机器学习算法原理
1.1 感知机算法
# 感知机算法图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
np.random.seed(1)
x1 = np.random.random(20)+1.5
y1 = np.random.random(20)+0.5
x2 = np.random.random(20)+3
y2 = np.random.random(20)+0.5
# 一行二列第一个
plt.subplot(121)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.vlines(2.8, 0, 2, colors="r", linestyles="-", label='$wx+b=0$')
plt.title('线性可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font)
# 一行二列第二个
plt.subplot(122)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.scatter(3.5, 1, s=50, color='b')
plt.title('线性不可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font, loc='upper right')
plt.show()
从左图中也可以看出总能找到一条直线将男孩和女孩分开,即男孩和女孩在操场上的分布是线性可分的,此时该分隔直线为
$$
\omega{x}+b=0
$$
其中$\omega,b$是参数,$x$是男孩和女孩共有的某种特征。
如果某个男孩不听话跑到女孩那边去了,如下图右图所示,则无法通过一条直线能够把所有的男孩和女孩分开,则称男孩和女孩在操场上的分布是线性不可分的,即无法使用感知机算法完成该分类过程。
上述整个过程其实就是感知机实现的一个过程。
1.1.1 决策函数
感知机算法的决策函数为
$$
sign(\omega^Tx)=
\begin{cases}
1, \quad \omega^Tx > 0 \
-1, \quad \omega^Tx < 0
\end{cases}
$$
该决策函数的意思是点$x=x_0$对于超平面$\omega{x}+b=0$:
- 当$\omega{x_0}+b>0$为正类
- 当$\omega{x_0}+b<0$为反类
1.1.1.1 sign函数图像
sign函数也称作符号函数,当x>0的时候y=1;当x=0的时候y=0;当x<0的时候y=-1。sign函数公式为
$$
y = \begin{cases}
1,\quad x>0 \
0,\quad x=0 \
-1,\quad x<0 \
\end{cases}
$$
# sign函数图像
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
x_list = [i for i in range(-100, 100)]
y_list = np.sign(x_list)
plt.figure()
plt.plot(x_list, y_list, color='r')
plt.plot(0, 0, color='k', marker='o')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
1.1.2 损失函数
感知机的损失函数表示误分类点到超平面的距离,源自于数学中点$(x_0,y_0)$到面$Ax+By+C=0$的公式
$$
\frac{|Ax_0+By_0+C|}{\sqrt{A^2+B^2}}
$$
当样本点$(x_i,y_i)$为误分类点时:
- 当$w^Tx_i>0$时,本来应该是$y_i=1$,但由于误分类,所以$y_i=-1$,$-y_i(w^Tx_i)>0$
- 当$w^Tx_i<0$时,本来应该是$y_i=-1$,但由于误分类,所以$y_i=1$,$-y_i(w^Tx_i)>0$
因此感知机算法的损失函数为
$$
-{\frac{y_i(\omega^Tx_i)}{||\omega||}}
$$
1.1.3 目标函数
感知机算法的目标函数为
$$
J(\omega)=\sum_{{x_i}\in{M}} -{\frac{y_i(\omega^Tx_i)}{||\omega||}}
$$
其中$M$是所有误分类点的集合。
该目标函数不同于其他机器学习算法的均值,它是对所有误分类点的距离加和。
由于$\omega^Tx_i=\omega_1x_1 + \omega_2x_2 + \cdots + \omega_nx_n + b$,如果$\omega$和$b$成比例的增加,即分子的$\omega$和$b$扩大$n$倍时,分母的L2范数也将扩大$n$倍,也就是说分子和分母有固定的倍数关系,即可以将分子或分母固定为$1$,然后求分子自己或分母的倒数的最小化作为新的目标函数。(此处讲解拿出$b$,事实上$b$对结果的影响很小,后续会继续用向量的方式,并且忽略$b$)。
感知机将分母$||\omega||$固定为$1$,然后将分子的最小化作为目标函数,因此感知机的目标函数更新为
$$
J(\omega)=-\sum_{{x_i}\in{M}}y_i(\omega^Tx_i)
$$
1.1.4 目标函数优化问题
感知机算法的目标函数为
$$
