一 容器内的两个特殊进程
1.1 介绍
容器正常启动后,使用docker exec contaienrID bash进入容器后,使用ps命令,一般有两个特殊进程:
- 1号进程 为容器首启动进程,容器的pid namespcae就是由1号进创建的,容内其余进程基本都是首启动进程的子孙进程。只要1号进程挂掉那容器便会关闭,pid namespace会被回收。
- 0号进程 为1号进程的父进程,也为
docker exec....携带指令的父进程(即从外部向running容器内发起的指令)。当然你要干掉了0号进程,容器一样完蛋,
一个案例带你快速看一眼0号进程与1号进程
1、tail -f /dev/null是容器内的1号进程,而1号进程的父进程则是0号进程
2、docker exec执行的命令是sh,该命令是在容器已经running之后运行的,产生的sh进程的父进程为0号进程
3、在sh环境里执行的新命令如下所示sleep 1000 &,当然都是sh的儿子
[root@test01 init5]# docker container run -d --name test centos:7 tail -f /dev/null
[root@test01 init5]#
[root@test01 init5]# docker exec -ti test sh
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:27 ? 00:00:00 tail -f /dev/null
root 6 0 0 04:27 pts/0 00:00:00 sh
root 13 6 0 04:27 pts/0 00:00:00 ps -ef
sh-4.2#
sh-4.2# sleep 1000 &
[1] 14
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:27 ? 00:00:00 tail -f /dev/null
root 6 0 0 04:27 pts/0 00:00:00 sh
root 14 6 0 04:27 pts/0 00:00:00 sleep 1000
root 15 6 0 04:28 pts/0 00:00:00 ps -ef
sh-4.2# 1.2 容器内的0号进程
=====>对于linux系统来说:
linux启动的第一个进程是0号进程,是静态创建的
在0号进程启动后会接连创建两个进程,分别是1号进程和2和进程。
1号进程最终会去调用可init可执行文件,init进程最终会去创建所有的应用进程。
2号进程会在内核中负责创建所有的内核线程
所以说0号进程是1号和2号进程的父进程;1号进程是所有用户态进程的父进程;2号进程是所有内核线程的父进程。
===========>对于容器来说:
在容器平台上,无论你是用k8s去删除一个pod,或者用docker关闭一个容器,都会用到Containerd这个服务,
-
在k8s里,创建pod会时,kubelet收到创建pod的请求后,会调用
dockerDaemon发起创建容器请求,然后由containerd接收并调用 containerd/runc功能来创建containerd-shim进程, -
如果只是用docker创建容器,那就是直接调用dockerDaemon发起创建容器请求,然后由
containerd接收并调用 containerd/runc功能来创建containerd-shim进程
containerd-shim就是上面提到的0号进程,关于containerd-shim需要掌握3个关键知识点
-
1、实际的创建容器、容器内执行指令等都其实都是由
containerd-shim进程在做。 -
2、
containerd-shim进程是容器的爹,具备回收僵尸儿子的功能,容器1号进程退出后,内核清理其下子孙进程,这些子孙进程就会被containerd-shim收养并清理。但如果容器内的1号进程不被Kill,那么其下进程如果有僵尸进程,是无法被处理的。所以用户开发的容器首进程要注意回收退出进程 -
3、Containerd在stop停止容器的时候,会向容器的1号进程发送一个-15信号,如果容器内的1号进程没有信号转发能力,那在回收pid namespce时会向该namespace里的所有其他进程发送SIGKILL信号信号强制杀死。这是有问题的,后续我们将详细介绍
启动一个容器
docker run -d --name test1 centos:7 sh -c "(sleep 10d &) ; tail -f /dev/null"如何查看容器内0号进程对应宿主机的pid号
[root@node1 ~]# docker container ls |grep test1 | awk '{print $1}'
09e4114ddd9d
# 注意,下面查看的是容器内部0号进程,对应宿主机上的pid号
[root@node1 ~]# ps aux |grep containerd-shim |grep 09e4114ddd9d
root 5439 0.0 0.6 712056 12836 ? Sl 12:27 0:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 09e4114ddd9d9747244352637949ade8c61082627984b3381d37a589d92c4bc3 -address /run/containerd/containerd.sock
如果你干死了容器的containerd-shim进程,那站在操作系统角度,容器下的所有进程都被操作系统的init收养然后回收了如何查看容器内1号进程对应物理机的pid号,我们后续会在物理机用strace命令追踪容器内1号进程收到的信号,需要提前知晓下述方式
[root@node1 ~]# docker container ls |grep test1 | awk '{print $1}'
09e4114ddd9d
[root@node1 ~]# docker inspect 09e4114ddd9d |grep -i pid
"Pid": 5458,
"PidMode": "",
"PidsLimit": null,如何查看容器内其他进程在宿主机中的PID
[root@node1 ~]# docker container ls |grep test1 | awk '{print $1}'
09e4114ddd9d
# 注意,下面查看的是容器内部的进程对应宿主机对应的pid号,具体查看目录可能是system.slice或docker目录
[root@node1 ~]# cat /sys/fs/cgroup/memory/system.slice/docker-09e4114ddd9d9747244352637949ade8c61082627984b3381d37a589d92c4bc3.scope/cgroup.procs
5458
5484
5485
# 上述结果包含了容器内1号进程在宿主机的映射,要确定其他进程号与容器内进程的对应关系,可以在宿主机上用ps aux |grep 号码,来过滤进行确认
=============》宿主机
[root@node1 ~]# ps aux |grep 5458 |grep -v grep
root 5458 0.0 0.0 11688 1336 ? Ss 12:27 0:00 sh -c (sleep 10d &) ; tail -f /dev/null
[root@node1 ~]# ps aux |grep 5484 |grep -v grep
root 5484 0.0 0.0 4364 356 ? S 12:27 0:00 sleep 10d
[root@node1 ~]# ps aux |grep 5485 |grep -v grep
root 5485 0.0 0.0 4400 352 ? S 12:27 0:00 tail -f /dev/null
=============》在容器内,看一眼与上面的对应关系
可以执行docker exec -ti test1 sh进入容器内执行ps -ef来查看与上面的的结果是一一对应的
补充:
由于容器采用了Linux的namespace机制, 对pid进行了隔离. 因此容器内的pid将会从1开始重新编号, 并且不会看到其他容器或宿主机的进程pid。本质上容器就是宿主机上的一个普通的Linux进程, 因此在宿主机中是可以看到容器内进程的pid, 只不过这个pid是在宿主机上显示的, 而非容器内的(因为隔离了)
[root@node1 ~]# docker exec -ti test1 sh
sh-4.2# ps -elf
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 2922 do_wai 04:27 ? 00:00:00 sh -c (sleep 10d &) ; tail -f /dev/null
0 S root 8 1 0 80 0 - 1091 hrtime 04:27 ? 00:00:00 sleep 10d
0 S root 9 1 0 80 0 - 1100 wait_w 04:27 ? 00:00:00 tail -f /dev/null
4 S root 10 0 0 80 0 - 2956 do_wai 04:35 pts/0 00:00:00 sh
4 R root 16 10 0 80 0 - 12933 - 04:35 pts/0 00:00:00 ps -elf
小结:
-
每启动一个容器都会在宿主机产生一个docker-shim进程,它就是容器内的0号进程,是容器内1号进程的爹
-
当容器已经running之后,我们exec进入容器里执行命令产生的新进程,都是0号进程的儿子,而不是1号进程的儿子。所以说容器中的1号进程并不会像宿主机的1号进程那样直接或间接地领导所有其它进程;
-
docker top 显示的容器中的进程可能不太全,与是否该进程归属于1号进程没有任何关系;与进程是否最终归属于该容器的管理进程docker-containerd-shim也没有关系,如果是nsenter进入容器,则启动的进程在docker top中是看不到的,虽然该进程在容器中显示的ppid也是0,其实同样是0的ppid却可能不是同一个进程,因为,只要父进程在容器外部,则容器内部显示的ppid就统一为0; 为什么docker top可能看到的不全?docker top是如何实现的呢?参看: https://phpor.net/blog/post/4420
