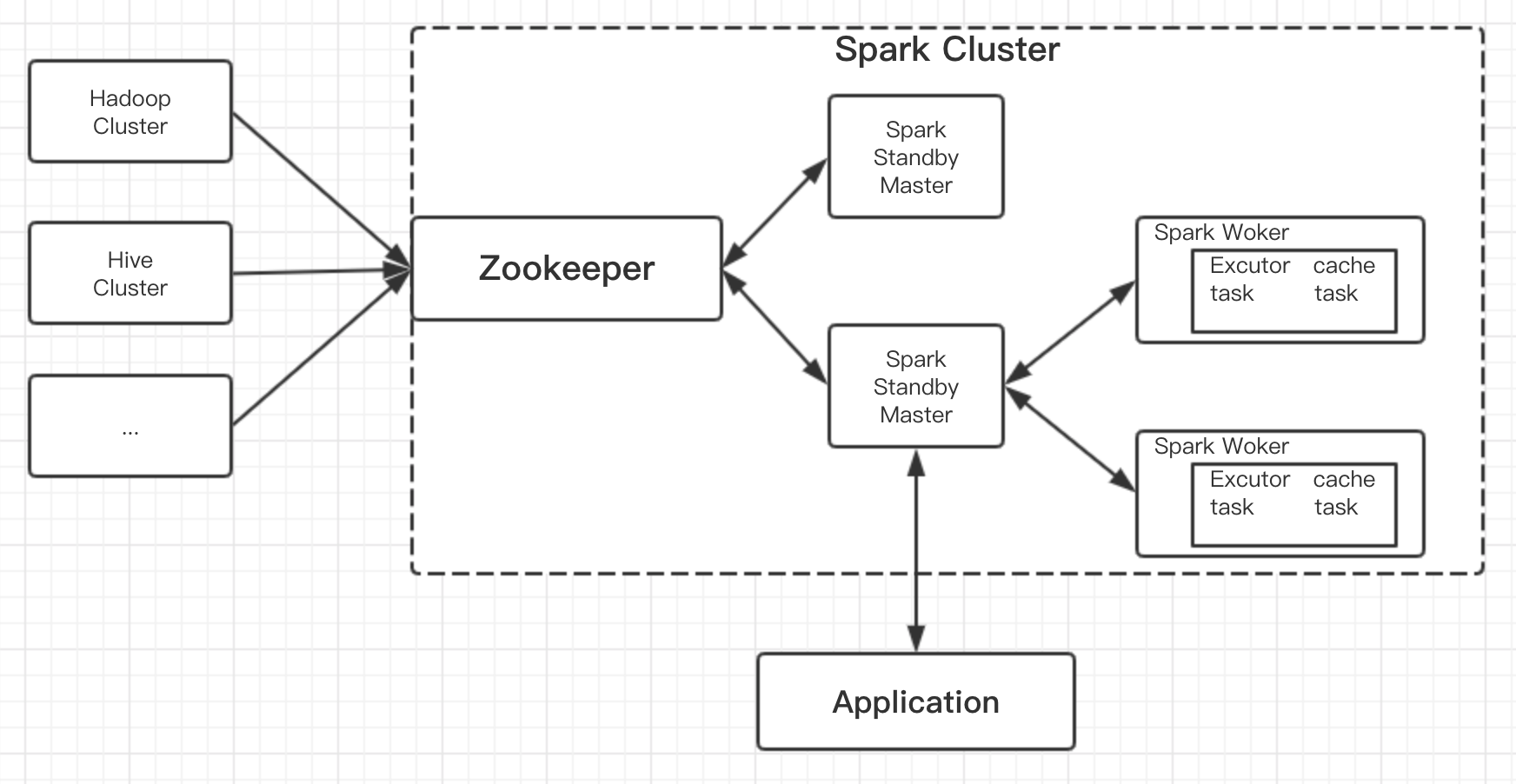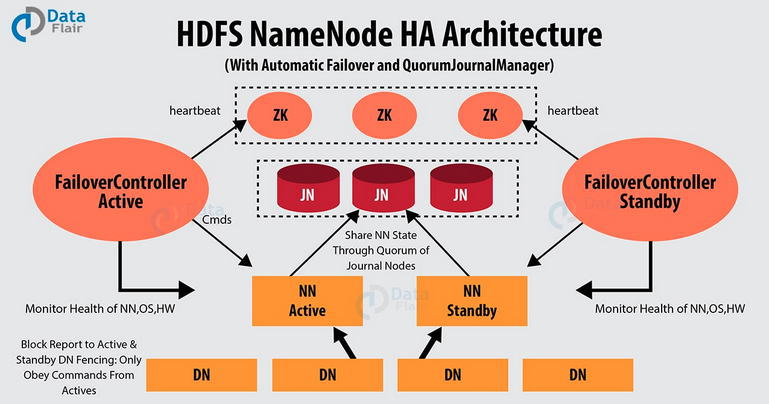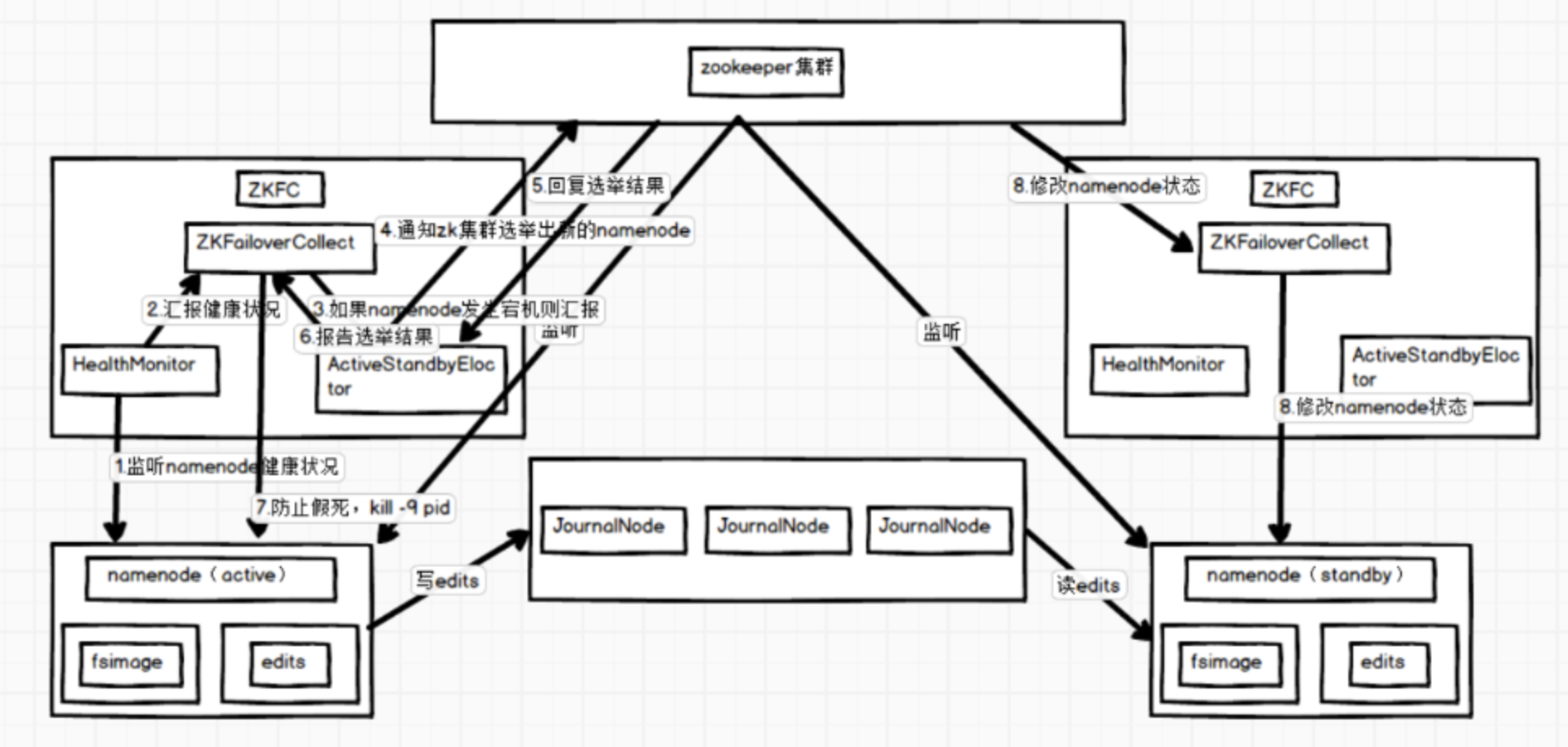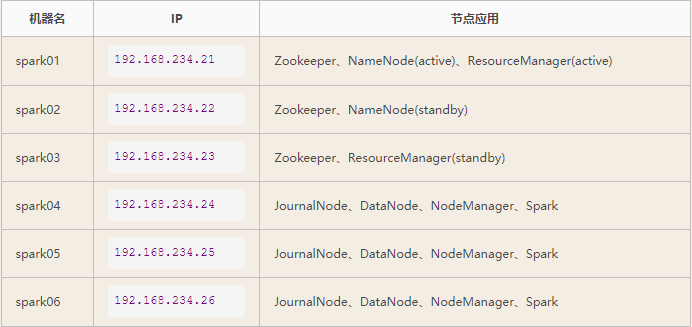
spark01 主 10.61.187.24
spark02 从 10.61.187.20
vip: 10.61.187.51
在spark01与spark02部署
yum -y install haproxy keepalived -y # yum源已配置过了,此处直接安装即可在spark01与spark02修改haproxy配置:vim /etc/haproxy/haproxy.cfg
global
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode tcp
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen stats
mode http
bind 0.0.0.0:8099
stats enable
stats hide-version
stats uri /haproxy_status
stats realm Haproxy\ Statistics
stats auth admin:ha.BaiDU@2022
stats admin if TRUE
listen redis
bind 0.0.0.0:6379
mode tcp
balance roundrobin
server c1 192.168.234.21:7001 check
server c2 192.168.234.22:7002 check
server c3 192.168.234.23:7003 check
server c4 192.168.234.22:7004 check
server c5 192.168.234.23:7005 check
server c6 192.168.234.21:7006 check
# haproxy代理所有的redis包括从,因为即便你在从主机上进行写操作,也会根据计算出的插槽号切换到对应主redis
# 我们haproxy上对redis调度上下线没什么用,因为redis cluster当前节点查不到数据是自动跳到对应的节点的,只要后端没宕机的话,它仍然会切换的。
在spark01修改keepalived配置:
vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb01
script_user root
enable_script_security
}
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3
weight 2
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 6666
}
track_script {
chk_haproxy #监测haproxy进程状态
}
virtual_ipaddress {
10.61.187.51/25 dev eth0
}
track_interface {
eth0
}
# 上联交换机若禁用了arp的广播限制,会造成keepalive无法通过广播通信,两台服务器抢占vip,出现同时都有vip的情况
# 所以此处可以调整为单播
# 本机ip,本例中为spark01主机的ip
unicast_src_ip 10.61.187.24
unicast_peer {
# 对端ip,本例中为spark02主机的ip
10.61.187.20
}
}在spark02修改keepalived配置:
vim/etc/keepalived/keepalived.conf
global_defs {
router_id lb02
script_user root
enable_script_security
}
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3
weight 2
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface eth0
virtual_router_id 50 # 可理解为分组,应该与主保持一致
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 6666
}
track_script {
chk_haproxy #监测haproxy进程状态
}
virtual_ipaddress {
10.61.187.51/25 dev eth0
}
track_interface {
eth0
}
# 源ip为自己本机的ip地址
unicast_src_ip 10.61.187.20
unicast_peer {
# 对端ip
10.61.187.24
}
}
在spark01与spark02创建检测脚本:
/etc/keepalived/check_haproxy.sh
# 1、vim /etc/keepalived/check_haproxy.sh
#!/bin/bash
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then #条件成立,证明haproxy挂掉
systemctl start haproxy #先尝试启动haproxy程序
fi
sleep 2 #睡眠两秒钟,等待haproxy完全启动
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then #若haproxy仍未启动成功,则关闭keepalived,飘逸vip
systemctl stop keepalived
fi
# 2、赋予可执行权限
chmod +x /etc/keepalived/check_haproxy.sh
在spark01与spark02开启keepalived日志
#配置keepalived
[root@lb01 ~]# vim /etc/sysconfig/keepalived
KEEPALIVED_OPTIONS="-D -d -S 0"
#配置rsyslog抓取日志
[root@lb01 ~]# vim /etc/rsyslog.conf # 文件末尾追加
local0.* /var/log/keepalived.log
#重启服务
[root@lb01 ~]# systemctl restart rsyslog在spark01与spark02启动服务:
systemctl start haproxy
systemctl start keepalived
systemctl enable haproxy
systemctl enable keepalived
# 可以在管理界面查看:http://spark01的ip地址:8099/haproxy_status # 输入配置文件的中的账号密码keepalived.conf参数说明
############################ 全局配置 #############################
global_defs {
# 定义管理员邮件地址,表示keepalived在发生诸如切换操作时需要发送email通知,以及email发送给哪些邮件地址,可以有多个,每行一个
notification_email {
#设置报警邮件地址,可以设置多个,每行一个。 需开启本机的sendmail服务
