内存分布与栈逃逸
一 储备知识
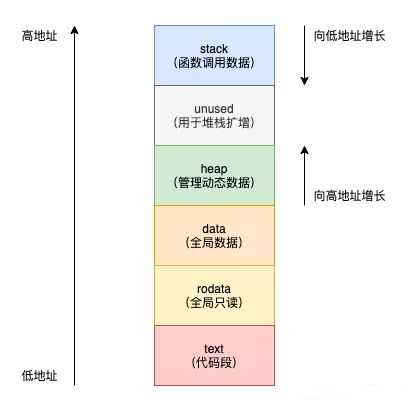
1.1 程序的内存布局
程序的内存布局图如下
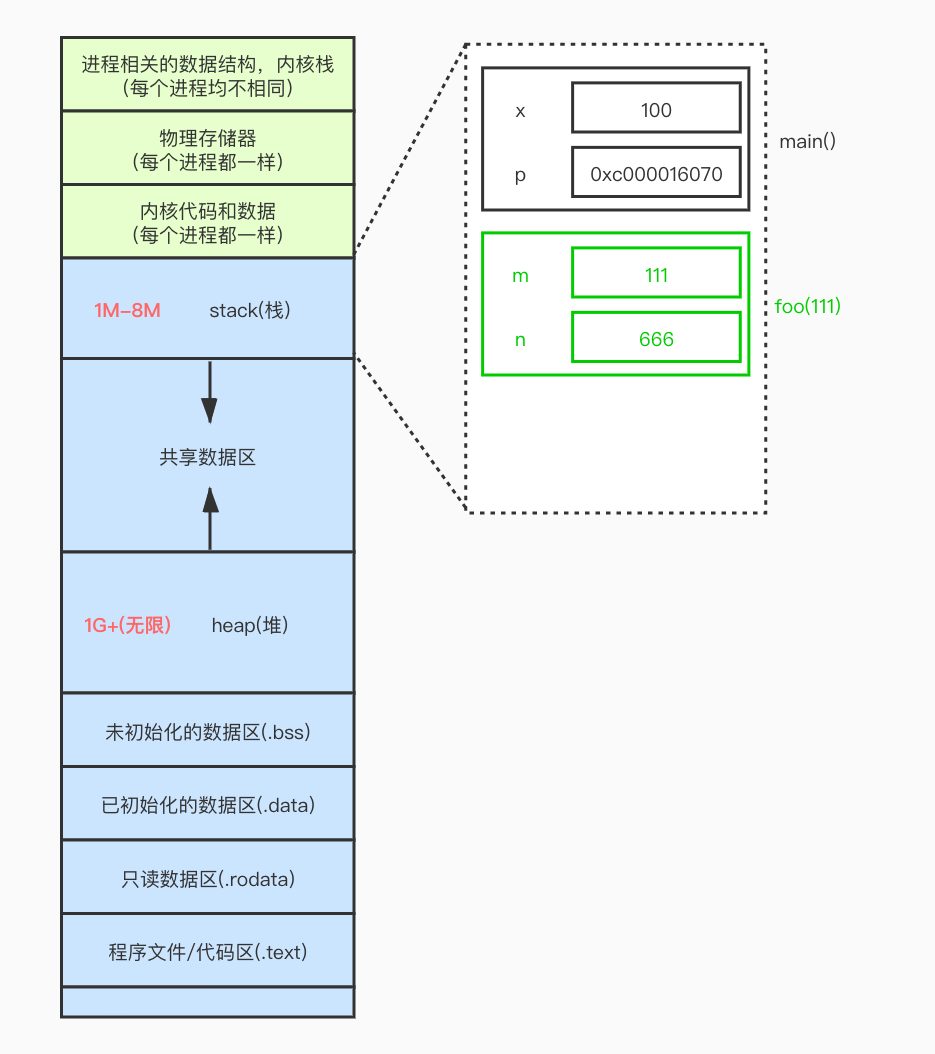
参见上图我们从下往上介绍
-
1、代码区.text:存放CPU执行的机器指令,代码区是可共享,并且是只读的。
-
2、数据区.rodata与.data:存放已初始化的全局变量、静态变量(全局和局部)、常量数据。
-
3、.bss区:存放的是未初始化的全局变量和静态变量。
-
4、堆区与栈区
- 4.1 栈区:由操作系统管理,自动回收
首先在编译时由编译器自动分配释放好,然后在程序运行时,栈区由操作系统自动管理,无须程序员手动管理。存放函数的参数值、返回值和局部变量。向下增长- 4.2 堆区:由应用程序来管,程序内若没有提供自动的垃圾回收机制,则需要程序员手动管理。
堆是由malloc()函数分配的内存块,向上增长。使用free()函数来释放内存,堆的申请释放工作是由gc垃圾回收机制或程序员手动来控制的,容易产生内存泄漏
1.2 栈帧空间
栈帧顾名思义是位于stack(栈)区上开辟的内存空间,当函数调用时, 则会在栈区产生栈帧; 函数调用结束, 释放栈帧。
既然栈帧用来给函数运行提供内存空间, 那栈帧用具体存放了什么呢?
