hadoop原理分析:强烈推荐阅读:https://www.saoniuhuo.com/article/detail-1124.html
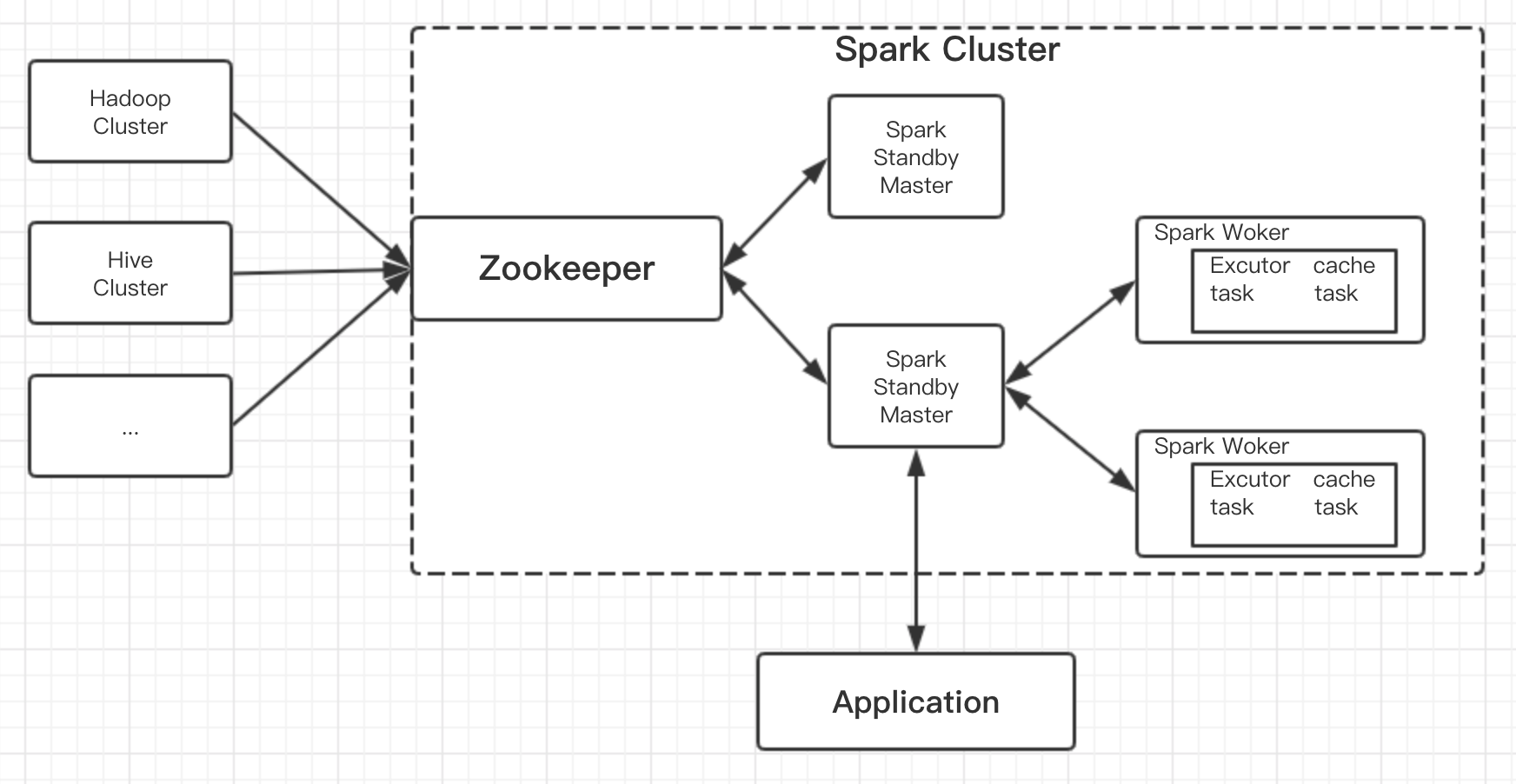
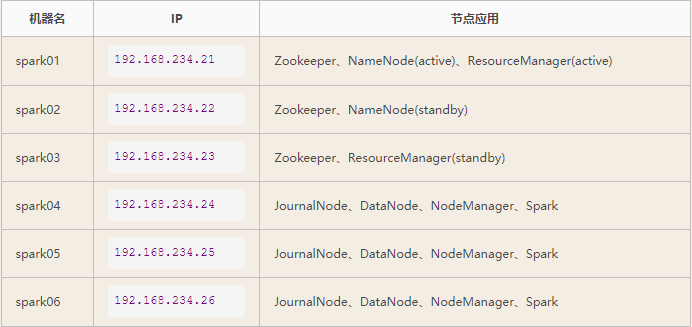
hadoop集群

如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
1、NameNode:
是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
nameNode概述
(1):nameNode是hdfs的核心.