1.3 容器内的1号进程
1.3.1 完整操作系统的1号进程
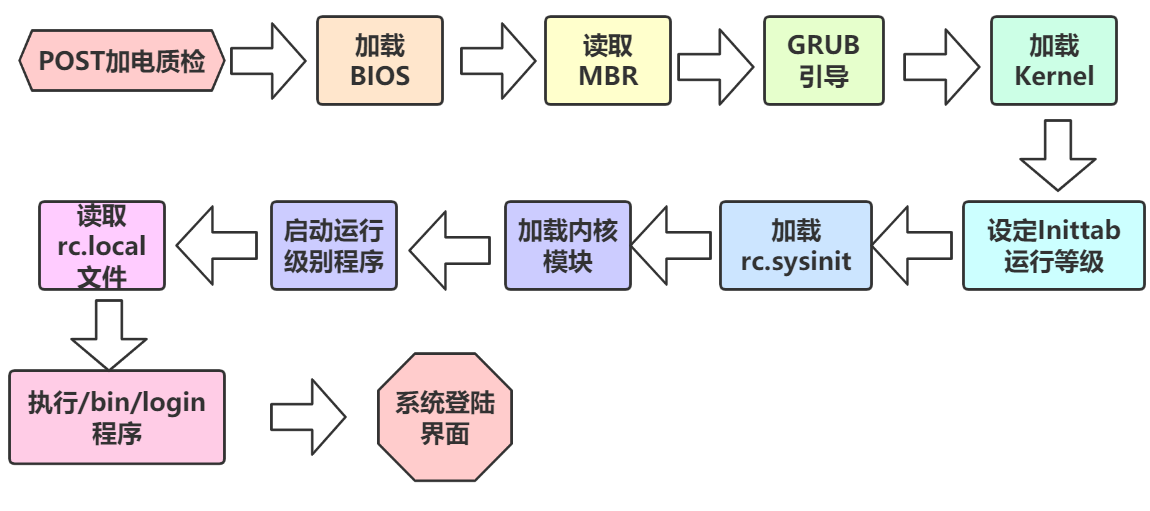
先不提容器,就以物理机上运行的那个完整的操作系统为例:
一个 Linux 操作系统的启动流程
1、通电后,执行 BIOS
2、找到启动盘
3、bios根据自己的配置,找到启动盘,读取第一个扇区512bytes,即mbr的内容,这里放的前446是boot-loader程序,后64是分区信息,后2字节是结束的标志位
4、 bootloader 负责把磁盘里的内核读入内存执行
Linux 内核执行文件一般会放在 /boot 目录下,文件名类似 vmlinuz*,如下
[root@yq01-aip-aikefu19 base]# ls /boot/|grep vm
vmlinuz-0-rescue-53574fee080a44d49195c9f831019258
vmlinuz-3.10.0-514.el7.x86_64
vmlinuz-4.17.11-1.el7.elrepo.x86_645、在内核完成了系统的各种初始化之后,这个程序需要执行的第一个用户态程就是 init 进程,PID号为1,该进程是系统中所有其他进程的祖宗,在centos6中该祖宗进程称之为init,在centos7之后该祖宗进程名为systemd。
即:操作系统启动时是先执行内核态代码,然后在内核里调用1号进程的代码,从内核态切换到用户态
ps:目前linux的好嗯多发行版,如红帽、debian等,都会把/sbin/init作为软连接指向Systemd,Systemd是目前最流行
的linux init进程,在此之前还有SysVinit、UpStart等linux init进程
但无论是哪种 Linux init 进程,它最基本的功能都是创建出 Linux 系统中其他所有的进 程,并且管理这些进程**
在 Linux 上有了容器的概念之后,一旦容器建立了自己的 Pid Namespace(进程命名空 间),这个 Namespace 里的进程号也是从 1 开始标记的。所以,容器的 init 进程也被称 为 1 号进程。
1 号进程是第一个 用户态的进程,由它直接或者间接创建了 Namespace 中的其他进程。总结操作系统的1号进程拥有如下特点
- 1、它是系统的第一个进程,负责产生其他所有用户进程。
- 2、init 以守护进程方式存在,是所有其他进程的祖先。
操作系统的1号进程拥有如下重要功能
-
1、启动守护进程
-
2、收养孤儿
-
3、会定期发起wait或waitpid的功能去回收成为僵尸的儿子(这不是该进程独有的功能,但它的确有该功能)
-
4、将操作系统信号转发给子进程
1.3.2 容器内的1号进程
然后我们再来说一下容器,容器内的操作系统来自于镜像,而镜像并非一个完整的操作系统(只拥有rootfs),通常docker的镜像为了节省空间,是没有安装systemd或者sysvint这类初始化系统的进程的,所以当启动容器时,我们CMD执行的命令是啥,容器里的1号进程就是啥,
# 以下dockerfile为例,当docker容器启动时,PID 1即容器启动程序将会是nginx,
FROM nginx
ENTRYPOINT ["nginx", "-c"]
CMD ["/etc/nginx/nginx.conf"]容器内的1号进程与操作系统的1号进程的相同点与不同点如下
-
1、相同之处
只要容器里的1号进程停止,容器就会结束,就好比是操作系统的1号进程挂掉操作系统就挂掉了是一个道理。所以容器里的1号进程应该是一个一直运行不会停止的进程,而且必须在在前台运行,总结一下就是:1号进程需要在前台一直运行。
示例1
# 错误示范1:容器的1号进程不是一直运行的 # 1.1 run.sh内容 echo "123" # 1.2 dockerfile内容 FROM centos:7 ADD run.sh /opt CMD sh /opt/run.sh # 1.3 构建镜像 docker build -t test:v1 ./ # 1.4 启动测试 docker container run -d --name test111 test:v1 # 1.5 会发现容器启动之后立刻挂掉 [root@test01 test]# docker container ls -a |grep test111 ...... Exited (0) 33 seconds ago ......示例2
# 错误示范2:容器的1号进程放在了后台运行,那么无论它里面是啥代码,也都是一下就运行过去了,然后运行下一行代码,发现没有,容器也就结束了 # 2.1 run.sh 内容 while true;do echo 123 >> /tmp/a.log;sleep 1;done # 2.2 dockerfile内容 FROM centos:7 ADD run.sh /opt CMD sh /opt/run.sh & # 2.3 构建镜像 docker build -t test:v2 ./ # 2.4 启动测试 docker container run -d --name test222 test:v2 # 2.5 会发现容器启动之后立刻挂掉 [root@test01 test]# docker container ls -a |grep test222 ...... Exited (0) 33 seconds ago ......示范3:
# 正确示范:CMD的代码放到一个文件里然后运行也是一样,只要是在前台然后一直运行就都可以 # 3.1 run.sh 内容 while true;do echo 123 >> /tmp/a.log;sleep 1;done # 3.2 dockerfile内容 FROM centos:7 ADD run.sh /opt CMD sh /opt/run.sh # 3.3 构建镜像 docker build -t test:v3 ./ # 3.4 启动测试 docker container run -d --name test333 test:v3 # 3.5 会发现容器正常启动,可以切入到容器里查看 docker exec -ti test333 sh -
2 、不同之处
我们为容器启动的1号进程通常不具备操作系统的init进程一样的功能
- 比如收养孤儿,定期发起wait或waitpid系统调用来回收僵尸儿子
- 再比如信号转发的功能,我们接下来会先介绍回收僵尸儿子,然后再介绍信号转发。
补充说明:
我们建议容器设计原则是一个容器只运行一个进程,但在现实工作中往往做不到,还是会生出一些子进程,
操作系统的init进程是操作系统的开发者开发的,它有一个非常重要的功能就是:会充当孤儿院的作用去回收孤儿进程,并且会定期发起wait或者waitpid的系统调用去回收僵尸的儿子,但是你容器里的1号是你开发的,你摸着自己的良心问问自己有没有实现上面的功能,没有吧,所以你的容器里有僵尸进程而无法被回收也就一点也不奇怪了,那容器里一旦产生僵尸进程该如何应对呢?带着这些疑问往后看吧
二 储备知识僵尸进程与孤儿进程
2.1 linux系统中进程的状态
在linux系统中,无论是进程还是线程,内核转给你都是用task_struct{}结构体来表示的,称之为任务task,task是linux里基本的调度单位,我们通过ps aux会查看到一系列进程的状态,其实就是task的状态。
进程的状态分为两大类,活着的与死亡的
- 一、活着的
- 1.1 运行着的进程
- (1)、运行态,正占用着cpu资源在运行着,状态为R
- (2)、就绪态,没有申请到cpu资源,处于运行队列中,一旦申请到cpu就可以立即投入运行,状态也为R
- 1.2 睡眠的进程
- (1)、可中断睡眠(TASK_INTERRUPTIBLE),状态为S,等待某个资源而进入的状态,比如等待本地或网络用户输入,也可以等待一个信号量(Semaphore),执行的IO操作可以得到硬件设备的响应
- (2)、不可中断睡眠(TASK_UNINTERRUPTIBLE),状态为D,处于睡眠状态,但是此刻进程是不可中断的,意思是不响应异步信号,执行的IO操作得不到硬件设备的响应(可能是因为硬件繁忙,因此导致内存里的一些缓存数据无法及时刷入磁盘,所以肯定不允许你中断该睡眠状态,并且你会发现处于D状态的进程kill -9竟然也杀不死,就是为了保证数据安全)
- 二、死亡的:即执行do_exit()结束进程
- (1)EXIT_DEAD:也就是进程真正结束退出那一瞬间的状态,通常我们看不到,因为很快就没了
- (2)EXIT_ZOMBIE,这个是进程进入EXIT_DEAD状态前的一个状态,该状态称之为僵尸进程,状态显示为Z,也就是说所有进程在死前都会进入僵尸进程的状态。
强调:我们接下来要讨论的,是僵尸进程的残留问题,而不是僵尸进程的产生问题,所有的进程在死前都会进入僵尸进程的状态,它的父进程负责回收该状态,若没有及时回收,就会残留,至于残留后有何影响、如何回收等问题详解如下
2.2 僵尸进程详解
#1、什么是僵尸进程
操作系统负责管理进程
我们的应用程序若想开启子进程,都是在向操作系统发送系统调用
当一个子进程开启起来以后,它的运行与父进程是异步的,彼此互不影响,谁先死都不一定
linux操作系统的设计规定:父进程应该具备随时获取子进程状态的能力
如果子进程先于父进程运行完毕,此时若linux操作系统立刻把该子进程的所有资源全部释放掉,那么父进程来查看子进程状态时,会突然发现自己刚刚生了一个儿子,但是儿子没了!!!
这就违背了linux操作系统的设计规定
所以,linux系统出于好心,若子进程先于父进程运行完毕/死掉,那么linux系统在清理子进程的时候,会将子进程占用的重型资源都释放掉(比如占用的内存空间、cpu资源、打开的文件等),但是会保留一部分子进程的关键状态信息,比如进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等,此时子进程就相当于死了但是没死干净,因而得名"僵尸进程",其实僵尸进程是linux操作系统出于好心,为父进程准备的一些子进程的状态数据,专门供父进程查阅,也就是说"僵尸进程"是linux系统的一种数据结构,所有的子进程结束后都会进入僵尸进程的状态