- 1、局部变量
- 2、形参(形参其实就是包裹在函数内最开头的局部变量)
- 3、内存字段描述值
举例:
package main
import "fmt"
func foo(m int){
var n int = 555
n += m
}
func main() {
var x int = 100
var p *int = &x
x = 200
fmt.Println("x: ", x) // 200
fmt.Println("*p: ", *p) // 200
//*p=300等同于x=300
*p = 300
fmt.Println("x: ", x) // 300
fmt.Println("*p: ", *p) // 300
foo(111)
}当我们的程序运行时, 首先运行 main(), 这时就产生了一个栈帧.
当运行到 var x int = 100 时, 就会在栈帧里面产生一个空间.
同理, 运行到 var p *int = &x 时也会在栈帧里产生一个空间.
如下图所示
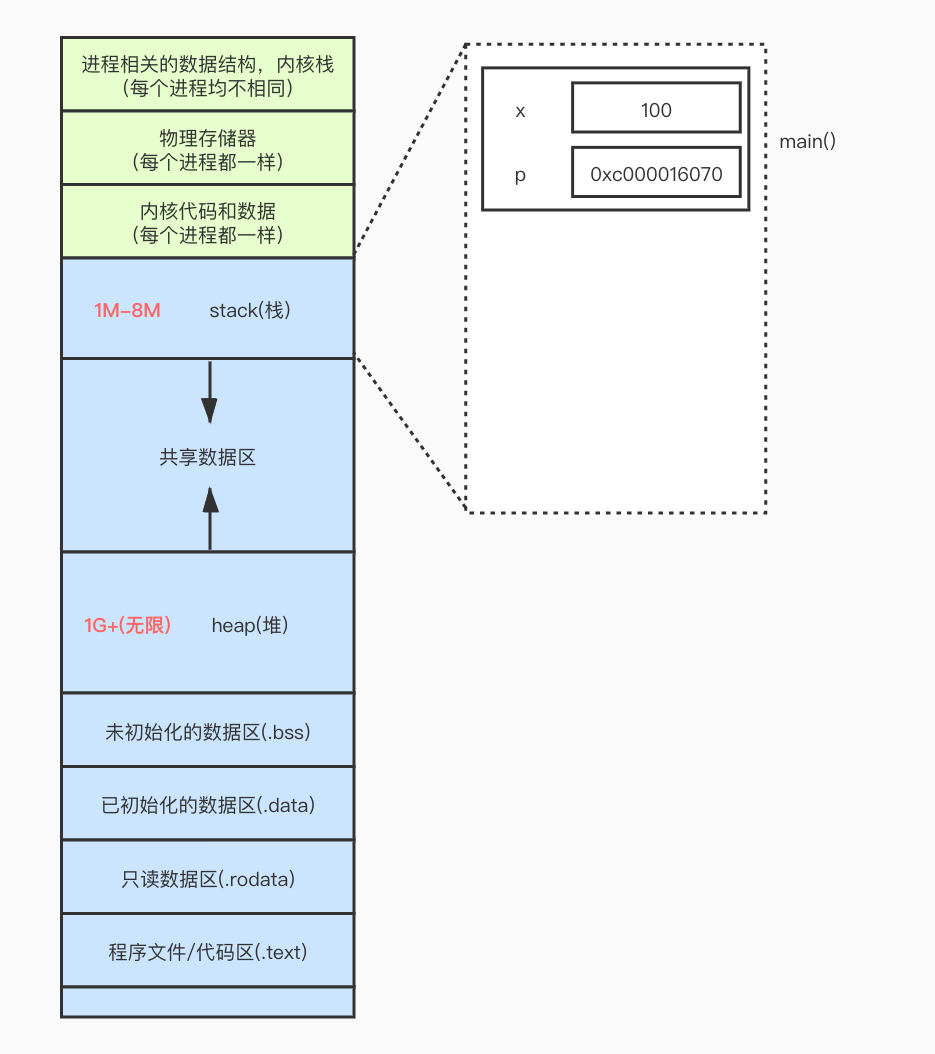
当运行到 foo(111) 时, 会继续产生一个栈帧, 这时 main() 产生的栈帧还没有结束.