(2):nameNode也称为Master
(3):nameNode存储hdfs的数据,文件系统中所有的文件目录树,并跟踪整个集群中的文件
(4):nameNode不存储实际数据或数据集.数据本身数据存储在dataNode中.
(5):nameNode知道Hdfs中任何给定文件的块列表及其位置.使用此信息nameNode知道如何从块中构建文件
(6):nameNode并不持久化存储每个文件中各个块所在的dataNode的位置信息,这些信息会在系统启动时从在数据节点重建.
(7):nameNode对于hdfs很重要,当nameNode关闭时,hdfs/hadoop集群无法访问.
(8):nameNode是hadoop集群中的单点故障
(9):nameNode所在机器通常会配置有大量内存(RAM).2、SecondaryNameNode:
是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
3、DataNode:
Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
dataNode概述
(1):dataNode负责将数据存储在Hdfs中
(2):dataNode也称为slave.
(3):nameNode和dataNode会保持不断通信
(4):dataNode启动时,他将自己发布到nameNode并汇报自己负责持有的块列表
(5):当某个nameNode关闭时,他不会影响数据或者集群的可用性.namnode将安排由其他DataNode管理的块副本复制
(6):DataNode所在机器通常配置有大量的硬盘空间.因为实际数据存储在dataNode中.
(7):dataNode会定期(dfs.heartbeat.interval配置项配置,默认是3秒)向nameNode发送心跳.如果nameNode长时间没有接收到dataNode发送的心跳,nameNode就会认为该DataNode失效.
(8):block汇报时间间隔取参数 dfs.blockreport.intersec,参数未配置默认为6小时4、热备份:
b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
5、冷备份:
b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
6、HDFS
(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
HDFS有很多特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重
hdfs读取文件流程
(1):Client向nameNode发起rpc请求,来确定请求文件block所在的位置;
(2):NameNode会视情况返回文件的部分或者全部block列表,对于每个block,nameNode都会返回含有该block副本的dataNode地址
(3):这些返回的DN地址,会按照集群拓扑结构得出dataNode与客户端的距离,然后进行排序,排序两个规测,网络拓扑结构中距离client近的排靠前;心跳机制中超时汇报的DN状态为STALE,这样的排靠后;
(4):client选取排序靠前的dataNode来读取block,如果客户端本身就是dataNode,那么将从本地直接获取数据.
(5):底层上本质是建立socket stream (FSDataInputStream),重复的调用父类的dataInputStream的read方法,直到这个快上得数据读取完毕;
(6):当读完列表的block后,若文件读取还没有结束,客户端会继续向nameNode获取下一批block列表;
(7):读取完一个block都会进行checksum验证,如果读取dataNode时出现错误,客户端会通知nameNode,然后在从下一个拥有该block副本的开始
hdsf上传文件详细原理见
https://www.saoniuhuo.com/article/detail-1124.html
https://www.cnblogs.com/liuwei6/p/6680188.html
https://www.cnblogs.com/laov/p/3434917.html
hdfs原理生动介绍:https://bbs.huaweicloud.com/blogs/218062