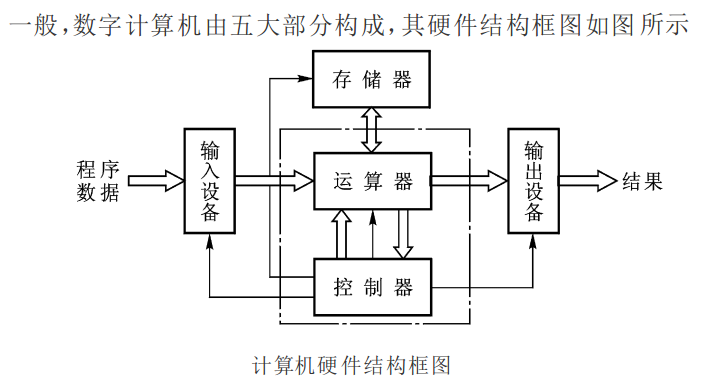
导语

随着人工智能的快速发展,各种智能化的需求也是层出不穷,像小米的小爱同学,iphone的siri,都可以将用户说出来的话转换成具体的操作执行。
现在有这样一个需求,将一段视频转换为文字存入文件当中,想想我们都玩了这么久的python了,而python作为人工智能的首选语言,肯定要使用python来实现这个需求,接下来就来看看如何实现它。
需求分析

安装工具
pip install ffmpy3
pip install baidu-aip
pip install pydub实现思路
1、提取文字
按照需求吗,我们的的最终目的就是要获取视频中的文字,在一段视频当中包含文字信息的其实不是视频文件而是音频文件,所以我们需要解决的问题就是如何进行语音识别。
如果说由我们自己编写从视频中提取文字的逻辑代码,肯定是非常费劲的,但是关于语音识别部分的功能,腾讯/百度/科大讯飞/等大厂都提供了自己的API,各位是可以凭借自己的喜好选择。以下示例都是使用的百度的API。
首先第一步,我们需要知道百度的语音识别功能怎么使用,对视频文件有什么需求。以下就是百度python SDK的文档页面:
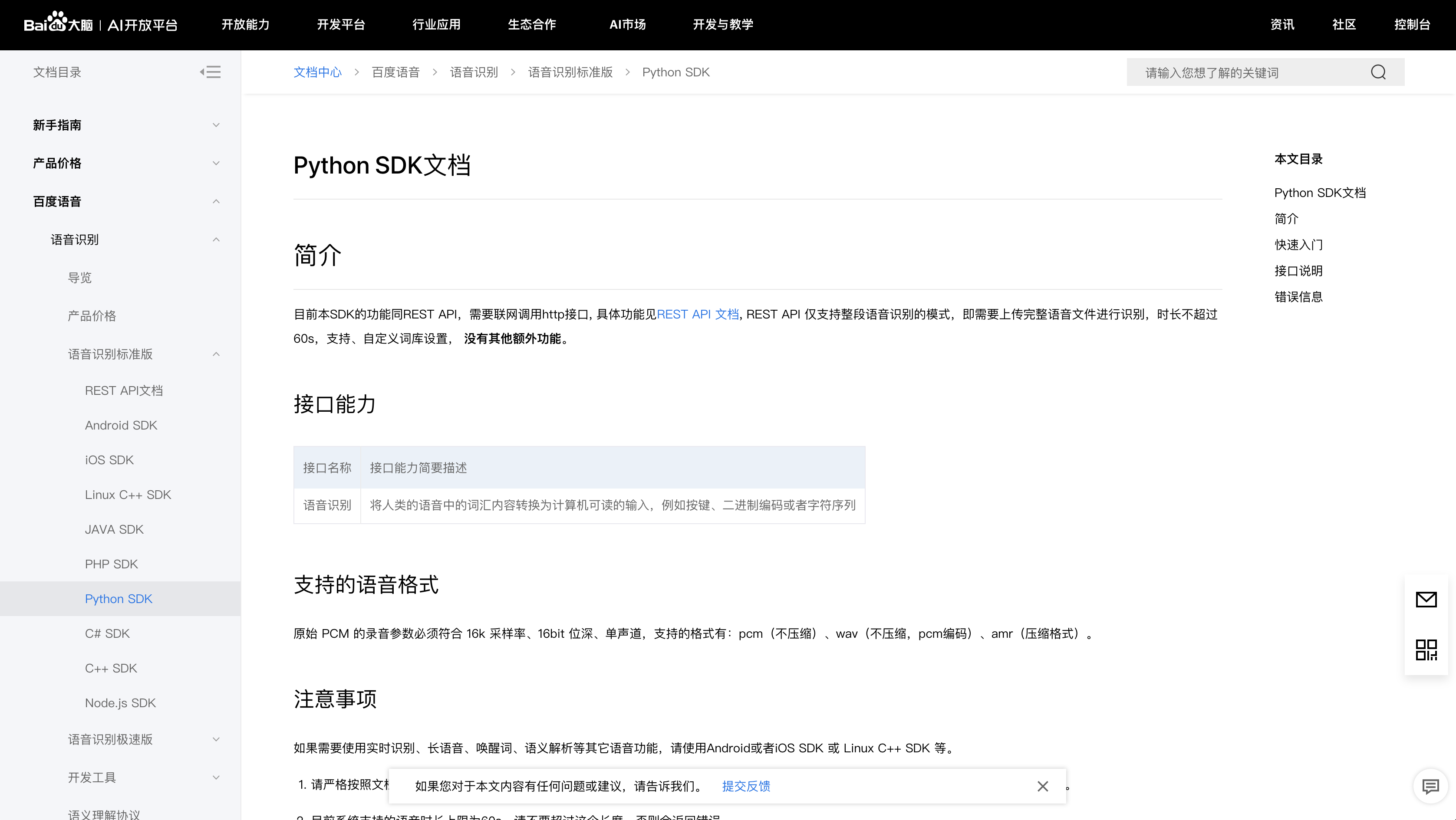
在这个文档中,对百度语音识别API所支持的音频格式进行了明确,概况起来主要有三点要求:
- 参数:16k 采样率、16bit 位深、单声道;
