函数嵌套
一 嵌套定义
在Go语言中,定义在函数内部的函数必须是匿名函数
例1:
func f1() {
func(x int, y int) { fmt.Println(x + y) }(1, 2)
}
func main() {
f1() // 3
}例2:
func f2() func() {
return func() { fmt.Println("hello绿毛小乌龟") }
}
func main() {
f2()() // hello绿毛小乌龟
}二 嵌套调用
在函数内又调用了其他函数,即函数的嵌套调用
func f1() {
fmt.Println("from f1")
f2()
}
func f2() {
fmt.Println("from f2")
}
func main() {
f1()
}三 嵌套调用之递归调用
3.1 递归调用
递归调用是嵌套调用一种特殊形式,如果嵌套调用到了函数自己,就是递归调用。
详细地说:在调用一个函数时,该函数内又直接或者间接地调用了函数自身,称之为递归调用
例1:直接调用自己
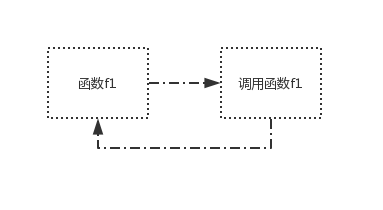
func f1() {
fmt.Println("from f1")
f1()
}
func main() {
f1()
}例2:间接调用自己
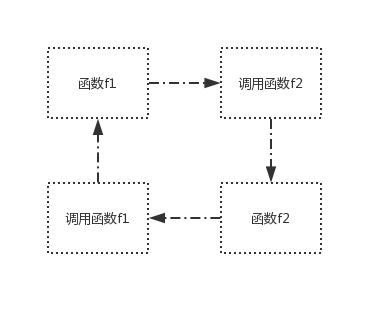
func f1() {
fmt.Println("from f1")
f2()
}
func f2() {
fmt.Println("from f2")
f1()
}
func main() {
f1()
}3.2 回溯与递推
递归其实就是用函数实现的循环,在3.1小节中,两个例子的递归调用都是一个无限循环的过程,而无限递归是没有意义的,因为
-
1、我们的问题通常都是在有限次数内就完成,不需要无限次递归
-
2、每调用一个函数就会在栈区新开辟一个栈、帧空间,这意味着无限递归会引发栈溢出问题fatal error: stack overflow
补充一个重要概念:栈、帧空间是什么?
1、帧: 函数调用会在内存形成一个"调用记录",又称"调用帧"(call frame),保存调用位置和内部变量等信息。 2、栈: 如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个["调用栈"]()(call stack)。 此外需知:栈、帧空间是一块受保护的独立空间,并且其他栈帧空间隔离
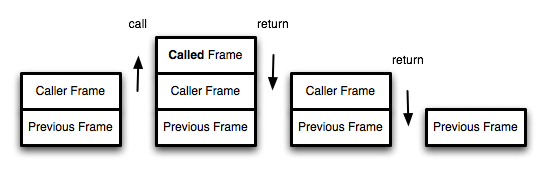
所以,我们必须让递归调用在满足某个特定条件下终止,即一个正确的递归调用应该分为两个阶段
-
1、回溯:向下一层一层递归调用下去
-
2、递推:回溯阶段遇到结束条件则结束,开始向上一层一层递推。回溯与递推的分水岭就是结束条件
下面我们用一个浅显的例子,为了让读者阐释递归的原理和使用:
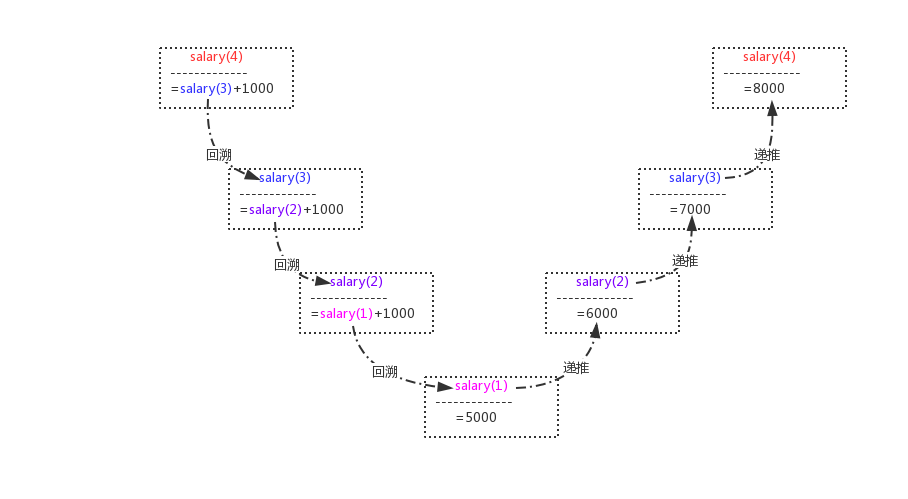
某公司四个员工坐在一起,问第四个人薪水,他说比第三个人多1000,问第三个人薪水,第他说比第二个人多1000,问第二个人薪水,他说比第一个人多1000,最后第一人说自己每月5000,请问第四个人的薪水是多少?