\underbrace{arg\,min}{\omega}J(\omega)=\underbrace{arg\,min}{\omega} -\sum_{{x_i}\in{M}} y_i(\omega^Tx_i)
$$
1.2 线性回归
假设房价和房子所在地区$x_1$、占地面积$x_2$、户型$x_3$和采光度$x_4$有关,那么我是不是可以把这些因素假想成房子的特征,然后给这些每个特征都加上一个相应的权重$\omega$,既可以得到如下的决策函数
$$
\hat{y} = \omega_1x_1 + \omega_2x_2 + \omega_3x_3 + \omega_4x_4 + b
$$
其中$b$可以理解为偏差,你也可以想成房子的这些特征再差也可能会有一个底价。
基于上述给出房价的决策函数,我们就可以对一个某个不知名的房子输入它的这些特征,然后就可以得到这所房子的预测价格了。
1.2.1 决策函数
线性回归的决策函数为
$$
\hat{y} = f(x) = \omega_1x_1 + \omega_2x_2 + \cdots + \omega_nx_n + b = w^Tx+b
$$
1.2.2 目标函数
线性回归的目标函数为
$$
\begin{align}
J(\omega,b) & = \sum_{i=1}^m (yi – \hat{y{i}})^2 \
& = \sum_{i=1}^m (y_i – w^Tx_i – b)
\end{align}
$$
其中$y_i$为真实值,$\hat{y_i}$为预测值。
该目标函数使用的损失函数为平方损失函数。
1.2.3 目标函数优化问题
线性回归的目标函数优化问题为
$$
\underbrace{arg\,min}{\omega}J(\omega,b) = \underbrace{arg\,min}{\omega}\sum_{i=1}^m (y_i – w^Tx_i – b)
$$
1.3 逻辑回归简介
感知机算法中讲到,假设操场上男生和女生由于受传统思想的影响,男生和女生分开站着,并且因为男生和女生散乱在操场上呈线性可分的状态,因此我们总可以通过感知机算法找到一条直线把男生和女生分开,并且最终可以得到感知机模型为
$$
f(x)=sign(w^Tx)
$$
如果你细心点会发现,由于感知模型使用的是sign函数,如果当计算一个样本点$w^Tx=0.001$的时候,$sign(w^Tx)=1$,即该函数会把该样本归为$1$,但是为什么他不能是$0$类呢?并且由于sign函数在$x=0$处有一个阶跃,即函数不连续,该函数在数学上也是不方便处理的。
由此逻辑函数使用sigmoid函数对$w^Tx$做处理,并且把sigmoid函数得到的值$\hat{y}$当成概率进行下一步处理,这也正是逻辑回归对感知机的改进。
上述整个过程其实就是逻辑回归一步一步被假想出来的的一个过程,接下来将从理论层面抽象的讲解逻辑回归。
1.3.1 Sigmoid函数
Sigmoid函数公式为
$$
g(z) = {\frac{1}{1+e^{-z}}}
$$
# Sigmoid函数图像图例
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def sigmoid(z):
return 1 / (1 + np.exp(-z))
ax = plt.subplot(111)
# 描绘十字线
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
z = np.linspace(-10, 10, 256)
hat_y = sigmoid(z)
plt.plot(z, hat_y, c='r', label='Sigmoid')
# 描绘y=0.5和y=1.0两条直线
plt.yticks([0.0, 0.5, 1.0])
ax = plt.gca()
ax.yaxis.grid(True)
plt.xlabel('$w^Tx$')
plt.ylabel('$\hat{y}$')
plt.legend()
plt.show()
1.3.2 决策函数
逻辑回归的决策函数使用的Sigmoid函数,即
$$
y = g(\omega^Tx) = {\frac{1}{1+e^{-\omega^Tx}}}
$$
其中$g()$为Sigmoid函数。
逻辑回归的决策函数为
$$
\begin{align}
& p(y=1|x,\omega)=\pi(x) \
& p(y=0|x,\omega)=1-\pi(x)
\end{align}
$$
其中$1$和$0$代表两个类别,通过Sigmoid函数图像可以看出当$\omega^Tx>0$时$y=1$,当$\omega^Tx<0$时$y=0$。
1.3.3 损失函数
逻辑回归的损失函数为
$$
L(\omega) = \prod_{i=1}^m [\pi(x_i)]^{y_i}[(1-\pi(x_i))]^{(1-y_i)}
$$
- 当$yi=0$时,$L(\omega) = \prod{i=1}^m [\pi(x_i)]^{0}[(1-\pi(xi))]^{(1-0)}=\prod{i=1}^m [(1-\pi(x_i))]$
- 当$yi=1$时,$L(\omega) = \prod{i=1}^m [\pi(x_i)]^{1}[(1-\pi(xi))]^{(1-1)}=\prod{i=1}^m [\pi(x_i)]^{1}$
1.3.4 目标函数
对逻辑回归的损失函数取对数,即可得逻辑回归的目标函数为
$$