- 格式:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式);
- 其他:完整语音文件,时长不超过60s。
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
client.asr(get_file_content('audio.pcm'), 'pcm', 16000, {
'dev_pid': 1536,
})2、提取音频
音频转文字的需求我们通过百度的借口解决了,接着要解决的就是把目标视频文件转换为百度API所支持的音频(对应格式,参数)。
将视频文件的音频转换为对应格式的编码,在百度中也有说明:
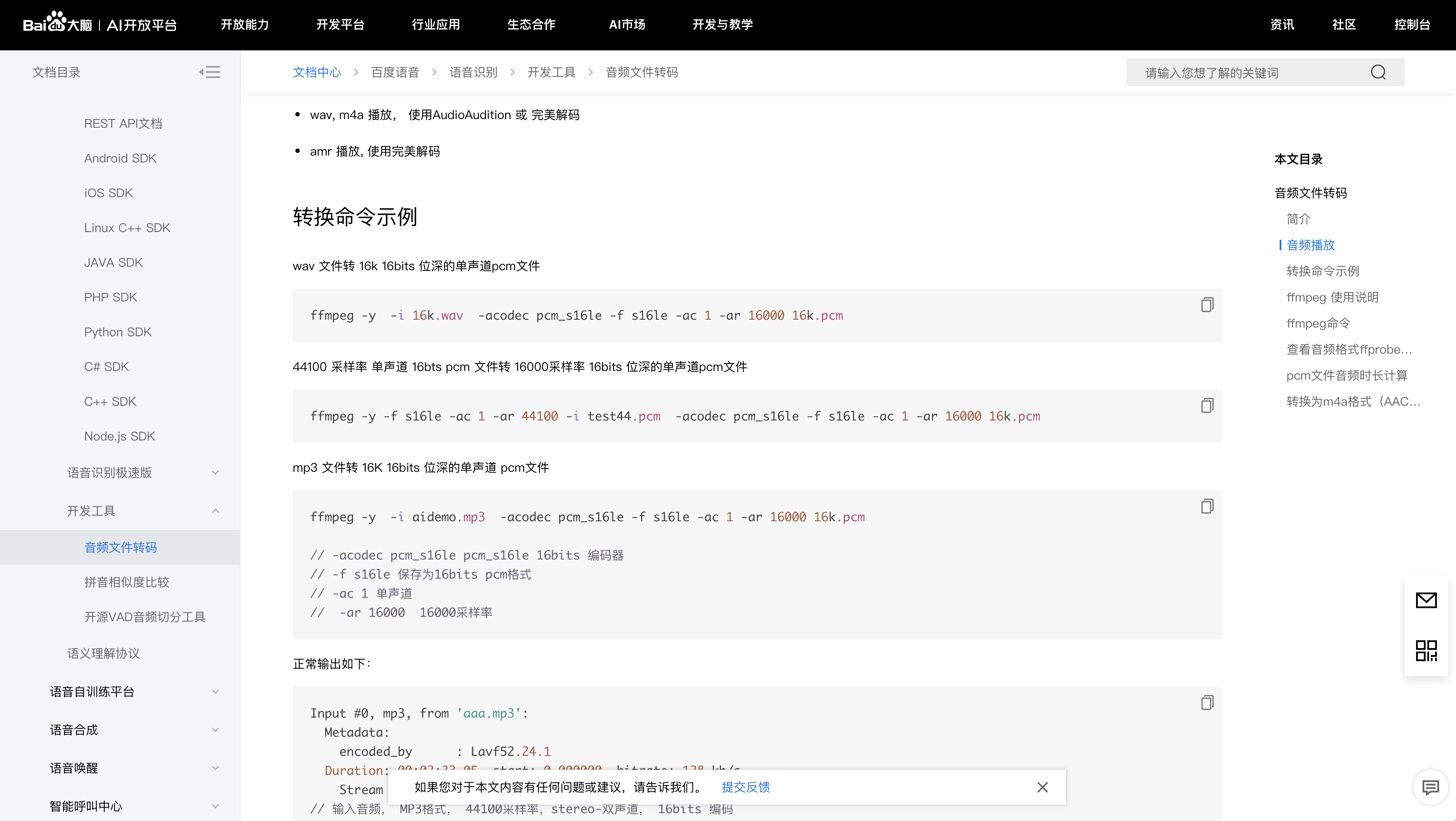
我们可以通过f fmpeg对视频文件进行转码,转换成音频:
ffmpeg -y -i 16k.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm上面这条语句的作用是把wav文件转换为16k、16bits位深的单声道pcm文件,其中16k.wav是输入文件、16k.pcm是输出文件,两者之间的内容是输出文件的参数设置。
在音频提取过程中还要对音频的采样率、声道数、码率进行设置,同时指定输出音频格式。除此之外,由于百度API最多只支持60秒长度的音频,而我们需要转换的视频长度通常要远高于这个时长,所以还需要使用pydub对音频文件进行切割,然后分段进行文字转换。所以从视频到音频的大概流程应该是这样的:
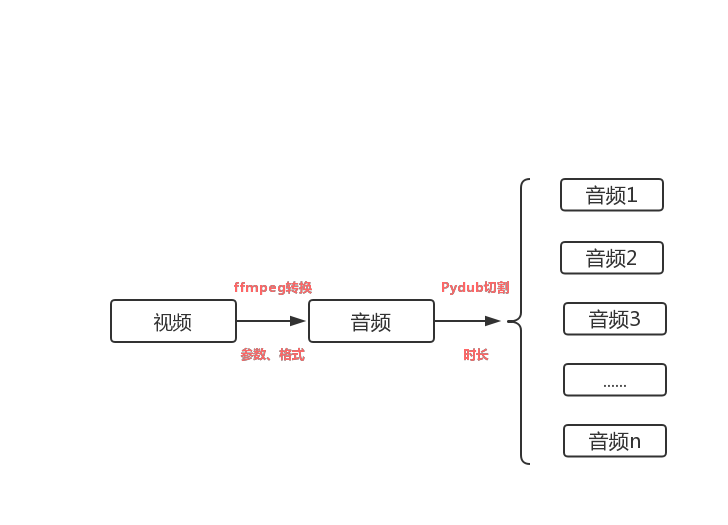
明确完思路之后,接下来就可以一步一步具体实现视频转文字的功能了。
代码实现
1、视频转音频
在python中使用ffmpeg需要借助于ffmpy3这个库,语法格式也要做稍许调整。来看下面这段代码,他的作用是把一段视频转换为wav文件:
- 其中inputfile是待转换的视频文件,其参数为空;
- outputfile是输出文件路径,其参数中对采样率、声道数以及文件格式等进行了指定;
- global_options是全局参数,
-y的作用是允许覆盖已有文件;
# 视频转wav音频
def video_to_wav(file):
input_file = file
file_type = file.split(".")[-1]
print(file_type)
output_file = input_file.replace(file_type, "wav")
ff = FFmpeg(inputs={input_file: None},
global_options=['-y'],
outputs={output_file: '-vn -ar 16000 -ac 1 -ab 192 -f wav'})
print(ff.cmd)
ff.run()
return output_file