把数据都取出来,极大地降低了寻道时间
- 关于访问:支持顺序访问也支持随机访问

1、逻辑分配方式最大的特点就是物理存储上连续
2、由于是连续存储,所以进行地址映射时,只需要块号的映射关系,而块内地址不需要进行映射
3、用户要访问一个位置:首先要找到目录文件中与之对应的文件目录项中的起始块号,然后物理块号=起始块号+逻辑块号,最后通过快内地址找到所要访问的位置。
连续分配的优缺点
- 优点:
支持顺序访问和直接访问(或者叫随机访问),当然了,连续分配的文件在顺序访问时的速度是最快的,因为通常情况下读取某个磁盘块时,需要移动磁头进行寻道,如果访问的两个磁盘块相隔越远,寻道时间久会越长,而如果是连续分配的,读的时候也采用顺序读,就会降低很多寻道时间,速度自然是快 - 缺点:
- (1)、存储空间利用率低,会产生磁盘碎片

- (2)、不方便文件拓展


3.2 链接分配
(1)隐式链接
- 核心原理:存入磁盘时可能是不连续的,文件存储的所有磁盘块里,除了最后一个磁盘块,每个都会保存指向下一个磁盘块的指针,文件目录里存放的是起始块号与结束块号,然后安装起始块号找到一个磁盘块,然后就可以一个一个指向下一个,直到指到了结束块
- 关于访问:只支持顺序访问,不支持随机访问
(2)显示链接
- 核心原理:本质就是把每个磁盘块里关于指向下一个块的指针信息写到了一张专门的表里(即FAT表),这个表里存放的信息还是指向下一个的方式,文件目录里存放的是起始块号就可以了,不需要存放结束块号,拿到起始块号,再将FAT表读入内存,照着表查你想要的下一个块就行
- 关于访问:支持顺序访问,也支持随机访问
逻辑地址与物理地址的转化:
1、用户给出逻辑块号,操作系统从文件目录表找到对应FCB
2、从FCB中找到起始地址块号算出物理块号,然后查找FAT
3、直接找到物理块(随机存取)
由于FAT常驻内存,所以逻辑地址到物理地址的转化不需要进行I/O读写。
3.3 索引分配
- 核心原理:存入磁盘的数据可能是不连续的,每个文件都会有壹账索引表,里面存放的是每个物理磁盘号与逻辑磁盘号的对应关系,相当于key:value,这张表就相当于一个字典一样。这与链接方式是不同的,链接方式的表里存放的内容是指向下一个的关系,而索引表里则没有指向下一个的关系。文件/目录里会存放自己这个文件对应的索引块的号码,找到了该索引快,就拿到了一个“字典”想要哪一个,就照着查就行
- 关于访问:支持随机访问,通常都代表随机访问





- 1、在索引分配方式中,文件目录表中的FCB需要新加一个索引块的字段:用于存放该文件索引表存放的位置
- 2、在显式链接的链式分配方式中,文件分配表FAT 是一个磁盘对应一张。而索引分配方式中,索引表是一个文件对应一张。
- 3、文件的逻辑块号到物理块号的转换:首先,用户给出要访问的逻辑块号 i,操作系统找到该文件对应的目录项(FCB);其次,从目录项中可知索引表存放位置,将索引表从外存读入内存,并查找索引表即可只 i 号逻辑块在外存中的存放位置。因此,索引分配方式可以支持随机访问。文件拓展也很容易实现(只需要给文件分配一个空闲块,并增加一个索引表项即可)但是索引表需要占用一定的存储空间
- 4、问题:若每个磁盘块1KB,一个索引表项4B,则一个磁盘块只能存放 256 个索引项。如果一个文件的大小超过了256块,那么一个磁盘块是装不下文件的整张索引表的,如何解决这个问题?
四、如果一个文件的大小超过一个磁盘块怎么办?
4.1、链接方案