当 foo(111) 运行完毕时, 就会释放掉这个栈帧.
二 栈区堆区
2.1 栈区与堆区的特点
变量所占用的内存空间在底层上分为栈区与堆区,并且栈区与堆区的分配是在编译阶段就确立的
总结栈区与堆区的特点如下
-
1、栈区
- (1)管理:由操作系统自动申请、分配、释放,称之为静态分配
- (2)大小:一般不会太大
- (3)内容:声明在包级或函数内的局部变量/形参都会存放在栈上
- (4)速度:分配速度相对堆区较快
-
2、堆区
- (1)管理
一般来讲是人为手动申请、分配、释放,称之为动态分配。堆区在C/C++中需要人为手动管理,而在go、java、python中有自动的垃圾回收机制来管理
- (2)大小
堆适合不可预知大小的内存分配,为此付出的代价是分配速度较慢,而且会形成内存碎片。
- (3)内容
一般会存放较大的对象,例如一般go程序调用
make()或者new()出来的都存储在用户区的heap(堆)区- (4)速度
分配速度相对栈区较慢,涉及到的指令动作也相对多
此外,栈区的内容也有可能会逃逸到堆区上,这种机制称之为栈逃逸,大致有以下几种情况
函数运行完毕,
1、如果数据跟外界无关,那么栈帧就被系统回收
2、如果有关联,那么就逃逸到堆区被gc回收
还有就是main函数拉起了整个程序,程序运行的整个周期内它都不会结束,所以main的栈帧与其他函数不同,除非程序结束,否则是不会被回收的,所以main内引用的变量,会在不用时逃逸到堆区,这样就可以不必等程序结束就回收数据了。
详见下一小节
2.2 栈区堆区分配与逃逸
2.2.1 c的内存分配与go的自动内存分配
在C语言中,栈区与堆区的分配需要程序员手动管理,而Go语言则将这一管理整合到了编译器中,栈区与堆区的分配是由编译器在程序编译阶段就自行确立的,以此来提高程序运行时效率。2.2.2 逃逸介绍
什么是逃逸?什么是逃逸分析?什么阶段确立/决定逃逸?
在Go语言中,Go编译器会优先将数据分配到栈区,堆区作为第二存储位置,变量存储空间由优先的栈区被分配到了堆区上,称之为”逃逸“,或称”栈逃逸“,意旨由栈区逃跑到了堆区上。至于何种变量会被分配到堆区(heap)上,编译器会在编译阶段通过分析代码的特征和代码的生命周期来自行决定,这一分析过程称之为逃逸分析(escape analysis)2.2.3 为何需要逃逸
这个问题我们可以反过来想,如果变量都分配到堆上了会出现什么事情呢?如下
1、垃圾回收(GC)的压力不断增大
2、申请、分配、回收内存的系统开销增大(相对于栈)
3、动态分配产生一定量的内存碎片
其实总的来说,就是频繁申请、分配堆区内存是有一定“代价”的。会影响应用程序运行的效率,间接影响到整体系统。因此 “按需分配” 最大限度的灵活利用资源,才是正确的治理之道。这就是为什么需要逃逸分析的原因。2.2.4 程序员该如何看待逃逸分析
在使用Go语言进行编程时,Go语言的设计者不希望开发者将精力放在内存应该分配在栈还是堆的问题上,编译器会自动帮助开发者完成这个纠结的选择,但变量逃逸分析作为一个编译器技术,我们可以了解一下2.2.5 逃逸分析举例
!!!强调大前提!!!