# 2、那么问题来了,僵尸进程残存的那些数据不需要回收吗???
当然需要回收了,但是僵尸进程毕竟是linux系统出于好心,为父进程准备的数据,至于回收操作,应该是父进程觉得自己无需查看僵尸进程的数据了,父进程觉得留着僵尸进程的数据也没啥用了,然后由父进程发起一个系统调用wait / waitpid来通知linux操作系统说:哥们,谢谢你为我保存着这些僵尸的子进程状态,我现在用不上他了,你可以把他们回收掉了。然后操作系统再清理掉僵尸进程的残余状态,你看,两者配合的非常默契,但是,怕就怕在。。。
# 3、分三种情况讨论
1、linux系统自带的一些优秀的开源软件,这些软件在开启子进程时,父进程内部都会及时调用wait/waitpid来通知操作系统回收僵尸进程,所以,我们通常看不到优秀的开源软件堆积僵尸进程,因为很及时就回收了,与linux系统配合的很默契
2、一些水平良好的程序员开发的应用程序,这些程序员技术功底深厚,知道父进程要对子进程负责,会在父进程内考虑调用wait/waitpid来通知操作系统回收僵尸进程,但是发起系统调用wait/waitpid的时间可能慢了些,于是我们可以在linux系统中通过命令查看到僵尸进程状态
[root@egon ~]# ps aux | grep [Z]+
3、一些垃圾程序员,技术非常垃圾,只知道开子进程,父进程也不结束,就在那傻不拉几地一直开子进程,也压根不知道啥叫僵尸进程,至于wait/waitpid的系统调用更是没听说过,这个时候,就真的垃圾了,操作系统中会堆积很多僵尸进程,此时我们的计算机会进入一个奇怪的现象,就是内存充足、硬盘充足、cpu空闲,但是,启动新的软件就是无法启动起来,为啥,因为操作系统负责管理进程,每启动一个进程就会分配一个pid号,而pid号是有限的,正常情况下pid也用不完,但怕就怕堆积一堆僵尸进程,他吃不了多少内存,但能吃一堆pid
# 4、如果清理僵尸进程
针对情况3,只有一种解决方案,就是杀死父进程,那么僵尸的子进程会被linux系统中pid为1的顶级进程(init或systemd)接管,顶级进程很靠谱、它是一定会定期发起系统调用wait/waitpid来通知操作系统清理僵尸儿子的
针对情况2,可以发送信号给父进程,通知它快点发起系统调用wait/waitpid来清理僵尸的儿子
kill -CHLD 父进程PID
# 5、结语
僵尸进程是linux系统出于好心设计的一种数据结构,一个子进程死掉后,相当于操作系统出于好心帮它的爸爸保存它的遗体,之说以会在某种场景下有害,是因为它的爸爸不靠谱,儿子死了,也不及时收尸(发起系统调用让操作系统收尸)
说白了,僵尸进程本身无害,有害的是那些水平不足的程序员,他们总是喜欢写bug,好吧,如果你想看看垃圾程序员是如何写bug来堆积僵尸进程的,你可以看一下这篇博客https://www.cnblogs.com/linhaifeng/articles/13567273.html再次强调:父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈,只能是儿子,只能是儿子,只能是儿子
再次强调:父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈,只能是儿子,只能是儿子,只能是儿子
再次强调:父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈,只能是儿子,只能是儿子,只能是儿子
再次强调:父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈,只能是儿子,只能是儿子,只能是儿子
再次强调:父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈,只能是儿子,只能是儿子,只能是儿子
2.3 僵尸进程示例代码
先储备一个知识,看如下代码
#coding:utf-8
from multiprocessing import Process
import os
import time
def task(n):
print("father--->%s son--->%s" %(os.getppid(),os.getpid()))
time.sleep(n)
if __name__ == "__main__":
# 首选必须知道一个知识点:一个python进程,就是一个python解释器进程,你的python代码本质都是字符串最终运行与调用的
# 其实都是解释器的代码
# 对于开启的子进程,即便你不去执行p.join()方法,也不用担心,因为只要python解释器还在运行着,它就会定期定期定期,
# 注意是定期,去执行
# 回收僵尸进程的功能,
# 当如果你没有执行p.join(),同时也time.sleep(100000)住了主进程,那肯定就没有人来回收僵尸儿子了
# 所以,如果你开启了一千个子进程,每个子进程都是运行一行打印功能然后在极短的时间内进入僵尸进程状态
# 主进程在一个个开启这一千个子进程的过程中就会定期回收一部分僵尸儿子,当运行到最后执行到time.sleep(100000)时,主进程就停住了
# 剩下的没来得及回收的僵尸儿子也就残留了,此处我想告诉大家的就是这件事,你不要以为你开一千个子进程每个都很快结束,然后最后你就
# 会看到一千个僵尸儿子
for i in range(1000):
Process(target=task,args=(0,)).start()
time.sleep(100000)上述代码你去执行一下,只会看到有几个僵尸进程残留。
综上,我们的用来产生僵尸进程的代码示范如下,先让子进程运行一小会不要立刻结束(否则立即产生的僵尸进程,极有可能会被正在跑着的主进程回收了),然后等所有儿子都开启了之后,主进程执行time.sleep(100000)后彻底停住、不会执行任何定期回收僵尸儿子的任务了。此时就可以静静等着撕掉的儿子,每死一个就产生一个僵尸
=====================窗口1中======================
[root@egon ~]# cat test.py
#coding:utf-8
from multiprocessing import Process
import os
import time
def task(n):
print("father--->%s son--->%s" %(os.getppid(),os.getpid()))
time.sleep(n)
if __name__ == "__main__":
p1=Process(target=task,args=(10,))
p2=Process(target=task,args=(10,))
p3=Process(target=task,args=(10,))
p1.start()
p2.start()
p3.start()
print("main--->%s" %os.getpid())
time.sleep(10000)
[root@egon ~]# python test.py &
[5] 104481
[root@egon ~]# main--->104481
father--->104481 son--->104482
father--->104481 son--->104483
father--->104481 son--->104484
=====================窗口2中:大概过个十几秒后查看======================
[root@egon ~]# ps aux |grep Z
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 104482 0.0 0.0 0 0 pts/2 Z 18:24 0:00 [python] <defunct>
root 104483 0.0 0.0 0 0 pts/2 Z 18:24 0:00 [python] <defunct>
root 104484 0.0 0.0 0 0 pts/2 Z 18:24 0:00 [python] <defunct>
root 104488 0.0 0.0 112828 960 pts/4 R+ 18:24 0:00 grep --color=auto Z
=====================如下,我们可以看到僵尸对应的资源都已经没有了======================
# cat /proc/104482/cmdline
# cat /proc/104482/smaps
# cat /proc/104482/maps
# ls -l /proc/104482/fd
任何进程的退出都是调用do_exit()系统接口,do_exit()内部会释放进程task_struct里的mm/shm/sem/files等文件资源,只留下一个stask_struct instance空壳,如上所示
并且,这个进程也已经不响应任何的信号了,无论 SIGTERM(15) 还是 SIGKILL(9)
kill -9 104482
kill -15 104482
ps aux |grep Z # 会发现104482这个僵尸进程依然存在
# 补充
可以去查看p1.join()的代码,里面有一个关于wait的调用,在主进程里调用p1.join()的目的就是等子进程挂掉后
而回收它的尸体,所以python代码多进程编程,在主进程里建议在主进程里一个个join主子进程。
而上例中,主进程在进入sleep前,我们并没有调用join方法,于是僵尸进程就产生了,因为主进程一直停在原地,并没有发起wait系统调用的机会2.4 孤儿进程
说在最前面:孤儿进程指的是一个进程的父进程死掉了,它就成了孤儿,孤儿会被1号进程收养,而不是被它爷爷进程、或者太爷爷进程收养,这一点很关键
父进程先死掉,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被进程号为1的顶级进程(init或systemd)所收养,并由顶级进程对它们完成状态收集工作。
此处需要强调一句:不管子进程时什么状态,哪怕它是僵尸状态也一样,只要它的父进程挂掉了,它就会被1号进程收养。
进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为顶级进程,而顶级进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,顶级进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
我们来测试一下(创建完子进程后,主进程所在的这个脚本就退出了,当父进程先于子进程结束时,子进程会被顶级进程收养,成为孤儿进程,而非僵尸进程),文件内容
import os
import sys
import time
pid = os.getpid()
ppid = os.getppid()
print 'im father', 'pid', pid, 'ppid', ppid
pid = os.fork()
#执行pid=os.fork()则会生成一个子进程
#返回值pid有两种值:
# 如果返回的pid值为0,表示在子进程当中
# 如果返回的pid值>0,表示在父进程当中
if pid > 0:
print 'father died..'
sys.exit(0)
# 保证主线程退出完毕
time.sleep(1)
print 'im child', os.getpid(), os.getppid()
执行文件,输出结果:
im father pid 32515 ppid 32015
father died..
im child 32516 1
看,子进程已经被pid为1的顶级进程接收了,所以僵尸进程在这种情况下是不存在的,存在只有孤儿进程而已,孤儿进程声明周期结束自然会被顶级进程来销毁。2.5 综合练习
最后我们来做一个小练习,把上面关于僵尸进程与孤儿进程的知识点串一下
在做练习前需要再次强调:我们说一个完整操作系统自带的init进程是会定期发起wait或waitpid系统调用来回收僵尸儿子的,这里需要强调的是
-
1、wait或waitpid只能回收儿子,只能是儿子、只能是儿子,只能是儿子,孙子及孙子。。都不行
-
2、当kill -9无法杀掉僵尸进程
-
3、当杀掉一个进程时(假设它以被kill -9杀掉,僵尸进程时不能被kill -9的)
- 如果它的父进程存在并且没有发起wait或waitpid那么该进程就会停留在僵尸进程的状态,此时我们杀死该父进程,那么该父进程的僵尸儿子就会被pid为1的进程收养,pid为1的进程会负责回收
- 如果它的父进程会发起wait或waitpid那么该进程就会被回收,你就看不到什么僵尸进程的状态
示例代码
#coding:utf-8
from multiprocessing import Process
import os
import time
def task1(n):
print("儿子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
pp1=Process(target=task2,args=(10,))
pp2=Process(target=task2,args=(10,))
pp3=Process(target=task2,args=(10,))
pp1.start()
pp2.start()
pp3.start()
time.sleep(n)
def task2(n):
print("孙子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
time.sleep(n)
if __name__ == "__main__":
p=Process(target=task1,args=(10000,))
p.start()
print("爸爸,PID: %s" %os.getpid())
time.sleep(10000)实验
[root@test01 test2]# echo $$ # 当前bash进程的pid为63047
63047
[root@test01 test2]# python test.py
爸爸,PID: 42801
儿子,PID:42802 PPID:42801
孙子,PID:42803 PPID:42802
孙子,PID:42804 PPID:42802
孙子,PID:42805 PPID:42802
# 然后在另外一个终端查看
[root@test01 test2]# ps -elf |grep python
0 S root 42801 63047 0 80 0 - 37800 poll_s 15:17 pts/1 00:00:00 python test.py
1 S root 42802 42801 0 80 0 - 37800 poll_s 15:17 pts/1 00:00:00 python test.py
1 Z root 42803 42802 0 80 0 - 0 do_exi 15:17 pts/1 00:00:00 [python] <defunct>
1 Z root 42804 42802 0 80 0 - 0 do_exi 15:17 pts/1 00:00:00 [python] <defunct>
1 Z root 42805 42802 0 80 0 - 0 do_exi 15:17 pts/1 00:00:00 [python] <defunct>
0 S root 44990 6509 0 80 0 - 28182 pipe_w 15:21 pts/0 00:00:00 grep --color=auto python
# 进程的关系:
父进程 子进程 孙子进程 曾孙子进程
进程即bash,pid为63047--------》42801----》42802----》42803、42804、42805
# 注意,bash这个进程也有定期发起wait与waitpid的功能,所以当它的儿子死掉后,是会被回收的
# 实验1:尝试杀掉曾孙子进程:42803、42804、42805,会发现是杀不死的
kill -9 42803
kill -9 42804
kill -9 42805
# 实验2:尝试杀掉孙子进程42802,它的爹进程42801在原地sleep住了,所以不会回收它,它会进入僵尸进程的状态,但是但是但是42802的三个僵尸儿子会成为孤儿被pid为1的收养,然后被回收,所以我们会看到只有42802这个进程称为僵尸
[root@test01 test2]# ps -elf |grep python
0 S root 42801 63047 0 80 0 - 37800 poll_s 15:17 pts/1 00:00:00 python test.py
1 Z root 42802 42801 0 80 0 - 0 do_exi 15:17 pts/1 00:00:00 [python] <defunct>
# 实验3:然后我们杀死子进程42801,在它死后它肯定会成为僵尸,问题是它爹63047会不会回收,会,因为她爹是bash是有这个功能的,所以它的僵尸状态不会残留
[root@test01 test2]# kill -9 42801
[root@test01 test2]# ps -elf |grep python
0 S root 50846 6509 0 80 0 - 28182 pipe_w 15:34 pts/0 00:00:00 grep --color=auto pythonlinux进程管理更多内容:详见https://egonlin.com/?p=210
三 容器内的僵尸进程
3.1 容器内残留僵尸进程的原因
再次重申一个重点:
操作系统内有1号进程,容器内也有一个1号进程
区别是操作系统内的1号进程里的代码是别人开发的,开发者为其加入了两个个重要的功能
- 当进程称为孤儿进程后,1号进程会收养该孤儿、称为他的爹
- 定义发起wait或waitpid的系统调用去1号进程的僵尸儿子。
而容器里的1号进程的代码是你开发的,你并没有考虑发起wait与waitpid这个系统调用的操作。于是
在容器运行一段时间后,如果有子进程先挂掉了,它爹又没有负责回收,那么僵尸进程的状态就残留了下来,pid资源就被白白占住了
有人会问,那如果我关掉容器,或者删掉k8s里的pod,容器里的僵尸进程还会残留吗,答案是肯定不会残留,为什么呢?