1、解决方法:用多个索引块链接存储,FCB中存储第一个索引块的位置即可
2、问题:当有很多索引块时,必须先将前面所有的索引块读入内存才可以找到你要的索引块,因此,其效率很低。从而产生了多级索引。
4.2、多层索引
采用K层索引结构,且顶级索引表未调入内存,则访问一个数据块只需要K+1次读磁盘操作

问题:当你只有很小的数据时,假如只有1KB,本来可以只读入索引表就可以查询到该文件位置,但是采用二级索引表却要读入一级索引表和二级索引表,得不偿失,为解决该问题,引入混合索引
4.3、混合索引
这种结构的索引支持的最大文件长度为65800KB

就是将索引表和多级索引表混合使用,当数据很小时,就可以用直接索引,当数据很大时,就可以使用多级索引。


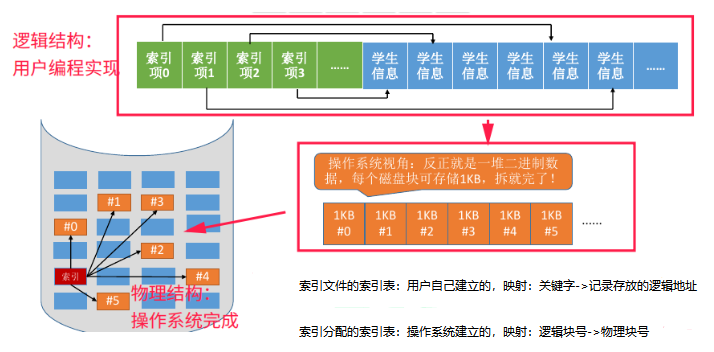
五、什么是逻辑结构,什么是物理结构?
物理结构:本质上来看是当我们在进行数据的存储时,操作系统会将数据保存到硬盘中,但是他会以什么样的方式存储就是所谓的物理结构,例如操作系统可能会以顺序或者链式的方式存储数据。对于用户而言,操作系统对数据的存储是不可见的。用户并不关心。
逻辑结构:本质上来看是用户在编写程序时,用何种方式来组织数据,文件的逻辑结构是用户来定义的,只是表示一个数据和一个数据的前后逻辑关系是什么样的。操作系统并不关心。
六、顺序文件采用顺序存储/链式存储

蓝色的部分:就是用户对于文件采用的逻辑结构的定义
橙色的部分:在操作系统看来,整个文件就是一堆二进制代码,操作系统按照物理块大小将这堆二进制文件拆分后;采用顺序的方式存储到硬盘上就是物理结构的顺序存储。采用链式的方式存储到硬盘上就是物理结构的链式存储
七、索引文件采用索引分配
八、拓展读/写文件的完整流程
下图是用户程序读写文件时必须经过的OS和硬件交互的内存模型