J(\omega) = \sum_{i=1}^m [y_i\log\pi(x_i)+(1-y_i)\log(1-\pi(x_i))]
$$
1.3.5 目标函数优化问题
其中逻辑回归的目标函数的优化问题为最大化目标函数
$$
\underbrace{arg\,max}{\omega}J(\omega) = \underbrace{arg\,max}{\omega}\sum_{i=1}^m [y_i\log\pi(x_i)+(1-y_i)\log(1-\pi(x_i))]
$$
1.4 朴素贝叶斯法简介
假设现在有一个有两个类别的鸢尾花数据集,并且已经知晓每个数据的分类情况,并且假设数据的分布如下图所示。
# 朴素贝叶斯引入图例
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
from sklearn import datasets
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
iris_data = datasets.load_iris()
X = iris_data.data[0:100, [0, 1]]
y = iris_data.target[0:100]
plt.scatter(X[0:50, [0]], X[0:50, [1]], color='r',
s=50, marker='o', label='山鸢尾')
plt.scatter(X[50:100, [0]], X[50:100, [1]],
color='b', s=50, marker='x', label='杂色鸢尾')
plt.scatter(5.5,3.2,color='g',marker='*',label='新样本',s=100)
plt.xlabel('花瓣长度(cm)', fontproperties=font)
plt.ylabel('花瓣宽度(cm)', fontproperties=font)
plt.legend(prop=font)
plt.show()
现在假设有一个未知分类的鸢尾花数据$(x_1(花瓣长度),x_2(花瓣宽度))$,用$p_1(x_1,x_2)$表示样本属于山鸢尾(red)的概率,用$p_2(x_1,x_2)$表示属于杂色鸢尾(blue)的概率,$p_1(x_1,x_2) + p_2(x_1,x_2) = 1$。
假设如果$p_1(x_1,x_2) > p_2(x_1,x_2)$则$(x_1,x_2)$为山鸢尾,否则为杂色鸢尾,即选择概率高的类别作为新样本的分类结果。这就是贝叶斯决策理论的核心思想,选择具有最高概率的决策。
如果使用条件概率来表示这个上述所说的分类,则可以表示为
$$
\begin{align}
& p(red|x_1,x_2) > p(blue|x_1,x_2) \quad \text{样本属于山鸢尾} \
& p(red|x_1,x_2) < p(blue|x_1,x_2) \quad \text{样本属于杂色鸢尾}
\end{align}
$$
也就是说求如下表达式结果
$$
arg\,max\,(p(red|x_1,x_2),p(blue|x_1,x_2))
$$
如果只有两个特征$x_1$和$x2$,那么计算并不会很难,按照条件公式计算即可,但是你有没有想过如果有$n$特征,$K$个分类呢?即计算
$$
\underbrace{arg\,max}{c_k}\,p(c_j|x_1,x_2,\ldots,x_n) \quad(k=1,2,\cdots,K)
$$
上述的计算量是非常大的,那么我们有没有一种简单的方法能够改善该公式呢?有是有一定有的,即朴素贝叶斯法。
1.4.1 贝叶斯公式
若果$A$和$B$相互独立,并有条件概率公式
$$
p(A|B) = {\frac{p(A,B)}{p(B)}} \
p(B|A) = {\frac{p(A,B)}{p(A)}} \
$$
通过条件概率可得
$$
p(A,B) = p(B|A)p(A) \
p(A|B) = {\frac{p(B|A)p(A)}{p(B)}} \quad \text{简写的贝叶斯公式}
$$
1.4.2 朴素贝叶斯法
假设已经得到了训练集的$p(c_k)$和$p(x_j|ck)$值,假设现有一个测试样本$(x{1},x{2},\ldots,x{n})$,则可以根据贝叶斯公式求得$K$个分类$c_1,c_2,\ldots,c_k$各自的概率。
$$
p(ck|x{1},x{2},\ldots,x{n}) = {\frac{p(x{1},x{2},\ldots,x_{n}|c_k)p(ck)}{p(x{1},x{2},\ldots,x{n})}}
$$
假设特征之间相互独立,则可以把上述公式转化为
$$
p(ck|x{1},x{2},\ldots,x{n}) = {\frac{p(x_{1}|ck)p(x{2}|ck)\cdots{p(x{n}|c_k)p(ck)}} {p(x{1},x{2},\ldots,x{n})}}
$$
求得所有分类各自的概率之后,哪一个分类的概率最大,则样本属于哪一个分类。
$$
\begin{align}
样本类别 & = max\,(p(c1|x{1},x{2},\ldots,x{n}),p(c2|x{1},x{2},\ldots,x{n}),\cdots,p(ck|x{1},x{2},\ldots,x{n})) \