在容器平台上,无论你是用k8s去删除一个pod,或者用docker关闭一个容器,都会用到Containerd这个服务
1、创建容器时:kubelet调用`dockerDaemon`发起创建容器请求,然后由`containerd`接收并创建`containerd-shim`,`containerd-shim`即容器内的0号进程。所以实际的创建容器、容器内执行指令等都是此进程在做
2、同时,`containerd-shim`具有回收僵尸进程的功能,容器1号进程退出后,内核清理其下子孙进程,这些子孙进程被`containerd-shim`收养并清理。 注意:如果1号进程不被Kill,那么其下进程如果有僵尸进程,是无法被处理的。所以用户开发的容器首进程要注意回收退出进程。
ps: 在所有容器都清理后,k8s中的pod也就被删除了。 所以说,你要知道的是,即便容器内的1号进程没有回收僵尸儿子的能力,0号进程是为其兜底的。
而我们接下来要讨论的不是容器内1号进程挂掉的情况,而是要讨论在1号进程活着的情况下,它若没有回收僵尸进程的能力容器内会产生何种现象,应该如何处理。听懂了没有,不是粗鲁地直接干掉容器来回收一切,这操作谁都会。
我们用python解释器作为1号进程来测试(强调,python解释器与bash解释一样都具备定期回收僵尸儿子的功能,但是我们再次用sleep将python父进程停住,它不动弹了也就不会发起回收了,我们也就能看到僵尸儿子了)
# 1、创建工作目录
mkdir /test
cd /test
# 2、创建脚本文件run1.sh
cat >> test.py << EOF
#coding:utf-8
from multiprocessing import Process
import os
import time
def task1(n):
print("儿子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
pp1=Process(target=task2,args=(10,))
pp2=Process(target=task2,args=(10,))
pp3=Process(target=task2,args=(10,))
pp1.start()
pp2.start()
pp3.start()
time.sleep(n)
def task2(n):
print("孙子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
time.sleep(n)
if __name__ == "__main__":
p=Process(target=task1,args=(10000,))
p.start()
print("爸爸,PID: %s" %os.getpid())
time.sleep(10000)
EOF
# 3、创建dockerfile
cat > dockerfile << EOF
FROM centos:7
ADD test.py /opt
CMD python /opt/test.py
EOF
# 4、构建镜像并运行
docker build -t test_defunct:v1 ./
docker run -d --name test1 test_defunct:v1
# 5、进入容器会发现有僵尸进程产生: 因为1号进程一直sleep在原地,根本没有机会去回收僵尸的儿子,如此,效果就模拟出来了
[root@test01 test]# docker exec -ti test1 sh
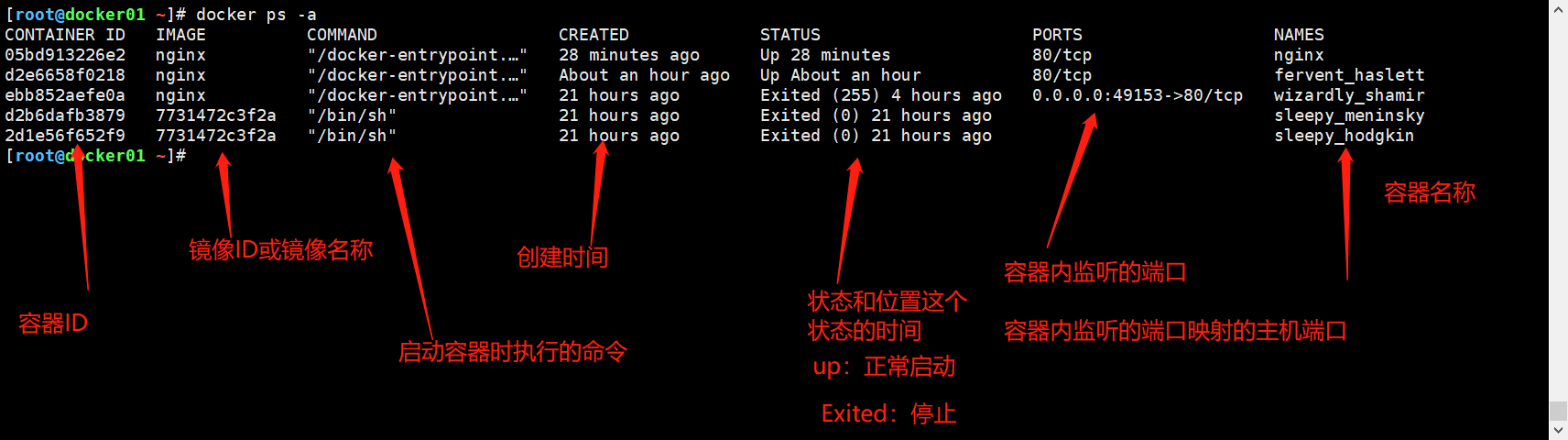
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:50 ? 00:00:00 python /opt/test.py
root 7 1 0 07:50 ? 00:00:00 python /opt/test.py
root 8 7 0 07:50 ? 00:00:00 [python] <defunct>
root 9 7 0 07:50 ? 00:00:00 [python] <defunct>
root 10 7 0 07:50 ? 00:00:00 [python] <defunct>
root 11 0 0 07:50 pts/0 00:00:00 sh
root 18 11 0 07:51 pts/0 00:00:00 ps -ef
此时你是无法杀死那三个僵尸的,那我们杀死他们的爹,即pid为7的进程
sh-4.2# kill -9 7
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:50 ? 00:00:00 python /opt/test.py
root 7 1 0 07:50 ? 00:00:00 [python] <defunct>
root 8 1 0 07:50 ? 00:00:00 [python] <defunct>
root 9 1 0 07:50 ? 00:00:00 [python] <defunct>
root 10 1 0 07:50 ? 00:00:00 [python] <defunct>
root 11 0 0 07:50 pts/0 00:00:00 sh
root 19 11 0 07:52 pts/0 00:00:00 ps -ef
此时你会发现两个非常有趣的现象
1、又多一个僵尸进程
2、pid为7、8、9、10的进程的ppid都变成了1,也就是说他们都被1号进程收养了
很简单,当我们杀死pid为7的进程的时候,它爹也就是1号进程在原地sleep呢,并不会回收它,所以它停留在僵尸状态
而pid为7的进程一旦撕掉,它的三个僵尸儿子们就成了孤儿,自然会被pid为1的进程收养,再说一句,这里的pid为1的进程被sleep住了,肯定
不会 回收他们,于是它们三也残留着,这就是你看到的4个僵尸进程
最后,不能再杀了,而且你kill -9 1也是无效的,1号进程是无法被强制杀死的,这一点我们后面再说。3.1 如何看待容器内的僵尸进程及解决方案
在2.2 小节里我们提过,如果操作系统中残留了少量的僵尸进程,其实并不会影响什么,除非僵尸进程的数量一直在增多,直到占用完了所有的pid号,就会导致无法再启动任何新的进程,这时候就会有问题了,这种情况物理机裸部署时不太容易发生,但在容器化时代确是极有可能的!