编译器是在编译阶段通过分析代码的特征和代码的生命周期来自行决定栈区堆区分配的,所以说在go语言中,逃逸分析的结果是由具体的编码方式决定的,并不是由用var还是new声明变量的方式决定的。
例1:我们编写如下代码,对栈逃逸进行解析
package main
var global *int
func g() {
y := new(int)
*y = 1
}
func f() {
var x int
x = 1
global = &x
}
func main() {
g()
f()
}
分析前须知1
函数的参数变量和返回值变量都是局部变量,它们在函数每次被调用的时候创建,而每运行一个函数, 就会产生了一个栈帧,函数内的变量都存放于栈帧内,栈帧的空间会随着函数调用结束而被系统自动回收,此时并没有GC机制什么事,因为GC管理的就是堆区内容。 分析命令
$ go run -gcflags "-m -l" test.go
# command-line-arguments
./test1.go:6:10: new(int) does not escape // 第6行代码new(int)没有发生逃逸
./test1.go:11:6: moved to heap: x // 第11行代码创建的x移动到了堆区 函数g返回时,变量y不再可达,即函数g内的变量从始至终都处于函数栈帧内,并无逃逸一说,会在函数返回时由系统自动回收栈帧空间。
f函数里的x变量最先被分配到了函数的栈帧空间内,而我们知道在函数f调用完毕后,函数的栈帧就被系统回收,但是因为变量x的地址赋值给了包一级的变量global,所以此时虽然函数f已经结束但变量x仍然是可达的,在底层若想保持函数内的变量x的可访达性,则必须将其分配到堆区上,以防止随栈帧空间一起销毁,这就叫“栈逃逸”,形象一点说就是:因为害怕留在栈区内而被系统连同函数栈帧内所有变量一并带走/团灭而逃了堆区上。堆区的内容被GC机制接管,直到变量不可访达便会被GC回收。
其实,编译器可以选择在栈区分配*y的存储空间,也可以选择在堆区上分配,这一切均由编译器决定,即便是我们之前提到的内置函数new创建的,我说的也是一般情况下new()出来的都存储在用户区的heap(堆)区,而非绝对。所以"逃逸"这一术语是对明确被分配到堆区的一种概括的说法,并非是真的全都是由栈区逃逸到堆区的,可能一开始就是被分配到了堆区。
例2:我们编写如下代码,对栈逃逸进行解析
package main
import "fmt"
func dummy(b int) int {
var c int
c = b
return c
}
func main() {
var a int
fmt.Println(a)
fmt.Println(dummy(0))
} 分析命令
$ go run -gcflags "-m -l" test.go
# command-line-arguments
./test.go:13:13: ... argument does not escape
./test.go:13:13: a escapes to heap // a逃逸到了堆区
./test.go:14:13: ... argument does not escape
./test.go:14:19: dummy(0) escapes to heap // 函数的返回值逃逸到了堆区
0
0 函数在运行时,如果变量不再被引用了不应该一直等到函数完全结束后随着栈帧一起被带走/回收,应该逃逸到栈上被GC机制回收,所以main函数中的a也出现了逃逸。
dummy(0)虽然调用完了,但它的返回值在被引用了(main函数中的fmt.Println),所以它的返回值不应该随着栈帧的消亡而一起消亡,所以也发生了逃逸。
2.2.6 函数的传参
明白了上面的内容, 我们再去了解指针作为函数参数就会容易很多.
传递的参数可以分为两种:
- 1、传地址(引用): 将地址值作为函数参数传递.
- 2、传值(数据): 将实参的值拷贝一份给形参.
无论是传地址还是传值, 都是实参将自己的值拷贝一份给形参.只不过这个值有可能是地址, 有可能是数据.
所以, 函数传参永远都是值传递.
了解了概念之后, 我们来看一个经典的例子:
package main
import "fmt"
func swap(x, y int){
x, y = y, x
fmt.Println("swap x: ", x, "y: ", y)
}
func main(){
x, y := 10, 20
swap(x, y)
fmt.Println("main x: ", x, "y: ", y)
}结果:
swap x: 20 y: 10
main x: 10 y: 20我们先来简单分析一下为什么不一样.
首先当运行 main() 时, 系统在栈区产生一个栈帧, 该栈帧里有 x 和 y 两个变量.