(1)读文件
用户程序通过编程语言提供的读取文件api发起对某个文件读取。此时程序切换到内核态,用户程序处于阻塞状态。由于读取的内容还不在内核缓冲区中,导致触发OS缺页中断异常。然后由OS负责发起对磁盘文件的数据读取。读取到数据后,先存放在OS内核的主存空间,叫PageCache。然后OS再将数据拷贝一份至用户进程空间的主存ByteBuffer中。此时程序由内核态切换至用户态继续运行程序。程序将ByteBuffer中的内容读取到本地变量中,即完成文件数据读取工作。
(2)写文件
用户程序通过编程语言提供的写入文件api发起对某个文件写入磁盘。此时程序切换到内核态用户程序处于阻塞状态,由OS负责发起对磁盘文件的数据写入。用户写入数据后,并不是直接写到磁盘的,而是先写到ByteBuffer中,然后再提交到PageCache中。最后由操作系统决定何时写入磁盘。数据写入PageCache中后,此时程序由内核态切换至用户态继续运行。
用户程序将数据写入内核的PageCache缓冲区后,即认为写入成功了。程序由内核态切换回用于态,可以继续后续的工作了。PageCache中的数据最终写入磁盘是由操作系统异步提交至磁盘的。一般是定时或PageCache满了的时候写入。如果用户程序通过调用flush方法强制写入,则操作系统也会服从这个命令。立即将数据写入磁盘然后由内核态切换回用户态继续运行程序。但是这样做会损失性能,但可以确切的知道数据是否已经写入磁盘了。
(3) 文件读写的详细过程
1、读文件
如下所示为一典型Java读取某文件内容的用户编程代码。接下来我们详细解说读取文件过程。
// 一次读多个字节
byte[] tempbytes = new byte[100];
int byteread = 0;
in = new FileInputStream(fileName);//①
ReadFromFile.showAvailableBytes(in);
// 读入多个字节到字节数组中,byteread为一次读入的字节数
while ((byteread = in.read(tempbytes)) != -1) { //②
System.out.write(tempbytes, 0, byteread);
} 首先通过位置①的代码发起一个open的系统调用,程序由用户态切换到内核态。操作系统通过文件全路径名在文件目录中找到目标文件名对应的文件iNode标识ID,然后用这个iNode标识ID在iNode索引文件找到目标文件iNode节点数据并加载到内核空间中。这个iNode节点包含了文件的各种属性(创建时间,大小以及磁盘块空间占用信息等等)。然后再由内核态切换回用户态,这样程序就获得了操作这个文件的文件描述。接下来就可以正式开始读取文件内容了。
然后再通位置②,循环数次获取固定大小的数据。通过发起read系统调用,操作系统通过文件iNode文件属性中的磁盘块空间占用信息得到文件起始位的磁盘物理地址。再从磁盘中将要取得数据拷贝到PageCache内核缓冲区。然后将数据拷贝至用户进程空间。程序由内核态切换回用户态,从而可以读取到数据,并放入上面代码中的临时变量tempbytes中。
整个过程如下图所示。

至于上面说到的操作系统通过iNode节点中的磁盘块占用信息去定位磁盘文件数据。其细节过程如下图所示。
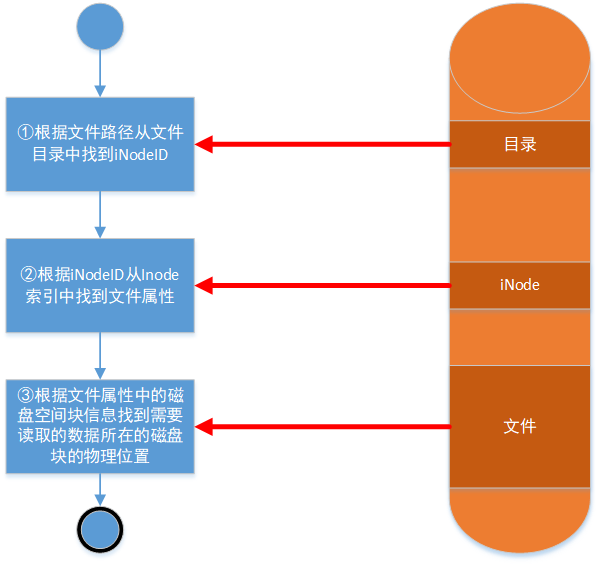
①根据文件路径从文件目录中找到iNode ID。
用户读取一个文件,首先需要调用OS中文件系统的open方法。该方法会返回一个文件描述符给用户程序。OS首先根据用户传过来的文件全路径名在目录索引数据结构中找到文件对应的iNode标识ID。目录数据是存在于磁盘上的,在OS初始化时就会加载到内存中,由于目录数据结构并不会很庞大,一次性加载驻留到内存也不是不可以或者部分加载,等需要的时候在从磁盘上调度进内存也可以。根据文件路径在目录中查找效率应该是很高的,因为目录本身就是一棵树,应该也是类似数据库的树形索引结构。所以它的查找算法时间复杂度就是O(logN)。具体细节我暂时还没弄清楚,这不是重点。
iNode就是文件属性索引数据了。磁盘格式化时OS就会把磁盘分区成iNode区和数据区。iNode节点就包含了文件的一些属性信息,比如文件大小、创建修改时间、作者等等。其中最重要的是还存有整个文件数据在磁盘上的分布情况(文件占用了哪些磁盘块)。
②根据iNode ID从Inode索引中找到文件属性。
得到iNode标识的ID后,就可以去iNode数据中查找到对应的文件属性了,并加载到内存,方便后续读写文件时快速获得磁盘定位。iNode数据结构应该类似哈希结构了,key就是iNode标识ID,value就是具体某个文件的属性数据对象了。所以它的算法时间复杂度就是O(1)。具体细节我暂时还没弄清楚,这不是重点。
我们系统中的文件它的文件属性(iNode)和它的数据正文是分开存储的。文件属性中有文件数据所在磁盘块的位置信息。
③根据文件属性中的磁盘空间块信息找到需要读取的数据所在的磁盘块的物理位置
文件属性也就是iNode节点这个数据结构,里面包含了文件正文数据在磁盘物理位置上的分布情况。磁盘读写都是以块为单位的。所以这个位置信息其实也就是一个指向磁盘块的物理地址指针。
其结构图如下。

