一、cpu与gpu的区别
cpu:擅长逻辑控制,串行的运算,cpu就好像是一个厉害的老博士,任何复杂的数学题都会
gpu:擅长大规模并发计算,gpu就好像是一群只会简单加减法的小学生,每个小学生都只能算简单的题目,但是gpu是组织了一大群小学生一起来算
现实场景,比如人工智能领域的图像识别,需要的不是大量复杂的逻辑判断与运算,而是大量的简单运算,此时cpu就不好用了,gpu最合适
GPU的工作大部分就是这样,计算量大,但没什么技术含量,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?GPU就是这样,用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如你说的破解密码,挖矿和很多图形学的计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。但还有一些任务涉及到“流”的问题。比如你去相亲,双方看着顺眼才能继续发展。总不能你这边还没见面呢,那边找人把证都给领了。这种比较复杂的问题都是CPU来做的。 总而言之,CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别。而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。
当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
cpu与gpu的设计区别:https://egonlin.com/?p=7543
拓展阅读
Nvidia中文名英伟达,1999年,NVIDIA定义了GPU,这极大地推动了PC游戏市场的发展,重新定义了现代计算机图形技术,并彻底改变了并行计算
NVIDIA Tesla GPU系列P4、T4、P40以及V100是Tesla GPU系列的明星产品
当下计算行业正在从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展。
CPU负责数据的逻辑处理,然后将处理好的数据交给GPU进行大规模的运算。
为此,NVIDIA™(英伟达™)发明了CUDA这一编程模型,它提供了可以直接调用GPU硬件接口,可用于在应用程序中充分利用CPU和GPU各自的优点
二、在容器中使用gpu
2.1 nvidia-docker1.0
NVIDIA于2016年开始设计NVIDIA-Docker已便于容器使用NVIDIA GPUs。
第一代nvidia-docker1.0实现了对docker client的封装,并在容器启动时,将必要的GPU device和libraries挂载到容器中。但是这种设计的方式高度的与docker运行时耦合,缺乏灵活性。存在的缺陷具体如下:
- 设计高度与docker耦合,不支持其它的容器运行时。如: LXC, CRI-O及未来可能会增加的容器运行时。
- 不能更好的利用docker生态的其它工具。如: docker compose。
- 不能将GPU作为调度系统的一种资源来进行灵活的调度。
- 完善容器运行时对GPU的支持。如: 自动的获取用户层面的NVIDIA Driver libraries, NVIDIA kernel modules, device ordering等。
基于上面描述的这些弊端,NVIDIA开始了对下一代容器运行时的设计: nvidia-docker2.0。
2.2 nvidia-docker2.0
先简单介绍下nvidia-docker 2.0与ontainerd、vidia-container-runtime、ibnvidia-container以及runc之间的关系
它们之间的关系可以通过下面这张图关联起来:
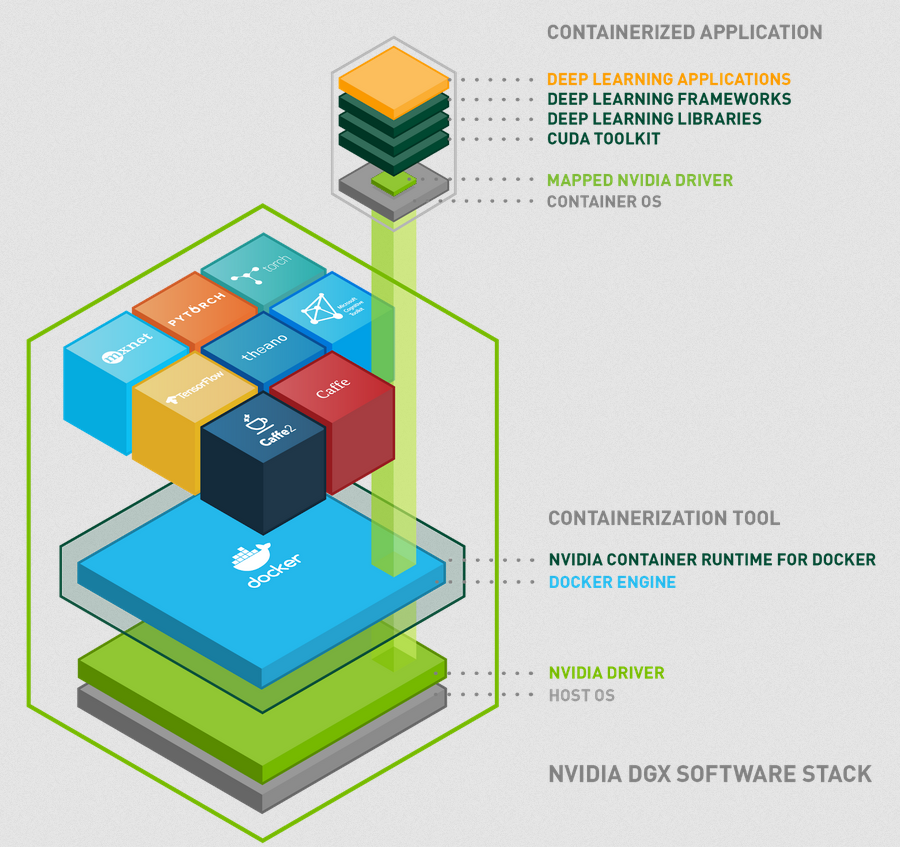
- 1、nvidia-docker 2.0
nvidia-docker2.0 是一个简单的包,它主要通过修改docker的配置文件/etc/docker/daemon.json来让docker使用NVIDIA Container runtime。 - 2、nvidia-container-runtime
nvidia-container-runtime 才是真正的核心部分,它在原有的docker容器运行时runc的基础上增加一个prestart hook,用于调用libnvidia-container库。 - 3、libnvidia-container
libnvidia-container 提供一个库和一个简单的CLI工具,使用这个库可以使NVIDIA GPU被Linux容器使用。 - 4、Containerd
