记录操作之增删改查
一、单表
1、 添加记录
准备表
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=20)
price = models.DecimalField(max_digits=65,decimal_places=5)
publish = models.CharField(max_length=30)
pub_date = models.DateTimeField(auto_now_add=True)
def __str__(self):
return "%s:%s:%s" %(self.id,self.title,self.price)添加记录的两种方式
# 方式一
obj=Book.objects.create(title="葵花宝典",price=100,publish="苹果出版社")
# 方式二:
obj=Book(title="九阴真经",price=100,publish="苹果出版社")
obj.save()添加n条记录为后续操作做准备
Book.objects.create(title="红龙梦",price=300,publish="66出版社")
Book.objects.create(title="钢弹是怎样炼成的",price=10,publish="新华出版社")
Book.objects.create(title="聊斋",price=50,publish="77出版社")
Book.objects.create(title="老女人与海王",price=30,publish="33出版社")
Book.objects.create(title="西游记",price=43,publish="88出版社")2、单表查询
查询API
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field): 对查询结果排序('-id')
<6> reverse(): 对且只对order_by排序的结果进行翻转
<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<9> first(): 返回QuerySet集中的第一个对象
<10> last(): 返回QuerySet集中的最后一个对象
<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False
<12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列
<13> values_list(*field): 它与values()非常相似,但返回的是一个元组序列
<14> distinct(): 从返回结果中剔除重复纪录示例
# QuerySet数据类型(类似于一个列表,里面放着一些对象)
# 1 方法的返回值是什么
# 2 方法的调用者
===============调用者为管理器,返回值为一个记录对象=========
obj = Book.objects.get(title="聊斋")
print(obj) # 结果为:Book object (5)
print(obj.title)
# 若找不到符合条件的记录则报错
Book.objects.get(title="跟Egon学养猪小妙招") # 报错
===============调用者为管理器,返回值为QuerySet=========
# 1、all:
book_list = Book.objects.all()
print(book_list) # 结果是一个QuerySet
print(book_list[0].title)
for obj in book_list:
print(obj.title)
# 2、filter
book_list = Book.objects.filter(title="聊斋") # 相当于where,还可以使用基于双下划线的模糊查询
# 3、exclude
book_list = Book.objects.exclude(title="聊斋") # 除了title="聊斋"之外的都留下来
===============调用者为QuerySet,返回值。。。=========
# 1、count(): 返回的是整型
n = Book.objects.all().count()
print(n) # 7
# 2、first():返回的是一个记录对象
obj = Book.objects.all().first()
print(obj)
print(obj.id) # 1
# 3、last():返回的是一个记录对象
obj = Book.objects.all().last()
print(obj)
print(obj.id) # 7
# 4、exists():返回的是布尔值
res = Book.objects.filter(title="跟Egon老师学算命").exists()
print(res) # False
# 5、order_by(*field):返回的同样是QuerySet
objs = Book.objects.filter(id__lte=6)
print(objs) # QuerySet
print(objs.order_by('price','-id')) # 先按照price字段升序排,若price相同则按照id字段降序排
# 6、reverse():返回的同样是QuerySet
objs = Book.objects.all()
无效
print([obj.id for obj in objs])
print([obj.id for obj in objs.reverse()]) # 顺序与上面保持一致
有效
print([obj.id for obj in objs.order_by('-id')])
print([obj.id for obj in objs.order_by('-id').reverse()]) # 顺序在上面的排序的基础上翻转
# 7、values(*field): 返回的同样是QuerySet
objs = Book.objects.filter(id__gte=3)
print(objs.values("title")) # 返回一个QuerySet
print(objs.values("title")[0]['title']) # 红龙梦
print(objs.values("title").last()['title']) # 西游记
# 8、values_list(*field): 返回的同样是QuerySet
objs = Book.objects.filter(id__gte=3)
print(objs.values_list("title"))
print(objs.values_list("title")[0][0]) # 红龙梦
print(objs.values_list("title").last()[0]) # 西游记
# 9、distinct(): 返回的同样是QuerySet
Book.objects.all().distinct() # 该行代码无意义,因为每一条结果多不是重复的
正确用法如下
objs = Book.objects.all().values("price").distinct()
print(objs)基于双下划线的模糊查询
Book.objects.filter(price__in=[100,200,300])
Book.objects.filter(price__gt=100)
Book.objects.filter(price__lt=100)