文件属性里就包含了文件正文数据占有磁盘所有信息。但是由于文件属性大小有限制,而文件大小没有限制。这样会导致磁盘块占用信息超出限制。所以最后一个磁盘数据项设计为特殊的作用。它是一个指向更多磁盘占用信息数据的指针。这些更多信息存放在普通的数据区。这样当文件iNode加载到内存后,可以把其他更多磁盘块信息一起加载进来。这样就避免了iNode索引文件太大的问题。
后续的文件读写系统调用,由用户态切换至内核态。操作系统就可以根据文件数据的相对位置(偏移量)快速从iNode中的磁盘块占用数据结构中找到其对应的磁盘物理位置在哪里了。很明显这个数据结构类似哈希结构,其算法复杂度就是O(1)。
比如我们现在讨论的读取数据。每次用户代码的api调用read方法时。由于时从头开始读取,所以OS就从上图中“磁盘块0”数据项开始迭代,获取对应的物理磁盘块起始地址开始读取数据并拷贝至PageCache缓冲区,再拷贝至用户进程缓冲区。这样用户代码就可以获取这些数据了。
考虑到另外一种随机读的场景。我们并不是把整个文件从头开始读一遍。而是需要直接定位到文件的中间某个位置开始 读取部分内容。如下所示。
RandomAccessFile raf=new RandomAccessFile(new File("D:\\3\\test.txt"), "r");
//获取RandomAccessFile对象文件指针的位置,初始位置是0
System.out.println("RandomAccessFile文件指针的初始位置:"+raf.getFilePointer());
raf.seek(pointe);//移动文件指针位置
byte[] buff=new byte[1024];
//用于保存实际读取的字节数
int hasRead=0;
//循环读取
while((hasRead=raf.read(buff))>0){
//打印读取的内容,并将字节转为字符串输入
System.out.println(new String(buff,0,hasRead));
} 程序代码调用seek方法直接定位到某个文件相对位置开始读取内容。实际上就是调用了OS管理文件的系统调用seek函数。这个系统调用需要传递一个文件相对位置也就是偏移量,不是指磁盘的物理位置。文件的相对位置偏移量是从0开始的,结束位置和文件的大小字节数相等。操作系统拿到这个偏移量后,就可以计算出文件所属的逻辑块编号。因为每个块是固定大小的,所以能计算出来。通过文件属性的逻辑磁盘块信息就能得到磁盘块的物理位置。从而可以快速直接定位到磁盘物理块读取到需要的数据。这里说的逻辑块和物理块的概念是有区别的。逻辑块属于当前的文件从0开始编号,物理块才是磁盘真正的存放数据的区域,属于全局的。编号自然不是从0开始的。
2、写文件
写文件的过程和前面阐述的差不多,相关的知识点也在读文件中已经顺带描述了。就不在赘述了。这里就说些特别需要注意的点就行。