Containerd主要负责的工作是:- 管理容器的生命周期(从容器的创建到销毁)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用runc 运行容器
- 管理容器的网络接口及网络
containerd接收到请求之后,做好相关的准备工作,可以选择自己调用runc也可以通过创建containerd-shim再去调用runc,而runc基于OCI文件对容器进行创建。
- 5、RunC
RunC 是一个轻量级的工具,它是用来运行容器的,只用来做这一件事,并且这一件事要做好。我们可以认为它就是个命令行小工具,可以不用通过 docker 引擎,直接Runc运行容器。事实上,runC 是标准化的产物,它根据 OCI 标准来创建和运行容器。而 OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准。直接使用RunC的命令行即可以完成创建一个容器,并提供了简单的交互能力。
上面已经介绍个各个组件的作用以及它们之间的关系,接下来详细的描述下这张图:
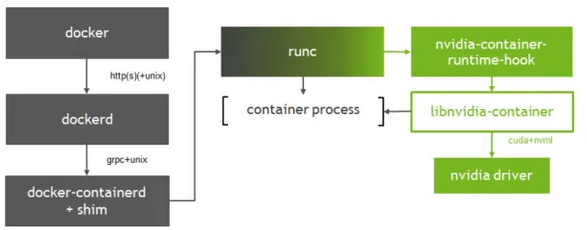
-
1、正常创建一个容器的流程是这样的:
docker –> dockerd –> containerd–> containerd-shim –>runc –> container-process
docker客户端将创建容器的请求发送给dockerd, 当dockerd收到请求任务之后将请求发送给containerd, containerd经过查看校验启动containerd-shim或者自己来启动容器进程。
创建一个使用GPU的容器 -
2、创建GPU容器的流程如下:
docker–> dockerd –> containerd –> containerd-shim–> nvidia-container-runtime –> nvidia-container-runtime-hook –> libnvidia-container –> runc — > container-process
基本流程和不使用GPU的容器差不多,只是把docker默认的运行时替换成了NVIDIA自家的nvidia-container-runtime。
这样当nvidia-container-runtime创建容器时,先执行nvidia-container-runtime-hook这个hook去检查容器是否需要使用GPU(通过环境变NVIDIA_VISIBLE_DEVICES来判断)。如果需要则调用libnvidia-container来暴露GPU给容器使用。否则走默认的runc逻辑。
说到这里nvidia-docker2.0的大体机制基本就通了。但是涉及到的nvidia-container-runtime, libnvidia-container, containerd,runc这些项目, 这本篇文章里面就不一一介绍了。如果感兴趣可以自行去探索学习。这些项目的地址在文章中都已经做个相关的链接。
参考
NVidia Containter Runtime
NVidia Dev Blogs
OpenContainers Runtime Spec Config
OpenContainers Runtime Spec
NVidia Container Runtime
RunC
libnvidia container
2.3 docker19使用GPU
随着docker的不断升级,对GPU的支持也越来越友好,尤其是docker19.03之后,不再需要安装nvidia-docker了。只安装NVIDIA-CONTAINER-RUNTIME就可以使用了,并且支持docker-compose。
本文记录和梳理一下想要在docker中使用GPU,都需要做些什么。
(1)下载GPU的驱动
在NVIDIA驱动程序页面下载对应的驱动。
(2)安装NVIDIA-CONTAINER-RUNTIME
在https://nvidia.github.io/nvidia-container-runtime/查看支持的操作系统和版本,并根据对应选项,添加源,因为我是centos7.6,所以添加方式为:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-runtime.repo在参考https://github.com/NVIDIA/nvidia-container-runtime后,得知直接安装即可
sudo yum install nvidia-container-runtime(3) 直接使用