思路解析:
要知道第四个人的月薪,就必须知道第三个人的,第三个人的又取决于第二个人的,第二个人的又取决于第一个人的,而且每一个员工都比前一个多一千,数学表达式即:
salary(4)=salary(3)+1000
salary(3)=salary(2)+1000
salary(2)=salary(1)+1000
salary(1)=5000
总结为:
salary(n)=salary(n-1)+1000 (n>1)
salary(1)=5000 (n=1)很明显这是一个递归的过程,可以将该过程分为两个阶段:回溯和递推。
在回溯阶段,要求第n个员工的薪水,需要回溯得到(n-1)个员工的薪水,以此类推,直到得到第一个员工的薪水,此时,salary(1)已知,因而不必再向前回溯了。然后进入递推阶段:从第一个员工的薪水可以推算出第二个员工的薪水(6000),从第二个员工的薪水可以推算出第三个员工的薪水(7000),以此类推,一直推算出第第四个员工的薪水(8000)为止,递归结束。需要注意的一点是,递归一定要有一个结束条件,这里n=1就是结束条件。
代码实现
func salary(n int) int {
if n == 1 {
return 5000
}
return salary(n-1) + 5000
}
func main() {
s := salary(4)
fmt.Println(s)
}执行结果
8000程序分析:
在未满足n==1的条件时,一直进行递归调用,即一直回溯,见图的左半部分。而在满足n==1的条件时,终止递归调用,即结束回溯,从而进入递推阶段,依次推导直到得到最终的结果。
了解:
大部分编程语言使用固定大小的函数调用栈,常见的大小从64KB到2MB不等。固定大小栈会限制递归的深度(例如python),当你用递归处理大量数据时,需要避免栈溢出;除此之外,还会导致安全性问题。
而在Go语言中,使用的是可变栈,栈的大小按需增加(初始时很小),这意味着在go中使用递归时,大多数情况都不需要考虑溢出和安全问题,前提是你的递归有结束条件并且层级不是特别多,当然了,如果层级很多,也还是会栈溢出
salary(99999999) // fatal error: stack overflow3.3 了解尾递归优化
go不支持尾递归优化,下述概念了解即可
尾调用的概念非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
尾调用之所以与其他调用不同,就在于它的特殊的调用位置:尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
详见:
https://www.cnblogs.com/linhaifeng/articles/15812906.htmlGolang编译器针对尾递归没有优化,也就是说即便你按照上文把递归优化为尾递归,也还是会栈溢出
func f(n int) int {
if n == 1 {
return 1
}
return f(n - 1)
}
func main() {
f(999999999) // 报错:fatal error: stack overflow
}3.4 递归的总结
递归本质就是在做重复的事情,所以理论上递归可以解决的问题循环也都可以解决,只不过在某些情况下,使用递归会更容易实现,具体来讲只要一个问题可以满足下边三个条件,那就可以考虑使用递归
-
1、一个问题的解可以分解成几个规模更小的子问题的解
-
2、子问题除了数据规模不一样,求解思路必须完全一样
-
3、存在递归终止条件,把问题分解为子问题,把子问题再分解为子子问题,一层一层分解下去,不能存在无限循环,这就需要有终止条件
3.5 递归案例
写递归的代码,最关键的就是「写出递归公式、找到递归终止条件」,剩下的将递归公式转化成代码就简单了
例1:斐波那契数
- 请使用递归的方式,求出斐波那契数 1,1,2,3,5,8,13…
- 给你一个整数 n,求出它的斐波那契数是多少?
/*
请使用递归的方式,求出斐波那契数1,1,2,3,5,8,13...
给你一个整数n,求出它的斐波那契数是多少?
*/
func fbn(n int) int {
if (n == 1 || n == 2) {
return 1
} else {
return fbn(n - 1) + fbn(n - 2)
}
}
func main() {
res := fbn(3)
//测试
fmt.Println("res=", res)
fmt.Println("res=", fbn(4)) // 3
fmt.Println("res=", fbn(5)) // 5
fmt.Println("res=", fbn(6)) // 8
}例2:求函数值
- 已知 f(1)=3; f(n) = 2*f(n-1)+1;
- 请使用递归的思想编程,求出 f(n)的值?
func f(n int) int {
if n == 1 {
return 3
} else {
return 2 * f(n - 1) + 1
}
}
func main(){
//测试一下
fmt.Println("f(1)=", f(1))
fmt.Println("f(5)=", f(5))
}例3:猴子吃桃子问题**
- 有一堆桃子,猴子第一天吃了其中的一半,并再多吃了一个!以后每天猴子都吃其中的一半,然后再多吃一个。当到第十天时,想再吃时(还没吃),发现只有 1 个桃子了。问题:最初共多少个桃子?
//n 范围是 1 -- 10 之间
func peach(n int) int {
if n > 10 || n < 1 {
fmt.Println("输入的天数不对")
return 0 //返回0表示没有得到正确数量
}
if n == 10 {
return 1
} else {
return (peach(n + 1) + 1) * 2
}
}
func main() {
fmt.Println("第1天桃子数量是=", peach(1)) //1534
}