& = \underbrace{arg\,max}_{ck}\,{\frac{p(x{1}|ck)p(x{2}|ck)\cdots{p(x{n}|ck)}} {p(x{1},x{2},\ldots,x{n})}} \
\end{align}
$$
其中$y = max\,f(x)$表示$y$是$f(x)$中所有的值中最大的输出;$y = arg\,max f(x)$表示$y$是$f(x)$中,输出的那个参数$t$。
由于每一个类别的概率公式的分子都是相同的,把分子去掉后则可以把上述公式转化为朴素贝叶斯模型的基本公式
$$
\begin{align}
样本类别 & = \underbrace{arg\,max}_{ck} {p(x{1}|ck)p(x{2}|ck)\cdots{p(x{n}|c_k)p(ck)}} \
& = \underbrace{arg\,max}{c_k}\,p(ck) \prod{j=1}^{n} p(x_{j}|c_k)
\end{align}
$$
1.5 k近邻算法简介
不知道同学们在看电影的时候有没有思考过你是如何判断一部电影是爱情片还是动作片的,你可以停下来想想这个问题再往下看看我的想法。
我说说我是如何判断一部电影是爱情片还是动作片的,首先绝对不是靠那些预告片,毕竟预告片太短了,爱情片的预告可能是动作片,动作片的预告可能是爱情片也说不定。
相比较预告片我用了一个很愚蠢很繁琐但很有效的方法。首先我用一部电影的接吻镜头的次数作为$x$轴,打斗的场景次数作为$y$轴生成了一个二维空间,即平面图,如下图所示。(注:以下电影的接吻镜头次数和打斗场景次数都是假设的)
# k近邻算法引入图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
# 动作片
plt.scatter(2, 10, marker='o', c='r', s=50)
plt.text(2, 9, s='《战狼2》(2,10)', fontproperties=font, ha='center')
plt.scatter(4, 12, marker='o', c='r', s=50)
plt.text(4, 11, s='《复仇者联盟2》(4,12)', fontproperties=font, ha='center')
plt.scatter(2, 15, marker='o', c='r', s=50)
plt.text(2, 14, s='《猩球崛起》(2,15)', fontproperties=font, ha='center')
# 爱情片
plt.scatter(10, 4, marker='x', c='g', s=50)
plt.text(10, 3, s='《泰坦尼克号》(10,4)', fontproperties=font, ha='center')
plt.scatter(12, 2, marker='x', c='g', s=50)
plt.text(12, 1, s='《致我们终将逝去的青春》(12,2)', fontproperties=font, ha='center')
plt.scatter(15, 5, marker='x', c='g', s=50)
plt.text(15, 4, s='《谁的青春不迷茫》(15,5)', fontproperties=font, ha='center')
# 测试点
plt.scatter(5, 6, marker='s', c='k', s=50)
plt.text(5, 5, s='《未知类型的电影》(5,5)', fontproperties=font, ha='center')
plt.xlim(0, 18)
plt.ylim(0, 18)
plt.xlabel('接吻镜头(次)', fontproperties=font)
plt.ylabel('打斗场景(次)', fontproperties=font)
plt.title('k近邻算法引入图例', fontproperties=font, fontsize=20)
plt.show()
通过上图我们可以发现动作片《战狼2》的打斗场景次数明显多于接吻镜头,而爱情片《泰坦尼克号》的接吻镜头明显多于打斗场景,并且其他的动作片和爱情片都有这样的规律,因此我做了一个总结:爱情片的接吻镜头次数会明显比打斗的场景次数多,而动作片反之。
通过上述的总结,如果我再去看一部新电影的时候,我会在心里默数这部电影的接吻镜头的次数和打斗场景,然后再去判断。这种方法看起来无懈可击,但是如果碰到了上述黑点《未知类型的电影》所在的位置,即当接吻镜头次数和打斗场景次数差不多的时候,往往很难判断它是爱情片还是动作片。
这个时候我们的主角k近邻算法就应该出场了,因为使用k近邻算法可以很好的解决《未知类型的电影》这种尴尬的情形。
- 假设我们把平面图中的每一个电影看成一个点,例如《战狼2》是$(2,10)$、《未知类型的电影》是$(5,6)$、《泰坦尼克号》是$(10,4)$……
- 我们使用k近邻的思想,通过欧几里得距离公式计算出每一部电影在平面图中到《未知类型的电影》的距离
- 然后假设$k=4$,即获取离《未知类型的电影》最近的$4$部电影
- 如果这$4$部电影中爱情片类型的电影多,则《未知类型的电影》是爱情片;如果动作片类型的电影多,则《未知类型的电影》是动作片;如果两种类型的电影数量一样多,则另选$k$值
上述整个过程其实就是k近邻算法实现的一个过程。
1.5.1 距离度量工具