此时就准备好了GPU环境,在docker19下就能通过–gpus参数直接使用了,安装docker19略
查看–gpus 参数是否安装成功:
docker run --help | grep -i gpus
--gpus gpu-request GPU devices to add to the container ('all' to pass all GPUs)从Docker 19.03开始,安装好docker之后,只需要使用 –gpus 即可指定容器使用显卡。
1、# 如果镜像里没有cuda环境,那看不到cuda信息,显示结果为CUDA Version: N/A
docker run -it --rm --gpus all centos nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: N/A |
2、 强调采用的镜像里必须包含cuda
docker run -it --rm --gpus all nvidia/cuda:9.0-base nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |以上就完成了GPU的准备,可以使用了。(如果指定某一张卡可以使用选项:–gpus "device=0")
强调:容器内可以使用gpu的必备条件
1、物理机主机插有gpu卡
2、物理机操作系统安装了gpu驱动程序
3、安装了docker19.0.3版本
4、启动容器时采用临时参数–gpus指定启用gpu,或者修改配置文件永久修改
5、容器镜像必须包含cuda环境才能使用
当你发现容器内部发现CUDA Version: N/A,就是因为容器内没有cuda的driver接口,需要在镜像里定制好 ,如下制作一个带有cuda环境的java镜像(注意cuda版本)。
ROM nvidia/cuda:10.1-base
MAINTAINER scsyn
COPY ./jre1.8.0_271 /jre
ENV JRE_HOME=/jre
ENV CLASSPATH=$JRE_HOME/lib/rt.jar:$JRE_HOME/lib/ext
ENV PATH=$PATH:$JRE_HOME/bin使用docker build -t nvidia-java:1.0.0 .打包镜像。
之后再使用的话在此基础上进行封装就可以了,比如:
FROM nvidia-java:1.0.0
MAINTAINER scsyn
COPY ./en2zh /pn
ENV LD_LIBRARY_PATH=/pn/lib
WORKDIR "/pn/bin"
ENTRYPOINT ["java","-jar","localdeployment-pn-0.0.1-SNAPSHOT.jar"]更多操作
所有显卡都对容器可见:
docker run --gpus all --name 容器名 -d -t 镜像id
只有显卡1对容器可见:
docker run --gpus="1" --name 容器名 -d -t 镜像id
如果不指定 --gpus ,运行nvidia-smi 会提示Command not found
注意:
1. 显卡驱动在所有方式中,都要先安装好,容器是不会有显卡驱动的,一台物理机的显卡只对应一个显卡驱动,当显卡驱动安装好后(即使未安装cuda),也可以使用命令nvidia-smi
2. nvidia-smi显示的是显卡驱动对应的cuda版本,nvcc -V 显示的运行是cuda的版本
启动容器时,容器如果想使用gpu,镜像里必须有cuda环境,就是说,针对想使用gpu的容器,镜像在制作时必须吧cuda环境打进去
下面三个参数代表的都是是容器内可以使用物理机的所有gpu卡
--gpus all
NVIDIA_VISIBLE_DEVICES=all
--runtime=nvida
NVIDIA_VISIBLE_DEVICES=2 只公开两个gpu,容器内只能用两个gpu
举例如下:
# 使用所有GPU
$ docker run --gpus all nvidia/cuda:9.0-base nvidia-smi
# 使用两个GPU
$ docker run --gpus 2 nvidia/cuda:9.0-base nvidia-smi
# 指定GPU运行
$ docker run --gpus '"device=1,2"' nvidia/cuda:9.0-base nvidia-smi
$ docker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:9.0-base nvidia-smi2.4 修改容器的runtime为nvdia-runtime