Book.objects.filter(price__gte=100)
Book.objects.filter(price__lte=100)
# 等同于Book.objects.filter(id__gte=100,id__lte=200)
# 相当于where price between 100 and 200
Book.objects.filter(price__range=[100,200])
Book.objects.filter(title__contains="python")
Book.objects.filter(title__icontains="python") # 忽略大小写
Book.objects.filter(title__startswith="py")
Book.objects.filter(title__iendswith="py")
Book.objects.filter(pub_date__lte="2021-02-23 17:51:00")
Book.objects.filter(pub_date__minute="38")3、单表delete
删除delete:调用者只能是QuerySet或者单个一个记录对象
*# 批量删除
objs = Book.objects.filter(id__in=[1,3,5])
objs.delete()
# 删除单一记录
objs = Book.objects.filter(id=6)
obj=objs[0]
obj.delete()
*objs.last().delete()
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to=’Publisher’, on_delete=models.SET_NULL, blank=True, null=True)
4、单表update
修改update:调用者只能是QuerySet,返回值为int
objs = Book.objects.filter(id=7)
rows=objs.update(title="xxx")
print(rows)
Book.objects.filter(name='跟Egon学算命').first().update(name='大家多能成神仙') # 报错update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
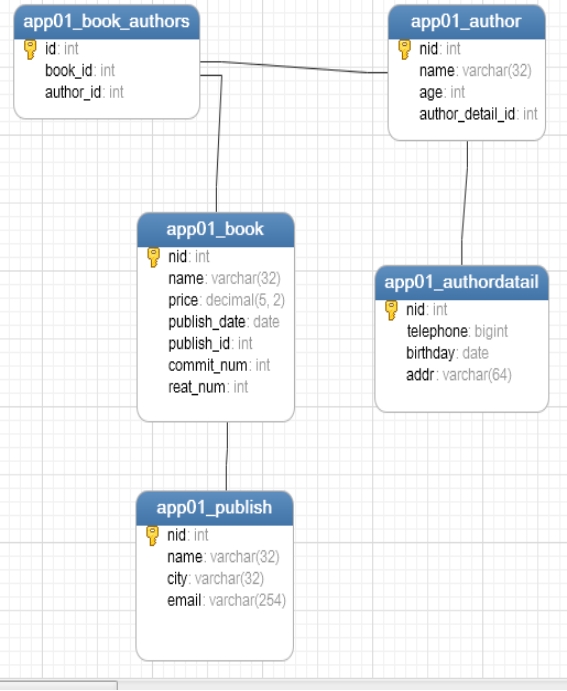
二、多表
准备多对多、一对多、一对一关系如下
from django.db import models
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 阅读数
# read_num=models.IntegerField(default=0)
# 评论数
# comment_num=models.IntegerField(default=0)
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.name
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDatail',to_field='nid',unique=True,on_delete=models.CASCADE)
class AuthorDatail(models.Model):
nid = models.AutoField(primary_key=True)
telephone = models.BigIntegerField()
birthday = models.DateField()
addr = models.CharField(max_length=64)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()生成的表如下:
1、添加记录
多对一关系添加:app01_book与app01_publish
from app01.models import *
# 先创建出版社
publish_obj = Publish.objects.create(name="666出版社", city="上海")
# 再创建书籍与出版社关联,具体有两种方式
# 方式一
Book.objects.create(name="跟egon学算命", price=3, publish=publish_obj)
# 方式二
book_obj = Book(name="跟egon学风水", price=5)
book_obj.publish_id = publish_obj.nid
book_obj.save()
# 思考:
book_obj.publish与book_obj.publish_id是什么?清理掉多对一的关系
# 可以只删掉一个书籍对象
Book.objects.filter(name="跟egon学算命").delete()
# 因为级联删除的存在,所以删出一个版社对象,对应的书籍对象会一并清除
Publish.objects.filter(name="666出版社").delete()一对一关系添加(与多对一一样):app01_autor与app01_authordatail
# 先创建作者详情
obj = AuthorDatail.objects.create(telephone=1861131111,birthday="2011-11-11",addr="水帘洞")
# 再创建作者信息
Author.objects.create(name='Egon',age=18,author_detail=obj)清理掉一对一关系(同多对一一样)
# 建议删作者时直接删除作者详情,这样便级联删除了作者
AuthorDatail.objects.filter(nid=1).delete()
# 如果只删作者,作者详情当然还是会存在的
Author.objects.filter(nid=1).delete()多对多关系添加:app01_autor,app01_book_autors,app01_book
=====下述记录如果已经存在了就不用创建了,直接过滤出来用就可以了,如果删掉了,那就重新建一遍
# 1、添加作者及其详情
obj = AuthorDatail.objects.create(telephone=1861131111,birthday="2011-11-11",addr="水帘洞")
Author.objects.create(name='Egon',age=18,author_detail=obj)
obj = AuthorDatail.objects.create(telephone=1361131111,birthday="2022-12-12",addr="盘丝洞")
Author.objects.create(name='Tom',age=18,author_detail=obj)
obj = AuthorDatail.objects.create(telephone=1761131111,birthday="2013-10-10",addr="金光洞")
Author.objects.create(name='Jack',age=18,author_detail=obj)
# 2、添加书籍
publish_obj = Publish.objects.create(name="666出版社", city="上海")
Book.objects.create(name="跟egon学算命", price=3, publish=publish_obj)