k近邻算法对于距离度量的方式,有很多种方法可以选择,一般选择我们电影分类例子中讲到的欧几里得距离,也称作欧氏距离。同时还可能会使用曼哈顿距离或闵可夫斯基距离,这里统一给出它们的公式。
假设$n$维空间中有两个点$x_i$和$x_j$,其中$x_i = (x_i^{(1)},x_i^{(2)},\cdots,x_i^{(n)})$,$x_j = (x_j^{(1)},x_j^{(2)},\cdots,x_j^{(n)})$。
欧氏距离为
$$
d(x_i,xj) = \sqrt{\sum{l=1}^n(x_i^{(l)}-x_j^{(l)})^2}
$$
曼哈顿距离为
$$
d(x_i,xj) = \sum{l=1}^n|x_i^{(l)}-x_j^{(l)}|
$$
闵可夫斯基距离为
$$
d(x_i,xj) = \sqrt[p]{\sum{l=1}^n(|x_i^{(l)}-x_j^{(l)}|)^p}
$$
其中曼哈顿距离是闵可夫斯基距离$p=1$时的特例,而欧氏距离是闵可夫斯基距离$p=2$时的特例。
1.6 决策树简介
假设银行需要构造一个征信系统用来发放贷款,如果你是构建该系统的人,你会如何构建该系统呢?
我说说我将如何构建一个银行的征信系统,首先,我会判断征信人的年收入有没有50万,如果有我直接判定他可以贷款,如果没有我会再做其他的判断;其次,判断征信人有没有房产,如果有房产也就是说他有了可以抵押的不动产,既可以判定他可以贷款,如果没有,则不能贷款……
上述整个过程其实就是决策树实现的一个过程。
1.7 支持向量机简介
# 感知机引入图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
np.random.seed(1)
x1 = np.random.random(20)+1.5
y1 = np.random.random(20)+0.5
x2 = np.random.random(20)+3
y2 = np.random.random(20)+0.5
# 一行二列第一个
plt.subplot(121)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.vlines(2.8, 0, 2, colors="r", linestyles="-", label='$wx+b=0$')
plt.title('线性可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font)
# 一行二列第二个
plt.subplot(122)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.scatter(3.5, 1, s=50, color='b')
plt.title('线性不可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font, loc='upper right')
plt.show()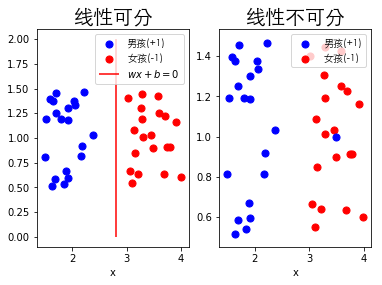
在二维空间中,感知机模型试图找到一条直线能够把二元数据分隔开;在高维空间中感知机模型试图找到一个超平面$S$,能够把二元数据隔离开。这个超平面$S$为$\omega{x}+b=0$,在超平面$S$上方的数据定义为$1$,在超平面$S$下方的数据定义为$-1$,即当$\omega{x}>0$,$\hat{y}=+1$;当$\omega{x}<0$,$\hat{y}=-1$。
上张线性可分和线性不可分的区别图第一张图则找到了一条直线能够把二元数据分隔开,但是能够发现事实上可能不只存在一条直线将数据划分为两类,因此再找到这些直线后还需要找到一条最优直线,对于这一点感知机模型使用的策略是让所有误分类点到超平面的距离和最小,即最小化该式
$$
J(\omega)=\sum_{{x_i}\in{M}} {\frac{- y_i(\omega{x_i}+b)}{||\omega||_2}}
$$
上式中可以看出如果$\omega$和$b$成比例的增加,则分子的$\omega$和$b$扩大$n$倍时,分母的L2范数也将扩大$n$倍,也就是说分子和分母有固定的倍数关系,既可以分母$||\omega||2$固定为$1$,然后求分子的最小化作为代价函数,因此给定感知机的目标函数为
$$
J(\omega)=\sum{{x_i}\in{M}} – y_i(\omega{x_i}+b)
$$
既然分子和分母有固定倍数,那么可不可以固定分子,把分母的倒数作为目标函数呢?一定是可以的,固定分子就是支持向量机使用的策略。
1.7.1 目标函数优化问题
# 间隔最大化图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn import svm
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
np.random.seed(8) # 保证数据随机的唯一性
# 构造线性可分数据点
array = np.random.randn(20, 2)
X = np.r_[array-[3, 3], array+[3, 3]]
y = [0]*20+[1]*20
# 建立svm模型
clf = svm.SVC(kernel='linear')
clf.fit(X, y)
# 构造等网个方阵
x1_min, x1_max = X[:, 0].min(), X[:, 0].max(),