虽然每个容器都是一个独立的个体,但容器里的进程pid毕竟还是需要映射到宿主机系统,说白了,对于宿主机linux系统而言,容器就是一组进程集合,如果容器内产生的进程过多(可能是正常产生、也可能是由于出现bug,累积过多的僵尸进程),就会产生类似fork bomb的行为。fork bomb是黑客攻击行为的一种,指的是不断创建新进程直到占满整个主机的pid号为止,此时,该主机便无法再创建任何新进程,宿主机及其上运行的所有容器都受到影响。
综上,不管容器是正常的不断产生新的进程,还是说因为出现bug不断累积僵尸进程,都是一种不合理地、无节制地消耗宿主机pid资源的行为,如何解决呢?有两大方式
-
1、站在容器外的角度,从根本上限制住一个容器可用的pid数目,无论你是正常产生进程,还是出了bug不断累积僵尸进程,统统不允许无限占用pid号,具体操作我们可以在宿主机上配置PID CGROUP来限制每个容器的最大进程数目
-
2、站在容器内的角度,
- (1)、如果你是代码的开发者,那么你应该尽量修正你所编写代码的逻辑,让你的主进程能够定期发起回收僵尸进程的操作
针对2.2小节的案列 (1)我们可以去查看p1.join()的代码,里面有一个关于wait的调用,在主进程里调用p1.join()的目的就是等子进程挂掉后而回收它的尸体,所以python代码多进程编程,在主进程里建议在主进程里一个个join子进程 (2)而且即便你没有执行p.join(),只要你的主进程在运行着,它也会定期发起回收僵尸进程的操作,怕就怕你既没有调用join方法,还让主进程进入了类似sleep一样的阻塞状态,那僵尸进程的状态就残留住了 以上两点都是在编写python程序时需要注意处理好的代码逻辑,以此来避免僵尸进程的残留- (2)、如果你只是代码的维护者,碰到了会残留僵尸进程的软件,那意味着该软件的主进程没有或者没做好回收僵尸进程的工作,你需要在容器内引入一个具备回收僵尸进程能力的进程作为1号进程,就好像操作系统拥有init进程一样,如此,当僵尸进程产生时,你还可以杀掉它的父进程之后该僵尸会被1号进程自动接管并回收
有时候站在程序逻辑或架构的角度,残留僵尸进程是无法避免的,那么就只能为容器引入一个可以定期回收僵尸进程的进程作为容器的1号进程,并且该进程要有能够执行你原来主进程代码的能力才行,如此,你原来的主进程才能被其管理嘛 说道为容器定制一个1号进程,具体实可以有很多种,我们列举了如下两种,第一种只是为了做铺垫辅助大家理解,并不推荐,第二种才是真正推荐的方案。看完方案一才能衬托出方案二的完善 - 方案一、bash解释器:在linux系统中,我们可以把任意命令(当然包括你原本的主进程)放到一个bash脚本里,然后用bash解释器执行,如此bash就成了容器里的1号进程,你原本的主进程就成了它的子进程受其管理,并且bash是具备定期回收僵尸进程的能力的 - 方案二、tini:这是一个开源项目,tini是一个替代庞大复杂的systemd体系的解决方案,是一个最小化init系统,专门适用于充当容器内的1号进程,容器内所有其他进程都受其管理。 tini命令集成了类似操作系统init的功能,所以,tini不仅具备定期发起系统调用回收僵尸儿子的能力,还具备信号转发的能力, 比如你想tini发送信号,那么它也会向它自己的子进程发送同样的信号,这在平滑关闭保证资源正常回收的操作非常有用。 了解tini tini项目地址:https://github.com/krallin/tini。 tini是如何定期回收僵尸进程的? # 1、关于wait与waitpid - wait() 系统调用是一个阻塞的调用,也就是说,如果没有子进程是僵尸进程的话,这个调用就一直不会返回,那么整个进程就会被阻塞住,而不能去做别的事了。 - Linux 还提供了一个类似的系统调用waitpid(),这个调用的参数更多。其中就有一个参数 WNOHANG,它的含义就是,如果在调用的时候没有僵尸进程,那么函数就马上返回了,而不会像 wait() 调用那样一直等待在那里。 # 2、在tini里会不断在调用带WNOHANG 参数的 waitpid(),通过这个方式清理它的僵尸儿子,注意了,只能是儿子 ===>记录一下,写作时的心路历程,事实证明最后的推断是正确的,读者也可以这么做,先提出设想,然后去验证或者推翻自己的设想,这是一个不错的学习方式! 可能我们之前处理的方式都是执行运行一条java命令作为容器的1号进程,该1号进程可能不会发起回收僵尸儿子的操作 但实验过程中发现,我们可以把这条java命令放到一个bash脚本里,然后运行bash来启动,bash会定期发起回收僵尸儿子的操作 我们可以一层层往上杀,直到最后剩bash进程就行 难道说tini的核心作用在于信号转发》????????????????????????? 通过Tini,SIGTERM可以终止进程,不需要你明确安装一个信号处理器 最后确认,确实如此,如果只是站在回收僵尸儿子的角度,我们用bash做容器的1号进程就完全可以,而且很多语言比如python解释本身就有定期回收僵尸儿子的功能,但除此之外还有信号转发保证平滑关闭的需求,如此看来只有tini兼具二者,肯定是一个最优选择
下面我们就来分别介绍在容器外与容器内的处理方式
四 在容器外使用pids CGROUP
站在容器外的角度,在宿主机上配置PID CGROUP来限制每个容器的最大进程数目,防止容器累积进程数过多消耗完宿主机的pid资源
# 在linux系统中可以创建的进程数目是有限的,可以在宿主机执行如下命令查看,如果超过了该值,则无法启动任何新进程,任何命令也都无法执行,因为执行命令也都是在产生进程,虽然执行完毕就销毁该进程,但因为进程数达到上限,你是无法开启任何新进程的
cat /proc/sys/kernel/pid_max
该值可设置,linux操作系统支持的最大的pid范围是0-4194304个
无论容器内是正常创建新进程,还是因为bug而不断累积僵尸进程,我们总归应该对其进行限制,不能让一个容器无法无天地创建进程,此时就用到Cgoup机制,具体是是指pids Cgroup,一般Cgroup文件系统挂载点在/sys/fs/cgroup/pids
每创建一容器,创建容器的服务就会在宿主机的/sys/fs/cgroup/pids
# 在宿主机执行
[root@test01 pids]# cd /sys/fs/cgroup/pids
[root@test01 pids]# df .
文件系统 1K-块 已用 可用 已用% 挂载点
cgroup 0 0 0 - /sys/fs/cgroup/pids
如果是docker命令直接启动的容器,则查看,后面跟着的id号是用命令docker container ls |grep test2查看到的,注意必须是存活的容器才可以
[root@test01 pids]# ls docker/67c4f885b2a8e72c7ea7f4b8f7e28f413fdc7a8060881d8fc1a5ff484da801e5/
cgroup.clone_children cgroup.procs pids.current tasks
cgroup.event_control notify_on_release pids.max
如果是kubelet调用容器引擎产生的容器,则查看,
[root@test01 pids]# ls system.slice/data-docker-overlay2-8a0bb1b29a2e51278f278ac5f1e8aa4206ce817b767c908cedbb9d5cb6f7a8f5-merged.mount/
cgroup.clone_children cgroup.procs pids.current tasks
cgroup.event_control notify_on_release pids.max
可以df | grep 8a0bb1b29a查看到对应的挂载
我们先打开一个终端,进入test2容器内,
[root@test01 ~]# docker exec -ti test2 sh
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 11692 1332 ? Ss 05:11 0:00 sh /opt/run.sh
root 20 0.0 0.0 4400 352 ? S 05:12 0:00 tail -f /dev/null
root 34 0.2 0.0 11824 1660 pts/0 Ss 13:53 0:00 sh
root 40 0.0 0.0 51732 1704 pts/0 R+ 13:53 0:00 ps aux
sh-4.2#
容器内目前总共有3个进程,两个容器自带的,一个我们执行sh进入容器产生的,还要一个ps aux命令的进程执行完毕后立刻结束了,
打开另外一个中断,然后修改test2容器的pid.max为3,再进入容器就会发现无法执行任何命令
[root@test01 pids]# pwd
/sys/fs/cgroup/pids
[root@test01 pids]# echo 3 > docker/67c4f885b2a8e72c7ea7f4b8f7e28f413fdc7a8060881d8fc1a5ff484da801e5/pids.max
[root@test01 pids]#
然后回到上面那个终端,会发现任何命令都无法执行
sh-4.2# ps aux
sh: fork: retry: No child processes
sh: fork: retry: No child processes
sh: fork: retry: No child processes
sh: fork: retry: No child processes
sh: fork: Resource temporarily unavailable
sh-4.2# ==============》补充在k8s中如何限制pod内的pid数
-
1、Kubelet 开启 PodPidsLimit 功能
Kubernetes 里面的每个节点都会运行一个叫做 Kubelet 的服务,负责节点上容器的状态和生命周期,比如创建和删除容器。根据 Kubernetes 的官方文档 Process ID Limits And Reservations 内容,可以设置 Kubelet 服务的 –pod-max-pids 配置选项,之后在该节点上创建的容器,最终都会使用 Cgroups pid 控制器限制容器的进程数量。
我们 Kubernetes 是在 CentOS 7 上使用 kubeadm 部署的 v1.15.9 版本,需要额外设置 SupportPodPidsLimit 的 feature-gate,对应操作如下(其它发行版应该也类似):
# kubelet 使用 systemd 启动的,可以通过编辑 /etc/sysconfig/kubelet # 添加额外的启动参数,设置 pod 最大进程数为 1024 $ vim /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS="--pod-max-pids=1024 --feature-gates=\"SupportPodPidsLimit=true\"" # 重启 kubelet 服务 $ systemctl restart kubelet # 查看参数是否生效 $ ps faux | grep kubelet | grep pod-max-pids root 104865 10.5 0.6 1731392 107368 ? Ssl 11:56 0:30 /usr/bin/kubelet ... --pod-max-pids=10 --feature-gates=SupportPodPidsLimit=true -
2、验证 PodPidsLimit
通过配置 Kubelet 的 –pod-max-pids=1024 选项,限制了一个容器内允许的最大进程数为 1024 个。现在来测试下如果容器内不断 fork 子进程,数目到达 1024 个时会触发什么行为。
参考 Fork bomb 的内容,可以创建一个 pod,不断 fork 子进程。
# 创建普通的 nginx pod yaml $ cat <test-nginx.yaml apiVersion: v1 kind: Pod metadata: name: test-nginx spec: containers: - name: nginx image: nginx EOF # 创建到 Kubernetes 集群 $ kubectl apply -f test-nginx.yaml # 进入 nginx 容器模拟 fork bomb $ kubectl exec -ti test-nginx bash root@test-nginx:/# bash -c "fork() { fork | fork & }; fork" environment: fork: retry: Resource temporarily unavailable environment: fork: retry: Resource temporarily unavailable environment: fork: retry: Resource temporarily unavailable 通过进入一个 nginx 容器里面使用 bash 运行 fork bomb 命令,我们会发现当 fork 的子进程达到限制的上限数目后,会报 retry: Resource temporarily unavailable 的错误,这个时候再看下宿主机的 fork 进程数目。
# 通过在外部宿主机执行下面的命令,会发现 fork 的进程数目接近 1024 个 $ ps faux | grep fork | wc -l 1019通过以上的实验,发现能够通过设置 Kubelet 的 –pod-max-pids 选项,限制容器类的进程数,避免容器进程数不断上升最终耗尽宿主机资源,拖垮整个宿主机系统。
上述原理详见附录《附录1:在k8s中限制pod的pid数》
五 bash作为容器内的1号进程