当运行 swap() 时, 系统在栈区产生一个栈帧, 该栈帧里面有 x 和 y 两个变量.
运行 x, y = y, x 后, 交换 swap() 产生的栈帧里的 xy 值. 这时 main() 里的 xy 没有变.
swap() 运行完毕后, 对应的栈帧释放, 栈帧里的x y 值也随之消失.
所以, 当运行 fmt.Println("main x: ", x, "y: ", y) 这句话时, 其值依然没有变.
接下来我们看一下参数为地址值时的情况.
传地址的核心思想是: 在自己的栈帧空间中修改其它栈帧空间中的值.
而传值的思想是: 在自己的栈帧空间中修改自己栈帧空间中的值.
注意理解其中的差别.
继续看以下这段代码:
package main
import "fmt"
func swap2(a, b *int){
*a, *b = *b, *a
}
func main(){
x, y := 10, 20
swap2(&x, &y)
fmt.Println("main x: ", x, "y: ", y)
}结果:
main x: 20 y: 10这里并没有违反 函数传参永远都是值传递 这句话, 只不过这个时候这个值为地址值.
这个时候, x 与 y 的值就完成了交换.
我们来分析一下这个过程.
首先运行 main() 后创建一个栈帧, 里面有 x y 两个变量.
运行 swap2() 时, 同样创建一个栈帧, 里面有 a b 两个变量.
注意这个时候, a 和 b 中存储的值是 x 和 y 的地址.
当运行到 *a, *b = *b, *a 时, 左边的 *a 代表的是 x 的内存地址, 右边的 *b 代表的是 y 的内存地址中的内容. 所以这个时候, main() 中的 x 就被替换掉了.
所以, 这是在 swap2() 中操作 main() 里的变量值.
现在 swap2() 再释放也没有关系了, 因为 main() 里的值已经被改了.
2.2.7 了解
其实,在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
Go语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)。
在本文介绍了逃逸分析的概念和规则,并列举了一些例子加深理解。但实际肯定远远不止这些案例,遇到具体的情况可以根据代码具体分析就好。其实了解就可以了
-
静态分配到栈上,性能一定比动态分配到堆上好
-
底层分配到堆,还是栈。实际上对你来说是透明的,不需要过度关心
-
每个 Go 版本的逃逸分析都会有所不同(会改变,会优化)
-
直接通过
go build -gcflags '-m -l'就可以看到逃逸分析的过程和结果逃逸分析方法有两种: // 第一 通过编译器命令,就可以看到详细的逃逸分析过程。而指令集 -gcflags 用于将标识参数传递给 Go 编译器,涉及如下: -m 会打印出逃逸分析的优化策略,实际上最多总共可以用 4 个 -m,但是信息量较大,一般用 1 个就可以了 -l 会禁用函数内联,在这里禁用掉 inline 能更好的观察逃逸情况,减少干扰 $ go build -gcflags '-m -l' main.go // 第二 通过反编译命令查看 $ go tool compile -S main.go 注:可以通过 go tool compile -help 查看所有允许传递给编译器的标识参数 -
到处都用指针传递并不一定是最好的,要用对
待补充:============================
逃逸分析
所谓逃逸分析(Escape analysis)是指由编译器决定内存分配的位置,不需要程序员指定。 函数中申请一个新的对象
- 如果分配在栈中,则函数执行结束可自动将内存回收;
- 如果分配在堆中,则函数执行结束可交给GC(垃圾回收)处理;
有了逃逸分析,返回函数局部变量将变得可能,除此之外,逃逸分析还跟闭包息息相关,了解哪些场景下对象会逃逸至关重要。
逃逸策略
每当函数中申请新的对象,编译器会跟据该对象是否被函数外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中;
- 如果函数外部存在引用,则必定放到堆中;
注意,对于函数外部没有引用的对象,也有可能放到堆中,比如内存过大超过栈的存储能力
逃逸场景
指针逃逸
我们知道GC可以返回局部变量的指针,这其实是一个典型的变量逃逸案例,代码如下:
package main
type Student struct {
Name string
Age int
}
func StudentRegister(name string, age int) *Student {
s := new(Student) //局部变量s逃逸到堆
s.Name = name
s.Age = age
return s
}
func main() {
StudentRegister("Jim", 18)
}函数StudentRegister()内部s为局部变量,其值通过函数返回值返回,s本身为一指针,其指向的内存地址不会是栈而是堆,这就是典型的逃逸案例。
通过编译参数-gcflag=-m可以查年编译过程中的逃逸分析:
D:\SourceCode\GoExpert\src>go build -gcflags=-m
# _/D_/SourceCode/GoExpert/src
.\main.go:8: can inline StudentRegister
.\main.go:17: can inline main
.\main.go:18: inlining call to StudentRegister