x2_min, x2_max = X[:, 1].min(), X[:, 1].max(),
x1, x2 = np.meshgrid(np.linspace(x1_min, x1_max),
np.linspace(x2_min, x2_max))
# 得到向量w: w_0x_1+w_1x_2+b=0
w = clf.coef_[0]
# 加1后才可绘制 -1 的等高线 [-1,0,1] + 1 = [0,1,2]
f = w[0]*x1 + w[1]*x2 + clf.intercept_[0] + 1
# 绘制H1,即wx+b=-1
plt.contour(x1, x2, f, [0], colors='k', linestyles='--')
plt.text(2, -4, s='$H_2={\omega}x+b=-1$', fontsize=10, color='r', ha='center')
# 绘制分隔超平面,即wx+b=0
plt.contour(x1, x2, f, [1], colors='k')
plt.text(2.5, -2, s='$\omega{x}+b=0$', fontsize=10, color='r', ha='center')
plt.text(2.5, -2.5, s='分离超平面', fontsize=10,
color='r', ha='center', fontproperties=font)
# 绘制H2,即wx+b=1
plt.contour(x1, x2, f, [2], colors='k', linestyles='--')
plt.text(3, 0, s='$H_1=\omega{x}+b=1$', fontsize=10, color='r', ha='center')
# 绘制数据散点图
plt.scatter(X[0:20, 0], X[0:20, 1], cmap=plt.cm.Paired, marker='x')
plt.text(1, 1.8, s='支持向量', fontsize=10, color='gray',
ha='center', fontproperties=font)
plt.scatter(X[20:40, 0], X[20:40, 1], cmap=plt.cm.Paired, marker='o')
plt.text(-1.5, -0.5, s='支持向量', fontsize=10,
color='gray', ha='center', fontproperties=font)
# plt.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1) # 绘制支持向量点
plt.xlim(x1_min-1, x1_max+1)
plt.ylim(x2_min-1, x2_max+1)
plt.show()
支持向量机的目标函数的最优化问题,即硬间隔最大化为
$$
\begin{align}
& \underbrace{\min}_{\omega,b} {\frac{1}{2}}{||\omega||}^2 \
& s.t. \quad y_i(\omega{x_i}+b)\geq1, \quad i=1,2,\ldots,m
\end{align}
$$
1.8 k均值聚类算法简介
# k均值聚类算法简介举例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.datasets import make_classification
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
X, y = make_classification(
n_samples=500, n_features=20, random_state=1, n_informative=2, shuffle=False)
plt.scatter(X[0:250, [0]], X[0:250, [1]], c='r', s=30)
plt.scatter(X[250:500, [0]], X[250:500, [1]], c='g', s=30)
plt.scatter(2, 1, c='k', s=100)
plt.text(s='初始点1$(2,1)$', x=2, y=1, fontproperties=font, fontsize=15)
plt.scatter(2, 2, c='b', s=100)
plt.text(s='初始点2$(2,2)$', x=2, y=2, fontproperties=font, fontsize=15)
plt.scatter(-1.2, 0.2, c='k', s=100)
plt.text(s='中心点1$(-1.2,0.2)$', x=-1.2, y=0.2, fontproperties=font, fontsize=15)
plt.scatter(1, -0.2, c='b', s=100)
plt.text(s='中心点1$(1,-0.2)$', x=1, y=-0.2, fontproperties=font, fontsize=15)
plt.show()
以上图举例,k均值算法则是随机定义两个点$(2,1)、(2,2)$,然后可以使用k均值算法慢慢收敛,初始点最后会收敛到两个簇的中心,距离中心点更近的将被划入中心点代表的簇。(注:此处只是为了方便举例,并不是使用了真正的k均值算法聚类)