如果只是站在回收僵尸进程的角度,bash与tini都可以充当容器内的1号进程,但如果是站在一个完善的1号进程的角度,肯定是推荐tini,我们先来演示一下使用bash作为容器内的1号进程,走完整体思路后,你会对tini的应用有一个更清晰的认知,我们后续肯定都是会用tini作为1号进程
=================先来演示一下,就用我们自己的主进程作为1号进程的效果,会发现残留僵尸进程,并且你无法在不关闭容器的情况下回收这些僵尸
实验
[root@test01 test1]# cd /test1/
[root@test01 test1]# ls
dockerfile run.sh test.pytest.py内容如下
#coding:utf-8
from multiprocessing import Process
import os
import time
def task1(n):
print("儿子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
pp1=Process(target=task2,args=(10,))
pp2=Process(target=task2,args=(10,))
pp3=Process(target=task2,args=(10,))
pp1.start()
pp2.start()
pp3.start()
time.sleep(n)
def task2(n):
print("孙子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
time.sleep(n)
if __name__ == "__main__":
p=Process(target=task1,args=(10000,))
p.start()
print("爸爸,PID: %s" %os.getpid())
time.sleep(10000)我们先用主进程,即我们的python程序作为1号进程,来看下效果,dockerfile内容如下
FROM centos:7
ADD test.py /opt
CMD ["python","/opt/test.py"]制作镜像
[root@test01 test1]# docker build -t t1:v1 ./启动
[root@test01 test1]# docker run -d --name test1 t1:v1过大概10s后进入容器内查看,会发现有三个僵尸进程
[root@test01 test1]# docker exec -ti test1 sh
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 03:56 ? 00:00:00 python /opt/test.py
root 7 1 0 03:56 ? 00:00:00 python /opt/test.py
root 8 7 0 03:56 ? 00:00:00 [python] <defunct>
root 9 7 0 03:56 ? 00:00:00 [python] <defunct>
root 10 7 0 03:56 ? 00:00:00 [python] <defunct>
root 11 0 0 03:57 pts/0 00:00:00 sh
root 18 11 0 03:57 pts/0 00:00:00 ps -ef杀死pid为7的进程,你会发现残留的僵尸进程有多了一个,现在为4个了
sh-4.2# kill -9 7
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 03:56 ? 00:00:00 python /opt/test.py
root 7 1 0 03:56 ? 00:00:00 [python] <defunct>
root 8 1 0 03:56 ? 00:00:00 [python] <defunct>
root 9 1 0 03:56 ? 00:00:00 [python] <defunct>
root 10 1 0 03:56 ? 00:00:00 [python] <defunct>
root 11 0 0 03:57 pts/0 00:00:00 sh
root 19 11 0 03:57 pts/0 00:00:00 ps -ef因为你杀死7号进程,它的三个儿子没有爹了,成了孤儿,会被1号进程当孤儿收养,如上所示,但是1号进程为我们自己的python主进程它在原地sleep呢并不会回收这仨僵尸儿子,所以它三依然还在,至于说7号进程,把它杀掉后,它爹原来就是1号进程,没有回收它,自然它也成了残留的僵尸进程
ps:在容器内部,你执行kill -9 1是无法杀死1号进程的,这一点我们之后再做详细解释
=================接下来先来演示一下,用bash进程作为容器内1号进程的效果,此时你可以在不关闭容器的情况下,回收僵尸
具体操作
[root@test01 test1]# cd /test1
[root@test01 test1]# ls # 新增一个run.sh的bash脚本
dockerfile run.sh test.pytest.py的内容同上面一样
run.sh
#!/bin/bash
python /opt/test.py
# 添加这一样是为了防止上面那一行进程被干掉后,本进程还有代码在运行着,否则就也结束了
tail -f /dev/null dockerfile
FROM centos:7
ADD test.py /opt
ADD run.sh /opt
CMD sh /opt/run.sh
制作镜像并测试
docker build -t t2:v2 ./
docker run -d --name test2 t2:v2此时进入到容器里查看
[root@test01 test1]# docker exec -ti test2 sh
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:57 ? 00:00:00 sh /opt/run.sh
root 7 1 0 04:57 ? 00:00:00 python /opt/test.py
root 8 7 0 04:57 ? 00:00:00 python /opt/test.py
root 9 8 0 04:57 ? 00:00:00 [python] <defunct>
root 10 8 0 04:57 ? 00:00:00 [python] <defunct>
root 11 8 0 04:57 ? 00:00:00 [python] <defunct>
root 20 0 1 04:58 pts/0 00:00:00 sh
root 25 20 0 04:58 pts/0 00:00:00 ps -ef
sh-4.2#
先杀8号进程,会回收3僵尸,残留一个僵尸
sh-4.2# kill -9 8
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:57 ? 00:00:00 sh /opt/run.sh
root 7 1 0 04:57 ? 00:00:00 python /opt/test.py
root 8 7 0 04:57 ? 00:00:00 [python] <defunct>
root 20 0 0 04:58 pts/0 00:00:00 sh
root 26 20 0 04:58 pts/0 00:00:00 ps -ef
sh-4.2# 然后杀7,父进程sh会回收僵尸7
sh-4.2# kill -9 7
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:57 ? 00:00:00 sh /opt/run.sh
root 20 0 0 04:58 pts/0 00:00:00 sh
root 27 1 0 04:59 ? 00:00:00 tail -f /dev/null
root 28 20 0 04:59 pts/0 00:00:00 ps -ef
然后我们还可以继续在容器内启动python程序,比如
sh-4.2# (python /opt/test.py &) # 会被0号进程管理管理,即containerd-shim
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:57 ? 00:00:00 sh /opt/run.sh
root 27 1 0 04:59 ? 00:00:00 tail -f /dev/null
root 69 0 0 05:01 pts/0 00:00:00 sh
root 79 0 0 05:02 pts/0 00:00:00 python /opt/test.py
root 80 79 0 05:02 pts/0 00:00:00 python /opt/test.py
root 81 80 0 05:02 pts/0 00:00:00 [python] <defunct>
root 82 80 0 05:02 pts/0 00:00:00 [python] <defunct>
root 83 80 0 05:02 pts/0 00:00:00 [python] <defunct>
root 87 69 0 05:02 pts/0 00:00:00 ps -ef
sh-4.2# kill -9 80
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:57 ? 00:00:00 sh /opt/run.sh
root 27 1 0 04:59 ? 00:00:00 tail -f /dev/null
root 69 0 0 05:01 pts/0 00:00:00 sh
root 79 0 0 05:02 pts/0 00:00:00 python /opt/test.py
root 80 79 0 05:02 pts/0 00:00:00 [python] <defunct>
root 88 69 0 05:02 pts/0 00:00:00 ps -ef
sh-4.2# kill -9 79
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:57 ? 00:00:00 sh /opt/run.sh
root 27 1 0 04:59 ? 00:00:00 tail -f /dev/null
root 69 0 0 05:01 pts/0 00:00:00 sh
root 89 69 0 05:02 pts/0 00:00:00 ps -ef
=================用bash进程作为容器内1号进程存在的问题
上例中,我们演示了只站在回收僵尸进程的角度,用bash作为1号进程,这肯定是可以的,但现实使用时我们通常对1号进程的要求远不止回收僵尸进程这一点,比如我们想要平滑关闭容器的内的所有进程
[root@test01 test1]# docker run -d --name test3 t2:v2
[root@test01 test1]# docker exec -ti test3 sh
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:19 ? 00:00:00 sh /opt/run.sh
root 6 1 0 11:19 ? 00:00:00 python /opt/test.py
root 7 6 0 11:19 ? 00:00:00 python /opt/test.py
root 8 7 0 11:19 ? 00:00:00 [python] <defunct>
root 9 7 0 11:19 ? 00:00:00 [python] <defunct>
root 10 7 0 11:19 ? 00:00:00 [python] <defunct>
root 11 0 0 11:19 pts/0 00:00:00 sh
root 18 11 0 11:20 pts/0 00:00:00 ps -ef
[root@test01 ~]# docker container inspect test3 |grep -i pid # 获取容器的pid,对应容器内1号进程的pid
"Pid": 17771,
"PidMode": "",
"PidsLimit": null,
[root@test01 ~]# yum install strace -y
[root@test01 ~]# strace -p 17771 # 追踪容器内信号,然后打开另外一个终端执行docker stop test3,会得到如下内容
strace: Process 17771 attached
wait4(-1, 0x7ffc632b6990, 0, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
# 1号进程收到了SIGTERM信号
--- SIGTERM {si_signo=SIGTERM, si_code=SI_USER, si_pid=0, si_uid=0} ---
wait4(-1, 0x7ffc632b6990, 0, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
# 其他进程则收到了SIGKILL信号
+++ killed by SIGKILL +++我们执行docker stop test3时,通过strace命令可以看到1号进程收到的是平滑关闭的信号SIGTERM,而容器内其他进程收到的则是强制杀死的信号SIGKILL,这是有问题的,如果容器内1号进程之外的子进程正在处理一些数据库连接、打开着文件,强制杀死后,这些资源短时间内都不会被释放掉,白白占用资源,如果碰上了高并发压力,这是绝对不允许的。我们应该保证容器在被stop时能够响应-15信号而平滑关闭
这里有两个问题需要研究明白
1、为何kill -9 或者kill -19就不是平滑关闭进程,而-15则是一个可以被响应并保证平滑关闭的信号
2、为何1号进程收到的是SIGTERM信号,而其他进程收到的则是SIGKILL信号呢???