如果我们嫌弃每次启动容器是都指定–gpus参数很麻烦,那么我们可以直接把默认的Runc替换为nvidia-runtime,这样每次你启动容器是,就不用加–gpus参数了,默认容器内就可以用gpu,当然容器镜像里有cuda环境
为docker环境安装Nvidia-container-runtime
1、对于已经安装好docker的CentOS系统
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | sudo tee /etc/yum.repos.d/nvidia-container-runtime.repo
yum install nvidia-container-runtime -y
# 离线现在,去本节的软件包目录获取nvida-runtime.tar.gz
解压后,执行yum localinstall即可2、对于已经安装好docker的Ubuntu系统
(1). 首先配置nvidia源
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | \
sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
sudo apt-get update(2)、参考https://gitee.com/wuxler/nvidia-container-runtime?_from=gitee_search 安装nvidia-container-runtime
sudo apt-get install nvidia-container-runtime
systemctl stop docker
把运行时添加到docker中,这个只是临时添加
dockerd --add-runtime=nvidia=/usr/bin/nvidia-container-runtime
把运行时添加到docker中,永久添加
[root@yq01-aip-aikefu19 ~]# systemctl stop docker
[root@yq01-aip-aikefu19 ~]# cat /etc/docker/daemon.json
{
"insecure-registries":["xxx-registry:5000", "xxx.xxx-int.com"],
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime", # 指定路径,还有id为nvida
"runtimeArgs": []
}
},
"default-runtime": "nvidia", # 然后设定默认的runtime
"data-root": "/data/lib/docker"
}
生效前查看默认的Runc
[root@yq01-aip-aikefu19 ~]# docker info |grep -iw runtime:
Default Runtime: nvidia
此时,启动容器如果不指定--gpus参数,那根本无法使用nvida-smi命令,会报exec format error执行格式错误
[root@yq01-aip-aikefu19 ~]# docker run --rm --name test nvidia/cuda:9.0-base nvidia-smi
重启让修改生效
[root@yq01-aip-aikefu19 ~]# systemctl start docker
重新查看,发现默认的runtime已经被替换为了nvidia-runtime
[root@yq01-aip-aikefu19 ~]# docker info |grep -iw runtime:
Default Runtime: runc(3)、验证
无需加--gpus参数,在容器内也能使用gpu
[root@yq01-aip-aikefu19 ~]# docker run --rm --name test nvidia/cuda:9.0-base nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+2.5 关于gpu信息的说明
显示所有GPU的当前信息状态:
nvidia-smi
查询所有GPU的当前详细信息:
nvidia-smi -q
设备监控命令,以滚动条形式显示GPU设备统计信息:
nvidia-smi dmon
进程监控命令,以滚动条形式显示GPU进程状态信息:
nvidia-smi pmon
实时监测并高亮显示状态:
watch -n 1 -d nvidia-smi,1代表间隔1s刷新。