1.9 集成学习简介
# 集成学习简介图例
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc', size=15)
fig1 = plt.figure()
ax1 = fig1.add_subplot(111, aspect='equal')
ax1.add_patch(patches.Rectangle((1, 1), 5, 1.5, color='b'))
plt.text(2.6, 3.5, s='$\cdots$', fontsize=30)
ax1.add_patch(patches.Rectangle((1, 5), 5, 1.5, color='b'))
ax1.add_patch(patches.Rectangle((1, 7), 5, 1.5, color='b'))
plt.text(3.5, 7.5, s='个体学习器$_1$', fontsize=20, color='white',
ha='center', fontproperties=font)
plt.text(3.5, 5.5, s='个体学习器$_2$', fontsize=20, color='white',
ha='center', fontproperties=font)
plt.text(3.5, 1.5, s='个体学习器$_T$', fontsize=20, color='white',
ha='center', fontproperties=font)
plt.annotate(s='', xytext=(6, 7.8), xy=(8, 4.7),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3", color='orange'))
plt.annotate(s='', xytext=(6, 5.8), xy=(8, 4.2),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3", color='orange'))
plt.annotate(s='', xytext=(6, 1.7), xy=(8, 4.0),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3", color='orange'))
ax1.add_patch(patches.Rectangle((8, 3.4), 4, 2, color='g'))
plt.text(10, 4.2, s='结合模块', fontsize=20, color='white',
ha='center', fontproperties=font)
plt.annotate(s='', xytext=(12, 4.2), xy=(13, 4.2),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3", color='orange'))
ax1.add_patch(patches.Rectangle((13, 3.4), 4, 2, color='purple'))
plt.text(15, 4.2, s='强学习器', fontsize=20, color='white',
ha='center', fontproperties=font)
plt.annotate(s='', xytext=(17, 4.2), xy=(18, 4.2),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3", color='orange'))
plt.text(19, 4, s='输出', fontsize=20, color='r',
ha='center', fontproperties=font)
plt.xlim(0, 20)
plt.ylim(0, 10)
plt.show()
如上图所示,集成学习可以理解成,若干个个体学习器,通过结合策略构造一个结合模块,形成一个强学习器。其中所有的个体学习器中,可以是相同类型也可以是不同类型的个体学习器。
因此为了获得强学习器,我们首先得获得若干个个体学习器,之后选择一种较好的结合策略。
1.9.1 个体学习器
上一节我们讲到,构造强学习器的所有个体学习器中,个体学习器可以是相同类型的也可以是不同类型的,对于相同类型的个体学习器,这样的集成是同质(homogeneous)的,例如决策树集成中全是决策树,神经网络集成中全是神经网络;对于不同类型的个体学习器,这样的集成是异质(heterogenous)的,例如某个集成中既含有决策树,又含有神经网络。
目前最流行的是同质集成,在同质集成中,使用最多的模型是CART决策树和神经网络,并且个体学习器在同质集成中也被称为弱学习器(weak learner)。按照同质弱学习器之间是否存在依赖关系可以将同质集成分类两类:第一个是弱学习器之间存在强依赖关系,一系列弱学习器基本都需要串行生成,代表算法是Boosting系列算法;第二个是弱学习器之间没有较强的依赖关系,一系列弱学习器可以并行生成,代表算法是Bagging系列算法,Baggin系列算法中最著名的是随机森林(random forest)。
1.9.2 Boosting系列算法
Boosting是一种可将弱学习器提升为强学习器的算法。它的工作机制为:先从初始训练集中训练出一个弱学习器,再根据弱学习器的表现对训练样本分布进行调整,使得先前弱学习器训练错误的样本权重变高,即让错误样本在之后的弱学习器中受到更多关注,然后基于调整后的样本分布来训练下一个弱学习器。