搞清楚上述问题之后,我们最终会得出一个结论,还是使用tini作为容器内的1号进程是一个相对完善的选择,但在此之前,先来储备一下信号相关知识,在阅读完6.1-6.5小节之后,你将会知道上述两个问题的答案
六 linux系统中的进程信号
6.1 了解信号
信号就是linux进程收到的一个通知,进程针对自己没有注册过的信号则执行缺省行为,针对自己注册过的信号则在收到信号后触发自定义的行为。
我们可以用kill命令向进程发送如下信号
例如
1、kill -9 666,代表向666号进程发送SIGKILL信号
2、kill 666,没有指定信号,默认发送的是-15信号,即SIGTERM
[root@test01 ~]# kill -l # 查看信号的代号与名称
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
[root@test01 ~]#
也可以通过其他方式为进程发送信号,例如
-
1、组合键
一、ctrl-c 针对一个前台运行的进程,按下ctrl+c组合键,代表发送 SIGINT 信号(程序终止(interrupt)信号)给前台进程组中的所有进程。 常用于终止正在运行的程序。 二、ctrl-z 发送 SIGTSTP 信号(停止进程的运行, 但该信号可以被处理和忽略) 给前台进程组中的所有进程,常用于挂起一个进程。 如果需要恢复到前台输入fg,恢复到后台输入bg -
2、如果代码运行过程中出现bug,导致内存访问出错,当前进程就会收到一个信号SIGSEGV
6.2 进程收到信号后的三种反应
一个进程收到信号后有三种反应:
-
1、忽略(Ignore): 就是对该信号不做任何处理,
-
2、捕获(Catch):就是让用户进程可以注册自己针对这个信号的handler,例如用shell演示一下,如此,一旦进程收到该信号后
就会触发handler的功能运行,用shell演示一下
#!/bin/bash # 操作1:捕捉信号、执行引号内的操作 trap "echo 已经识别信号TERM" TERM trap "echo 已经识别中断信号:ctrl+c" INT # 示例2:捕捉信号、不执行任何操作 # trap "" INT # 示例3:也可以同时捕获多个信号 # trap "" HUP INT QUIT TSTP while true; do sleep 0.5 done -
3、默认/缺省行为(Default):linux系统为每个信号都定义了默认要做的事情,我们可以通过man 7 signal来查看,对于大多数信 号来说,我们都不需要捕获并注册自己的handler,使用默认的就好
6.3 两个特权信号
需要强调的一点是,linux信号里有两个特权信号:
- 1、SIGKILL(-9)
- 2、SIGSTOP(-19)
代表强制杀死,这两个信号有两个非常重要的特点
-
1、无法被忽略(Ignore)
-
2、无法被捕获(Catch)
因为这两信号是linux系统为内核和超级用户准备的特权-》可以删除任意的进程,任何进程只要收到了这俩信号,只能执行缺省行为,任何进程收到了这俩信号都只能乖乖听话、换句话说碰上了只有死的份。
至于SIGTERM(-15)信号,代表的是平滑关闭,该信号是可以被忽略或者说捕获的
此外须知
# KILL (9)
用来立即结束程序的运行. 本信号不能被阻塞、处理和忽略。如果管理员发现某个进程终止不了,可尝试发送这个信号。
# TERM(15):
终止,是不带参数时kill默认发送的信号,默认是杀死进程,与SIGKILL不同的是该信号可以被阻塞和处理。通常用TERM信号来要求程序自己正常退出,如果进程终止不了,我们才会尝试SIGKILL。6.4 kill 命令的执行流程
kill命令执行时本身就是一个进程,该进程需要给另外一个进程发送信号(就是你用pid号指定的那个进程),中间需要经过内核转发
kill命令————-》内核——————–》另外一个进程
所以,kill命令是是向内核发送信号,kill在用户态,执行kill命令则会调用系统调用接口kill(),然后进入到内核函数sys_kill()
然后内核态流程:sys_kill()—> _send_signal() ——>sig_task_ignored()
没有被sig_task_ignored()忽略掉的信号才会发送给用户态的的另外一个进程,sig_task_ignored()就相当于一层关卡,被它放行的信号才会通知给用户态的指定进程(如下图所示pid为1的进程)
如下图所示
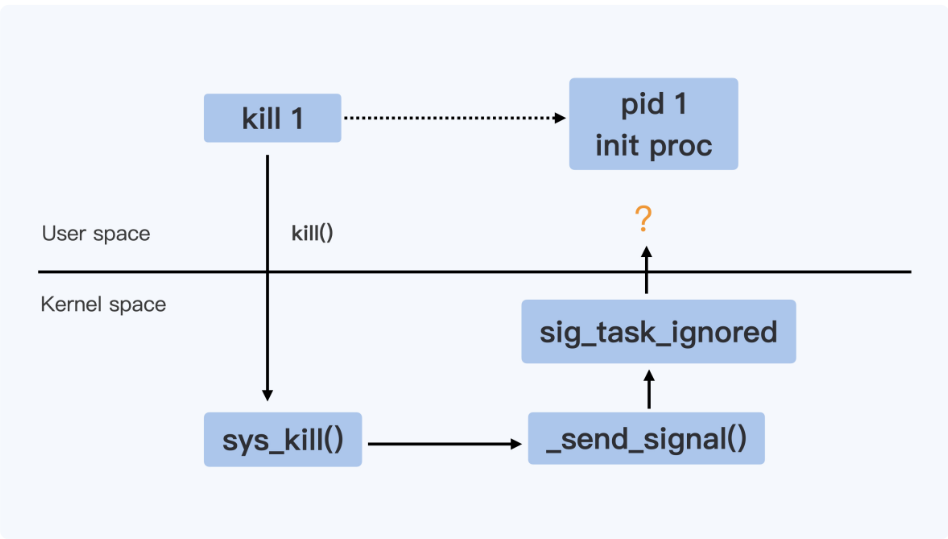
因此上图用户态pid为1的进程能否收到kill发来的信号,主要看sig_task_ignored()的功能
sig_task_ignored()代码如下,主要有三个判断条件,任意一个条件成立,都会返回true,代表应该忽略(Ignore)当前信号
第一个if判断与第三个if判断与我们讨论的问题无关,可以参考注释自行了解,我们主要看一下第二个if判断
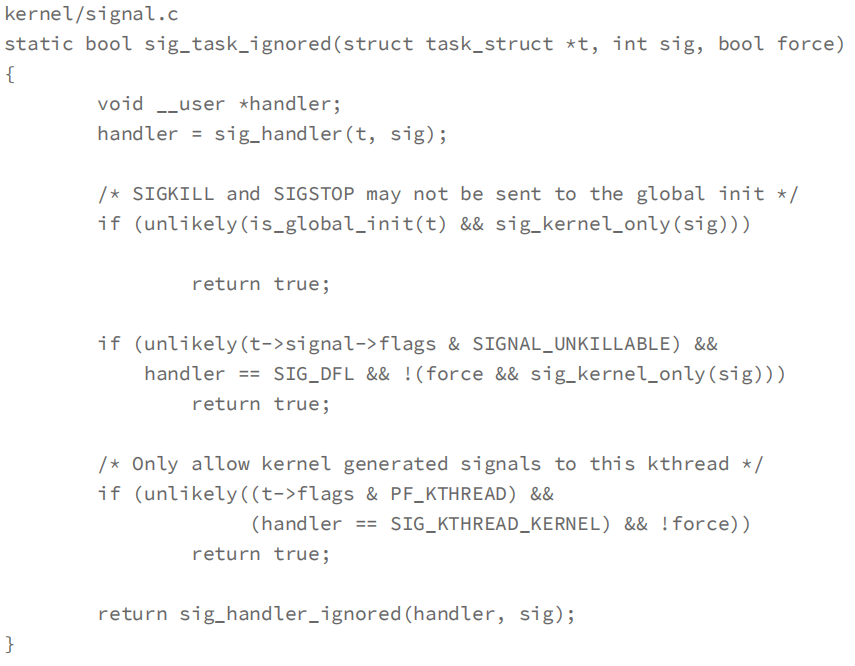
第二个if判断力的条件,又分为三个子条件
-
1、“t->signal->flags & SIGNAL_UNKILLABLE”,该条件代表进程必须是 SIGNAL_UNKILLABLE
在每个Namespace的1号进程创建时,都会被打上SIGNAL_UNKILLABLE 这个标签,也就是说只要是1号进程都会有该flag,此条件针对1号进程一定满足 -
2、“handler == SIG_DFL,代表判断信号的handler是否为SIG_DFL,如果用户进程没有为该进行注册资金的handler,那默认肯定针对该信号有一个缺省的handler,这个缺省的handler就叫SIG_DFL,总结一句话就是:如果你没有注册handler,那么该条件就成立
针对特权信号SIGKILL(-9)与SIGSTOP(-19)你是无法注册handler的,所以这俩信号的handler一定是SIG_DFL,该条件一定满足
但是,针对SIGTERM(-15)信号,你还是可以注册资金的handler的,那它就不是SIG_DFL,该条件就不成立,当然如果你没有注册handler,则默认还是SIG_DFL,该条件还是成立- 3、"!(force && sig_kernel_only(sig))" ,force 由发送信号的进程和接受信号进程是否在同一个namespace里决定,我们是在容器内执行kill -9命令,并且发送给的目标进程也是容器内的进程,所以该force值一定为0(注意在c语言中0代表假False),而sig_kernel_only函数是用了判断信号是不是sigkill或者sigstop的,如果是这两个信号之一才会返回true,很明显kill -9符合这个一点,所以"!(force && sig_kernel_only(sig))" 即"!(False && True)"最终结果为True,该条件也成立
6.5 在容器内-9、-19、-15对1号进程的影响
在k8s,如果我们已发布的镜像有bug,以此启动了一个pod,想修该镜像里的bug,但是因为网络配置问题,又不想重建pod去改变pod IP,即我们只想重启pod内的1号进程让它重新加载配置,而不想重建pod,怎么办?
k8s里是没有restart pod这种命令的,你可能会想到exec到pod内执行强制杀死1号进程,容器不就重启了吗?想法是好的,但是现实中有坑!!!
针对容器内的1号进程,我们在容器内部使用kill命令对其发送如下终止信号
- -9与-19对于1号进程来说均无效,即你无法在容器内用kill -9或kill -19杀死容器内的1号进程,当然你在容器外则是可以正常杀死前提是你找到容器内1号进程映射到物理机的pid号
- -15信号对1号进程来说可能有效,至于是否有效需要看1号进程是否注册了关于-15信号的handler。即你在容器内是有可能用kill -15 1杀死容器内的1号进程的
注意:此处讨论的一定是在容器内部发送命令,具体你课可以参考上一小节sig_task_ignored()中讨论的force值====================》为何-9或-19信号无法在容器内杀死容器的1号进程???《====================
基于上一小节所述,解析原因如下
当你在容器内,在容器内,在容器内,使用kill发-9或者-19给容器内容器内容器内的1号进程,关于sig_task_ignored()第二个条件里的三个子条件
- 条件1
对于容器内的1号进程来说,条件1永远成立,因为1号进程在创建之初就会被打上SIGNAL_UNKILLABLE 标签
- 条件2
条件2成立,因为-9及-19信号都属于特权信号,无法为其注册handler,所以它的标签一定是SIG_DFL
- 条件3
你是在容器内执行的kill命令,并发送的目标进程也是容器内进程,并且此处讨论的是-9或-19信号,
所以条件3里force值为0代表False,sig_kernel_only(sig)匹配-9或-19成功也为真True,条件3"!(force && sig_kernel_only(sig))" 即"!(False && True)"最终结果为True,所以在当前场景下,条件3也永远成立PS:如果你是在容器外、宿主机上, 你想怎么杀容器就怎么杀容器,只要你找到容器内进程对应宿主机的pid就可以
案例演示,怕你看不见,再次强调一定是在容器内,注意一定是在容器内执行kill -9 1与kill -19 1
案例1:go程序作为1号进程
# 1、安装go
[root@test01 init1]# wget https://golang.google.cn/dl/go1.18.4.linux-amd64.tar.gz
[root@test01 init]# tar xf go1.18.4.linux-amd64.tar.gz -C /usr/local/
[root@test01 init]# ls /usr/local/go/bin/
go gofmt
[root@test01 init]# echo 'export PATH=/usr/local/go/bin/:$PATH' >> /etc/profile
[root@test01 init]# source /etc/profile
# 2、工作目录
[root@test01 init1]# cd /root/init
[root@test01 init]# ls
dockerfile go.mod main.go
# 3、创建go.mod文件:vim go.mod
module golang
go 1.17
# 4、编写go代码:vim run.go
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("go主进程...")
