一 编程范式
很多初学者在了解了一门编程语言的基本语法和使用之后,面对一个’开发需求‘时仍然会觉得无从下手、没有思路/套路,本节主题“编程范式”正是为了解决该问题,那到底什么是编程范式呢?
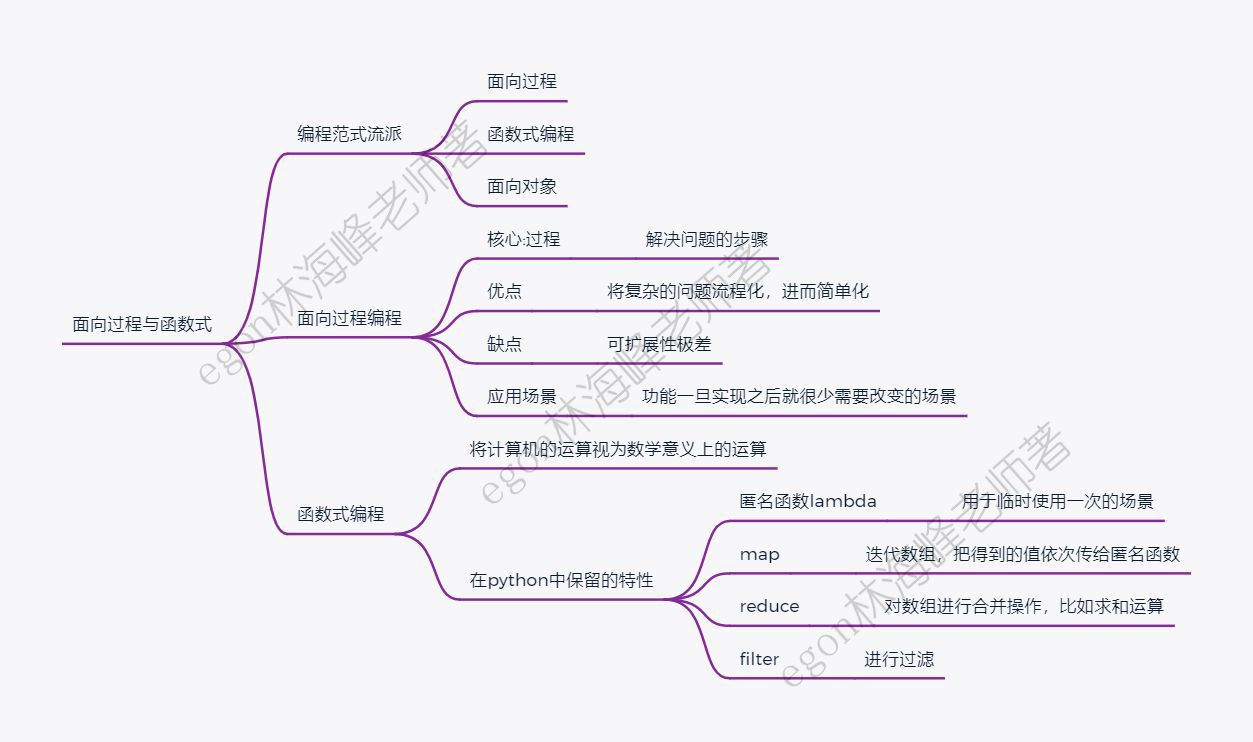
编程范式指的就是编程的套路,打个比方,如果把编程的过程比喻为练习武功,那编程范式指的就是武林中的各种流派,而在编程的世界里常见的流派有:面向过程、函数式、面向对象等,本节我们主要介绍前两者。
在正式介绍前,我们需要强调:“功夫的流派没有高低之分,只有习武的人才有高低之分“,在编程世界里更是这样,各种编程范式在不同的场景下都各有优劣,谁好谁坏不能一概而论,下面就让我们来一一解读它们。

二 面向过程
”面向过程“核心是“过程”二字,“过程”指的是解决问题的步骤,即先干什么再干什么……,基于面向过程开发程序就好比在设计一条流水线,是一种机械式的思维方式,这正好契合计算机的运行原理:任何程序的执行最终都需要转换成cpu的指令流水按过程调度执行,即无论采用什么语言、无论依据何种编程范式设计出的程序,最终的执行都是过程式的。