13020176132@163.com
}
#keepalived在发生诸如切换操作时需要发送email通知地址,表示发送通知的邮件源地址是谁
notification_email_from 13020176132@163.com
#指定发送email的smtp服务器
smtp_server 127.0.0.1
#设置连接smtp server的超时时间
smtp_connect_timeout 30
#运行keepalived的机器的一个标识,通常可设为hostname。故障发生时,发邮件时显示在邮件主题中的信息。
router_id swarm01
}
############################ VRRPD配置 #############################
# 定义chk_http_port脚本,脚本执行间隔10秒,权重-5,检测nginx服务是否在运行。有很多方式,比如进程,用脚本检测等等
vrrp_script chk_http_port {
#这里通过脚本监测
script "/opt/chk_nginx.sh"
#脚本执行间隔,每2s检测一次
interval 2
#脚本结果导致的优先级变更,检测失败(脚本返回非0)则优先级 -5
weight -5
#检测连续2次失败才算确定是真失败。会用weight减少优先级(1-255之间)
fall 2
#检测1次成功就算成功。但不修改优先级
rise 1
}
#定义vrrp实例,VI_1 为虚拟路由的标示符,自己定义名称,keepalived在同一virtual_router_id中priority(0-255)最大的会成为master,也就是接管VIP,当priority最大的主机发生故障后次priority将会接管
vrrp_instance VI_1 {
#指定keepalived的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备用服务器。注意这里的state指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,
#但这里指定的不算,还是得要通过竞选通过优先级来确定。如果这里设置为MASTER,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,
#那么他会就回抢占为MASTER
state MASTER
#指定HA监测网络的接口。与本机 IP 地址所在的网络接口相同,可通过ip addr 查看
interface ens33
# 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在哪个地址上发送VRRP通告,这个非常重要,
#一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
mcast_src_ip 192.168.182.110
#虚拟路由标识,这个标识是一个数字,同一个vrrp实例使用唯一的标识。即同一vrrp_instance下,MASTER和BACKUP必须是一致的
virtual_router_id 51
#定义优先级,数字越大,优先级越高,在同一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级
priority 101
#设定MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
advert_int 1
#设置验证类型和密码。主从必须一样
authentication {
#设置vrrp验证类型,主要有PASS和AH两种
auth_type PASS
#设置vrrp验证密码,在同一个vrrp_instance下,MASTER与BACKUP必须使用相同的密码才能正常通信