不断重复上述过程,直到弱学习器数达到事先指定的数目$T$,最终通过集合策略整合这$T$个弱学习器,得到最终的强学习器。
Boosting系列算法中最著名的算法有AdaBoost算法和提升树(boosting tree)系列算法,提升树系列算法中应用最广泛的是梯度提升树(gradient boosting tree)。
Boosting由于每一个弱学习器都基于上一个弱学习器,因此它的偏差较小,即模型拟合能力较强,但是模型泛化能力会稍差,即方差偏大,而Boosgting则是需要选择一个能减小方差的学习器,一般选择较简单模型,如选择深度很浅的决策树。
1.9.3 Bagging系列算法
Boosting的弱学习器之间是有依赖关系的,而Bagging的弱学习器之间是没有依赖关系的,因此它的弱学习器是并行生成。
Bagging的弱学习器的训练集是通过随机采样得到的。通过$T$次的随机采样,我们可以通过自主采样法(bootstrap sampling)得到$T$个采样集,然后对于这$T$个采样集独立的训练出$T$个弱学习器,之后我们通过某种结合策略将这$T$个弱学习器构造成一个强学习器。
Bagging系列算法中最著名的算法有随机森林,但是随机森林可以说是一个进阶版的Bagging算法,虽然随机森林的弱学习器都是决策树,但是随机森林在Baggin的样本随机采样的基础上,又进行了特征的随机选择。
Bagging由于通过随机采样获得数据,因此它的方差较小,即模型泛化能力较强,但是模型拟合能力较弱,即偏差偏大,而Bagging则是需要选择一个能减小偏差的学习器,一般选择较复杂模型,如选择深度很深的决策树或不剪枝的决策树。
1.10 降维算法简介
1.10.1 维数灾难和降维
对于高维数据,会出现数据样本稀疏、距离计算困难等问题。尤其是在KNN算法中这种问题会被放大,而其他的机器学习算法也会因为高维数据对训练模型造成极大的障碍,这种问题一般被称为维数灾难(curse of dimensionality)。
解决维数灾难最常用的方法是降维(dimension reduction),即通过某种数学变换将原始高维特征空间转变为一个低维子空间,在这个子空间中样本密度大幅提高,距离计算也变得更容易。
# 维数灾难和降维图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.decomposition import PCA
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
np.random.seed(0)
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0, 100, size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, size=100)
pca = PCA(n_components=1)
X_reduction = pca.fit_transform(X)
X_restore = pca.inverse_transform(X_reduction)
plt.scatter(X[:, 0], X[:, 1], color='g', label='原始数据')
plt.scatter(X_restore[:, 0], X_restore[:, 1],
color='r', label='降维后的数据')
plt.annotate(s='', xytext=(40, 60), xy=(65, 30),
arrowprops=dict(arrowstyle='-', color='b', linewidth=5))
plt.legend(prop=font)
plt.show()
如上图所示,绿点即原始高维空间中的样本点,红点即我们降维后的样本点。由于图中的高维是二维,低维是一维,所以样本在低维空间是一条直线。
接下来我们的目标就是聊一聊如何做到把高维空间样本点映射到低维空间,即各种降维算法。
1.10.2 主成分分析
主成分分析(principal component analysis,PCA)是最常用的一种降维方法,我们已经利用“维数灾难和降维图例”解释了降维的过程,PCA的降维过程则是尽可能的使用数据最主要的特征来代表数据原有的所有特征。但是有没有同学想过为什么使用PCA降维是上图的红点组成的线而不是蓝线呢?这里就需要说到我们PCA的两个条件了。
对于“维数灾难和降维图例”中的红线和蓝线我们可以把它看成一个超平面$S$,理论上红线和蓝线构成的超平面都可以做到对样本特征的降维,但是一般我们希望这种能够做到降维的超平面满足以下两个条件
- 最近重构性:样本点到这个超平面的距离都足够近
- 最大可分性:样本点到这个超平面上的投影尽可能分开
基于最近重构性和最大可分性,就可以得到主成分分析的两种等价推导,也可以得出为什么红线是更合理的超平面。
1.11 本章小结
本章主要是带大家对传统机器学习的算法有一个大概的了解,由于神经网络可以理解成多个感知机组成的算法,此处不多介绍。后期进阶课程将会涉及神经网络以及深度学习。
由于本课程片应用,所以算法都是点到为止,如果需要对算法原理想要有一个清晰认识的同学,可以看我们未来的进阶课程,会详细介绍,每一个函数的损失函数、目标函数、目标函数优化问题为什么是这样的,敬请期待。