详细的,若程序一开始是要着手解决一个大的问题,按照过程式的思路就是把这个大的问题分解成很多个小问题或子过程去实现,然后依次调用即可,这极大地降低了程序的复杂度。举例如下:
写一个数据远程备份程序,分三步:本地数据打包,上传至云服务器,检测备份文件可用性
import os,time
# 一:基于本章所学,我们可以用函数去实现这一个个的步骤
# 1、本地数据打包
def data_backup(folder):
print("找到备份目录: %s" %folder)
print('正在备份...')
zip_file='/tmp/backup_%s.zip' %time.strftime('%Y%m%d')
print('备份成功,备份文件为: %s' %zip_file)
return zip_file
#2、上传至云服务器
def cloud_upload(file):
print("\nconnecting cloud storage center...")
print("cloud storage connected")
print("upload [%s] to cloud..." %file)
link='https://www.xxx.com/bak/%s' %os.path.basename(file)
print('close connection')
return link
#3、检测备份文件可用性
def data_backup_check(link):
print("\n下载文件: %s , 验证文件是否无损..." %link)
#二:依次调用
# 步骤一:本地数据打包
zip_file = data_backup(r"/Users/egon/欧美100G高清无码")
# 步骤二:上传至云服务器
link=cloud_upload(zip_file)
# 步骤三:检测备份文件的可用性
data_backup_check(link)
面向过程总结:
1、优点
将复杂的问题流程化,进而简单化2、缺点
'''
程序的可扩展性极差,因为一套流水线或者流程就是用来解决一个问题,就好比生产汽水的流水线无法生产汽车一样,即便是能,也得是大改,而且改一个组件,与其相关的组件可能都需要修改,比如我们修改了cloud_upload的逻辑,那么依赖其结果才能正常执行的data_backup_check也需要修改,这就造成了连锁反应,而且这一问题会随着程序规模的增大而变得越发的糟糕。
'''
def cloud_upload(file): # 加上异常处理,在出现异常的情况下,没有link返回
try:
print("\nconnecting cloud storage center...")
print("cloud storage connected")
print("upload [%s] to cloud..." %file)
link='https://www.xxx.com/bak/%s' %os.path.basename(file)
print('close connection')
return link
except Exception:
print('upload error')
finally:
print('close connection.....')
def data_backup_check(link): # 加上对参数link的判断
if link:
print("\n下载文件: %s , 验证文件是否无损..." %link)
else:
print('\n链接不存在')3、应用场景
面向过程的程序设计一般用于那些功能一旦实现之后就很少需要改变的场景, 如果你只是写一些简单的脚本,去做一些一次性任务,用面向过程去实现是极好的,但如果你要处理的任务是复杂的,且需要不断迭代和维护, 那还是用面向对象最为方便。
三 函数式
函数式编程并非用函数编程这么简单,而是将计算机的运算视为数学意义上的运算,比起面向过程,函数式更加注重的是执行结果而非执行的过程,代表语言有:Haskell、Erlang。而python并不是一门函数式编程语言,但是仍为我们提供了很多函数式编程好的特性,如lambda,map,reduce,filter

3.1 匿名函数与lambda
对比使用def关键字创建的是有名字的函数,使用lambda关键字创建则是没有名字的函数,即匿名函数,语法如下
lambda 参数1,参数2,...: expression举例
# 1、定义
lambda x,y,z:x+y+z
#等同于
def func(x,y,z):
return x+y+z
# 2、调用
# 方式一:
res=(lambda x,y,z:x+y+z)(1,2,3)
# 方式二:
func=lambda x,y,z:x+y+z # “匿名”的本质就是要没有名字,所以此处为匿名函数指定名字是没有意义的
res=func(1,2,3)
匿名函数与有名函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,所以匿名函数用于临时使用一次的场景,匿名函数通常与其他函数配合使用,我们以下述字典为例来介绍它
salaries={
'siry':3000,
'tom':7000,
'lili':10000,
'jack':2000
}要想取得薪水的最大值和最小值,我们可以使用内置函数max和min(为了方便开发,python解释器已经为我们定义好了一系列常用的功能,称之为内置的函数,我们只需要拿来使用即可)
>>> max(salaries)
'tom'
>>> min(salaries)
'jack'内置max和min都支持迭代器协议,工作原理都是迭代字典,取得是字典的键,因而比较的是键的最大和最小值,而我们想要的是比较值的最大值与最小值,于是做出如下改动
# 函数max会迭代字典salaries,每取出一个“人名”就会当做参数传给指定的匿名函数,然后将匿名函数的返回值当做比较依据,最终返回薪资最高的那个人的名字
>>> max(salaries,key=lambda k:salaries[k])
'lili'
# 原理同上
>>> min(salaries,key=lambda k:salaries[k])
'jack'同理,我们直接对字典进行排序,默认也是按照字典的键去排序的
>>> sorted(salaries)
['jack', 'lili', 'siry', 'tom']