③根据空闲块索引找到可以写入的物理位置并写入
如上图所示,OS写文件内容时首先要访问磁盘空闲块索引表。这是个什么东西呢?由于磁盘很大,不可能每次写数据时,都让磁头从头到尾遍历一次才能找到空闲位置。这样效率可想而知的差劲。所以OS会把磁盘上的空闲块索引起来存放在磁盘某个位置上。后续磁盘存储和删除文件内容时都通过这个空闲块索引表快速定位,同时删除数据也会更新索引表增加空闲块。
空闲块记录索引的实现常用有两种,一种是我们熟悉的链表结构,还有一种是位图结构。这里就不详细讨论了。
④写入数据后更新iNode里的磁盘占用块索引
数据写入后,那么这个空闲块就被占用了,自然也就需要更新下iNode文件属性里的磁盘占用块索引数据了。
我们前面说的写文件都是只讲了尾部追加这种方式。但是实际上我们可以通过RandomAccessFile类实现文件随机位置写功能。但是我们同时也有一些困惑。为啥不能直接在中间某个位置插入我们要写的内容,而是要先把插入位置后面的内容截取放入临时文件中。插入新内容后,再把临时文件内容尾部追加到原来的文件中来实现文件修改?代码如下所示。
public static void insert(String fileName, long pos, String insertContent) throws IOException{
File file = File.createTempFile("tmp", null);
file.deleteOnExit();
RandomAccessFile raf = new RandomAccessFile(fileName, "rw");
FileInputStream fileInputStream = new FileInputStream(file);
FileOutputStream fileOutputStream = new FileOutputStream(file);
raf.seek(pos);
byte[] buff = new byte[64];
int hasRead = 0;
while((hasRead = raf.read(buff)) > 0){
fileOutputStream.write(buff);
}
raf.seek(pos);
raf.write(insertContent.getBytes());
//追加文件插入点之后的内容
while((hasRead = fileInputStream.read(buff)) > 0){
raf.write(buff, 0, hasRead);
}
raf.close();
fileInputStream.close();
fileOutputStream.close();
} 按照我们上面的阐述,写入的文件内容完全可以存入磁盘上的一个新块,然后更新下iNode属性里的占用磁盘块索引数据即可。也不需要真的去移动磁盘上的所有数据块。看上去成本也很小,可为啥我们的编程api却都不支持呢?
我想答案可能是这样的。假如允许我们上面那种操作,如果一个很大的文本文件。你现在只是编辑了文本中间某个位置的一个字,即插入了一个文本字符。那么此时这个新增的文本内容就得在磁盘上找到一个新的块存储下来。这样是不是有点浪费空间呢?因为磁盘上的一个块只能分配给一个文件使用,块大小如果是64kb的话,一个字符也就占用了2个字节的空间。更要命的是这样一搞,使得原本满存状态的块,出现很多不连续的空洞。这样就会使得读取文件时数据是不连续的,系统需要额外信息记录这些中间的存储空洞。加大了读取难度。这就是我猜测的原因。实际上操作系统层面也没有这种操作插入的系统调用函数。故编程语言层面也就没法支持了。
操作系统层面给上层应用程序提供了写文件的两个系统调用。write和append,其中append是write的限制形式,即只能在文件尾部追加。而write虽然提供了随机位置写,但是并不是将新内容插入其中,而是覆盖原有的数据。我们平时使用Word文本编辑软件时,如果对一个很大的文件进行编辑,然后点击保存,你会发现很慢。同时你还能看到文件所在的目录下生成了一个新的处于隐藏状态的临时文件。这些现象也能说明我们上面的观点。即编辑文件时,需要一个成本很高的过程。如下图所示。