time.Sleep(1000000 * time.Second)
}
# 5、编译go程序
go build -v -o ./run
# 6、编写dockerfile
FROM centos:7
ADD run /opt
CMD /opt/run
# 7、构建镜像,并启动容器
docker build -t gotest:v1.0 ./
docker run -d --name test1 gotest:v1.0
# 8、进入容器,执行kill -9或者-19杀1号进程,发现根本杀不死
[root@test01 init]# docker exec -ti test1 sh
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.3 0.0 702760 960 ? Ssl 10:28 0:00 /opt/run
root 11 0.5 0.0 11824 1656 pts/0 Ss 10:28 0:00 sh
root 17 0.0 0.0 51732 1704 pts/0 R+ 10:28 0:00 ps aux
sh-4.2# kill -9 1
sh-4.2# kill -19 1
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 702760 960 ? Ssl 10:28 0:00 /opt/run
root 11 0.0 0.0 11824 1656 pts/0 Ss 10:28 0:00 sh
root 18 0.0 0.0 51732 1696 pts/0 R+ 10:29 0:00 ps aux
案例2:python程序作为1号进程
# 1、工作目录
[root@test01 init1]# cd /root/init1/
[root@test01 init1]# ls
dockerfile run.py
# 2、run.py内容
import time
if __name__ == "__main__":
print("hello world")
time.sleep(1000000)
# 3、dockerfile文件内容
FROM centos:7
ADD run.py /opt
CMD python /opt/run.py
# 4、构建镜像,并启动容器
docker build -t pytest:v1.0 ./
docker run -d --name test2 pytest:v1.0
# 5、进入容器,执行kill -9或者-19杀1号进程,发现根本杀不死
[root@test01 init1]# docker exec -ti test2 sh
sh-4.2# ps -elf
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 5460 poll_s 10:11 ? 00:00:00 python /opt/run.py
4 S root 6 0 0 80 0 - 2956 do_wai 10:11 pts/0 00:00:00 sh
4 R root 12 6 0 80 0 - 12933 - 10:11 pts/0 00:00:00 ps -elf
sh-4.2# kill -9 1
sh-4.2# kill -19 1
sh-4.2# ps -elf
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 5460 poll_s 10:11 ? 00:00:00 python /opt/run.py
4 S root 6 0 0 80 0 - 2956 do_wai 10:11 pts/0 00:00:00 sh
0 R root 13 6 0 80 0 - 12933 - 10:11 pts/0 00:00:00 ps -elf
sh-4.2#
案例3:bash作为1号进程
# 1、工作目录
[root@test01 init2]# cd /root/init2/
[root@test01 init2]# ls
dockerfile run.sh
# 2、run.sh内容
[root@test01 init2]# cat run.sh
#!/bin/bash
echo "hello world"
sleep 1000000
# 3、dockerfile内容
[root@test01 init2]# cat dockerfile
FROM centos:7
ADD run.sh /opt
CMD bash /opt/run.sh
# 4、构建镜像,并启动容器
docker build -t bashtest:v1.0 ./
docker run -d --name test3 bashtest:v1.0
# 5、进入容器,执行kill -9或者-19杀1号进程,发现根本杀不死
[root@test01 init2]# docker exec -ti test3 sh
sh-4.2#
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.0 11692 1356 ? Ss 10:32 0:00 bash /opt/run.sh
root 6 0.0 0.0 4364 356 ? S 10:32 0:00 sleep 1000000
root 7 1.0 0.0 11824 1660 pts/0 Ss 10:32 0:00 sh
root 12 0.0 0.0 51732 1704 pts/0 R+ 10:32 0:00 ps aux
sh-4.2#
sh-4.2# kill -9 1
sh-4.2# kill -9 1
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 11692 1356 ? Ss 10:32 0:00 bash /opt/run.sh
root 6 0.0 0.0 4364 356 ? S 10:32 0:00 sleep 1000000
root 7 0.0 0.0 11824 1660 pts/0 Ss 10:32 0:00 sh
root 13 0.0 0.0 51732 1696 pts/0 R+ 10:32 0:00 ps aux案例演示完毕
-
test1容器中,go程序作为1号进程
-
test2容器中,python程序作为1号进程
-
test3容器中,bash程序作为1号进程
验证了,在容器内对1号进程发送SIGKILL(-9)与SIGSTOP(-19)信号总会被忽略,你是无法用-9或者-19强制杀死1号进程的
====================》为何-15信号在容器内仅仅只是有可能会杀死容器的1号进程???《====================
基于上一小节所述,解析原因如下
当你在容器内,在容器内,在容器内,使用kill -15给容器内容器内容器内的1号进程,关于sig_task_ignored()第二个条件里的三个子条件
- 条件1
对于容器内的1号进程来说,条件1永远成立,因为1号进程在创建之初就会被打上SIGNAL_UNKILLABLE 标签
- 条件2
可能成立也可能不成立,如果你为1号进程注册过-15信号的handler,那么采用的就不是默认的handler即SIG_DFL,本条件便不成立,反之,如果你没有为1号进程注册过-15信号的hanlder,那么就用默认的handler即SIG_DFL,本条件就成立
- 条件3
你是在容器内执行的kill命令,并发送的目标进程也是容器内进程,并且此处讨论的是-15信号,
所以条件3里force值为0代表False,sig_kernel_only(sig)匹配-9或-19才为真,此处为-15,所以结果为False,条件3"!(force && sig_kernel_only(sig))" 即"!(False && False)"最终结果为True,所以在当前场景下,条件3也永远成立分析到这里,对比之前关于-9与-19的分析,我们可以总结出结论
1、-9与-19信号在容器内,是无论如何也无法杀死1号进程的
2、-15信号在容器内能否杀死1号进程,取决于1号进程有没有为-15信号注册hanlder并在handler里执行退出代码,其他的条件都可以不用分析了
示例如下:我们继续沿用上一小节中的案例,还是那三个容器test1、test2、test3
我们先来验证在容器内发送SIGTERM(-15)信号给1号进程,三个容器的1号进程分别有何反应
1、go程序作为1号进程响应了-15信号,1号进程被干掉
[root@test01 ~]# docker exec -ti test1 sh
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 702760 960 ? Ssl 10:28 0:00 /opt/run
root 19 0.5 0.0 11824 1660 pts/0 Ss 10:38 0:00 sh
root 24 0.0 0.0 51732 1696 pts/0 R+ 10:38 0:00 ps aux
sh-4.2# kill -15 1
sh-4.2# [root@test01 ~]#
# 分析
golang程序里,默认就为很多信号注册了自己的handler,包括SIGTEM(-15)信号,也就是bit 15,所以当我们为test1的1号进程发送-15信号时,因为注册了handler,所以采用的部署缺省的handler,肯定名字不叫SIG_DFL,因此我们上面提到的条件2不满足,该信号没有被忽略掉,正常执行了退出2、python程序作为1号进程,没有响应-15进程,1号进程依然存在
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 21840 4468 ? Ss 10:11 0:00 python /opt/run.py
root 14 1.0 0.0 11824 1660 pts/0 Ss 10:39 0:00 sh
root 20 0.0 0.0 51732 1704 pts/0 R+ 10:39 0:00 ps aux
sh-4.2# kill -15 1
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 21840 4468 ? Ss 10:11 0:00 python /opt/run.py
root 14 0.1 0.0 11824 1660 pts/0 Ss 10:39 0:00 sh
root 21 0.0 0.0 51732 1696 pts/0 R+ 10:39 0:00 ps aux
sh-4.2#
# 分析
python解释器也没有注册-15信号3、bash程序作为1号进程,也没有响应-15进程,1号进程依然存在
[root@test01 ~]# docker exec -ti test3 sh
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 11692 1356 ? Ss 10:32 0:00 bash /opt/run.sh
root 6 0.0 0.0 4364 356 ? S 10:32 0:00 sleep 1000000
root 14 0.5 0.0 11824 1656 pts/0 Ss 10:40 0:00 sh
root 19 0.0 0.0 51732 1696 pts/0 R+ 10:40 0:00 ps aux
sh-4.2# kill -15 1
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 11692 1356 ? Ss 10:32 0:00 bash /opt/run.sh
root 6 0.0 0.0 4364 356 ? S 10:32 0:00 sleep 1000000
root 14 0.1 0.0 11824 1656 pts/0 Ss 10:40 0:00 sh
root 20 0.0 0.0 51732 1696 pts/0 R+ 10:40 0:00 ps aux
sh-4.2#
# 分析
而bash程序默认注册了两个handler,一个是bit 2代表(SIGINT),另外一个是bit 17(代表SIGCHLD),但是没有注册SIGTERM,所以依然采用的是默认的hanlder,名为SIG_DFL,因此上面的条件2满足,该进行会被忽略掉那如果我们在bash脚本了为-15信号注册了自己的handler,然后在handler做一些清理工作之后正常exit退出,你在容器内kill -15 1肯定是可以干掉1号进程的,因为有我们自定义的handler,你肯定可以做到平滑关闭(保证做好清理工作)
在上面的bash案例的基础上,修改一下run.sh的内容,此处我们使用了shell语法中的trap ‘命令’ 信号,引号里的命令就是我们为信号注册的handler,一旦脚本进程收到该进行则触发handler的运行
# 1、run.sh内容
[root@test01 init3]# cat run.sh
#!/bin/bash
trap "echo '捕捉到信号TERM可以在此执行一系列的清理工作' && exit 0" TERM # 如果是后台运行,那echo的打印内容并不会显示到当前终端
echo $$
while true;
do
sleep 0.5 # 不要在默认来一个sleep 100000,那么bash直接就停在原地了,trap引号里的命令是无法执行的
done
# 2、dockerfile内容
[root@test01 init3]# cat dockerfile
FROM centos:7
ADD run.sh /opt
CMD bash /opt/run.sh
# 2、制作镜像并启动容器
docker build -t bashtest:v2.0 ./
docker run -d --name test4 bashtest:v2.0
# 3、进入容器内,执行kill -15 1,此时是可以杀死1号进程的
[root@test01 init3]# docker exec -ti test4 sh
sh-4.2# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.4 0.0 11692 1380 ? Ss 01:44 0:00 bash /opt/run.sh
root 34 1.5 0.0 11824 1656 pts/0 Ss 01:44 0:00 sh
root 43 0.0 0.0 4364 356 ? S 01:44 0:00 sleep 0.5
root 44 0.0 0.0 51732 1696 pts/0 R+ 01:44 0:00 ps aux
sh-4.2# kill -15 1 # 此时-15信号就可以杀死1号进程了
sh-4.2# [root@test01 init3]#
更多关于shell信号的知识详见:
我们已经知道了bash如何注册信号,下面演示一下python如何注册信号