auth_pass 1111
}
#VRRP HA 虚拟地址 如果有多个VIP,继续换行填写
#设置VIP,它随着state变化而增加删除,当state为master的时候就添加,当state为backup的时候则删除,由优先级决定
virtual_ipaddress {
192.168.182.156
}
#执行nginx检测脚本。注意这个设置不能紧挨着写在vrrp_script配置块的后面(实验中碰过的坑),否则nginx监控失效!!
track_script {
#引用VRRP脚本,即在 vrrp_script 部分指定的名字。定期运行它们来改变优先级,并最终引发主备切换。
chk_http_port
}
}
#定义vrrp实例,VI_2 为虚拟路由的标示符,自己定义名称,keepalived在同一virtual_router_id中priority(0-255)最大的会成为master,也就是接管VIP,当priority最大的主机发生故障后次priority将会接管
vrrp_instance VI_2 {
#指定keepalived的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备用服务器。注意这里的state指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,
#但这里指定的不算,还是得要通过竞选通过优先级来确定。如果这里设置为MASTER,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,
#那么他会就回抢占为MASTER
state BACKUP
#指定HA监测网络的接口。与本机 IP 地址所在的网络接口相同,可通过ip addr 查看
interface ens33
# 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在哪个地址上发送VRRP通告,这个非常重要,
#一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
mcast_src_ip 192.168.182.110
#虚拟路由标识,这个标识是一个数字,同一个vrrp实例使用唯一的标识。即同一vrrp_instance下,MASTER和BACKUP必须是一致的
virtual_router_id 52
#定义优先级,数字越大,优先级越高,在同一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级
priority 100
#设定MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
advert_int 1
#设置验证类型和密码。主从必须一样
authentication {
#设置vrrp验证类型,主要有PASS和AH两种
auth_type PASS
#设置vrrp验证密码,在同一个vrrp_instance下,MASTER与BACKUP必须使用相同的密码才能正常通信
auth_pass 1111
}
#VRRP HA 虚拟地址 如果有多个VIP,继续换行填写
#设置VIP,它随着state变化而增加删除,当state为master的时候就添加,当state为backup的时候则删除,由优先级决定
virtual_ipaddress {
192.168.182.157
}
#执行nginx检测脚本。注意这个设置不能紧挨着写在vrrp_script配置块的后面(实验中碰过的坑),否则nginx监控失效!!
track_script {
#引用VRRP脚本,即在 vrrp_script 部分指定的名字。定期运行它们来改变优先级,并最终引发主备切换。
chk_http_port
}
}