.\main.go:8: leaking param: name
.\main.go:9: new(Student) escapes to heap
.\main.go:18: main new(Student) does not escape可见在StudentRegister()函数中,也即代码第9行显示”escapes to heap”,代表该行内存分配发生了逃逸现象。
栈空间不足逃逸
package main
func Slice() {
s := make([]int, 1000, 1000)
for index, _ := range s {
s[index] = index
}
}
func main() {
Slice()
}上面代码Slice()函数中分配了一个1000个长度的切片,是否逃逸取决于栈空间是否足够大。 直接查看编译提示,如下:
D:\SourceCode\GoExpert\src>go build -gcflags=-m
# _/D_/SourceCode/GoExpert/src
.\main.go:4: Slice make([]int, 1000, 1000) does not escape我们发现此处并没有发生逃逸。那么把切片长度扩大10倍即10000会如何呢?
D:\SourceCode\GoExpert\src>go build -gcflags=-m
# _/D_/SourceCode/GoExpert/src
.\main.go:4: make([]int, 10000, 10000) escapes to heap我们发现当切片长度扩大到10000时就会逃逸。
实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
动态类型逃逸
很多函数参数为interface类型,比如fmt.Println(a …interface{}),编译期间很难确定其参数的具体类型,也人产生逃逸。 如下代码所示:
package main
import "fmt"
func main() {
s := "Escape"
fmt.Println(s)
}上述代码s变量只是一个string类型变量,调用fmt.Println()时会产生逃逸:
D:\SourceCode\GoExpert\src>go build -gcflags=-m
# _/D_/SourceCode/GoExpert/src
.\main.go:7: s escapes to heap
.\main.go:7: main ... argument does not escape闭包引用逃逸
某著名的开源框架实现了某个返回Fibonacci数列的函数:
func Fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}该函数返回一个闭包,闭包引用了函数的局部变量a和b,使用时通过该函数获取该闭包,然后每次执行闭包都会依次输出Fibonacci数列。 完整的示例程序如下所示:
package main
import "fmt"
func Fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := Fibonacci()
for i := 0; i < 10; i++ {
fmt.Printf("Fibonacci: %d\n", f())
}
}上述代码通过Fibonacci()获取一个闭包,每次执行闭包就会打印一个Fibonacci数值。输出如下所示:
D:\SourceCode\GoExpert\src>src.exe
Fibonacci: 1
Fibonacci: 1
Fibonacci: 2
Fibonacci: 3
Fibonacci: 5
Fibonacci: 8
Fibonacci: 13
Fibonacci: 21
Fibonacci: 34
Fibonacci: 55Fibonacci()函数中原本属于局部变量的a和b由于闭包的引用,不得不将二者放到堆上,以致产生逃逸:
D:\SourceCode\GoExpert\src>go build -gcflags=-m
# _/D_/SourceCode/GoExpert/src
.\main.go:7: can inline Fibonacci.func1
.\main.go:7: func literal escapes to heap
.\main.go:7: func literal escapes to heap
.\main.go:8: &a escapes to heap
.\main.go:6: moved to heap: a
.\main.go:8: &b escapes to heap
.\main.go:6: moved to heap: b
.\main.go:17: f() escapes to heap
.\main.go:17: main ... argument does not escape逃逸总结
- 栈上分配的对象比在堆中分配的有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕后会交给GC处理
- 逃逸分析目的是决定内存分配地址是栈还是堆
- 逃逸分析在编译阶段完成
编程Tips
思考一下这个问题:函数传递指针真的比传值效率高吗? 我们知道传递指针可以减少底层值的拷贝,可以提高效率,但是如果拷贝的数据量小,由于指针传递会产生逃逸,可能会使用堆,也可能会增加GC的负担,所以传递指针不一定是高效的。