Book.objects.create(name="跟egon学风水", price=3, publish_id=publish_obj.nid)
===添加作者与书的多对多关系
# 过滤出书籍对象
book_obj1 = Book.objects.filter(name="跟egon学算命").first()
book_obj2 = Book.objects.filter(name="跟egon学风水").first()
# 过滤出作者对象
egon = Author.objects.filter(name="egon").first()
tom = Author.objects.filter(name="Tom").first()
jack = Author.objects.filter(name="Jack").first()
# 添加关系
book_obj1.authors.add(egon,tom,jack)
book_obj2.authors.add(egon,jack)
ps: 也可以直接传id
book_obj1.authors.add(1,2,3) # 或者用形式*[1,2,3]
查看app01_book_authors记录如下
+----+---------+-----------+
| id | book_id | author_id |
+----+---------+-----------+
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 1 | 3 |
| 4 | 2 | 1 |
| 5 | 2 | 3 |
+----+---------+-----------+清理掉多对多关系
# remove:下面三种方式都可以
book_obj1.authors.remove(egon,tom)
book_obj1.authors.remove(1,2)
book_obj1.authors.remove(*[1,2])
查看app01_book_authors记录如下
+----+---------+-----------+
| id | book_id | author_id |
+----+---------+-----------+
| 3 | 1 | 3 |
| 4 | 2 | 1 |
| 5 | 2 | 3 |
+----+---------+-----------+
# clear(): 清空被关联对象集合
book_obj2.authors.clear()
查看app01_book_authors记录如下
+----+---------+-----------+
| id | book_id | author_id |
+----+---------+-----------+
| 3 | 1 | 3 |
+----+---------+-----------+
# set(): 先清空再设置,只能传入一个序列,里面包含要添加的作者对象或者作者对象的id都可以
book_obj1.authors.set([egon,2])2、查询记录
1.多表查询的法则提炼如下
• 第一步:先搞清楚是正向查询还是反向查询
关联字段所在的表可以称之为源表,被关联的表称之为目标表,如此,正向反向一目了然了
• 第二步
*# 基于对象的查询相当于子查询(其实本质是分步查询)
* 正查用关联字段
* 反查用模型名,但如果反查的结果有多个值则要加_set
# 基于双下划线的查询相当于join链表
* 正查用关联字段
\ 反查用模型名
2.基于对象的子查询
多对一查询:app01_book与app01_publish
# 正向案例:查询”跟egon学算命“是哪个出版社出版的
book_obj=Book.objects.filter(name="跟egon学算命").first()
print(book_obj.publish.name) # 正向查询直接用关联字段,即publish即可
# 反向案例:查询”666出版社“出版的所有书籍
publish_obj = Publish.objects.filter(name="666出版社").first()
print(publish_obj.book_set.all()) # 反向查询用模型名,结果有多个,所有还有加_set,返回QuerySet一对一查询:app01_autor与app01_authordatail
# 正向案例:查询”Egon“的手机号
egon=Author.objects.filter(name="Egon").first()
print(egon.author_detail.telephone) # 正向查询直接用关联字段,即author_detail即可
# 反向案例:查询”nid=1的详情信息对应的作者名字“
obj = AuthorDatail.objects.filter(nid=1).first()
print(obj.author.name) # 反向查询用模型名,结果只有一个,所有author后无需加_set多对多查询:app01_autor,app01_book_autors,app01_book
# 正向案例:查询”跟egon学算命“的所有作者
egon = Book.objects.filter(name="跟egon学算命").first()
print(egon.authors.all()) # 正向查询直接用字段authors即可,而authors有多个,所以需要加all()
# 反向案例:查询”Egon“都出了哪些书
egon = Author.objects.filter(name="Egon").first()
print(egon.book_set.all()) # 反向查询用模型名,结果有多个,所有还有加_set,返回QuerySet3.基于双下划线的链表查询
多对一查询:app01_book与app01_publish
# 1、查询”跟egon学算命“是哪个出版社出版的
===>正查
res = Book.objects.filter(name="跟egon学算命").values_list("publish__name")
print(res) # <QuerySet [('666出版社',)]>
===>反查
res = Publish.objects.filter(book__name="跟egon学算命").values_list("name","city")
print(res) # <QuerySet [('666出版社', '上海')]>
# 2、查询”666出版社“出版的所有书籍
===>正查
res = Publish.objects.filter(name="666出版社").values_list("book__name")
print(res) # <QuerySet [('跟egon学算命',), ('跟egon学风水',)]>
===>反查
res = Book.objects.filter(publish__name="666出版社").values_list("name")
print(res) # <QuerySet [('跟egon学算命',), ('跟egon学风水',)]>一对一查询:app01_autor与app01_authordatail
# 1、查询”Egon“的手机号
===>正查
res = Author.objects.filter(name="Egon").values_list("author_detail__telephone")
print(res) # <QuerySet [(1861131111,)]>
===>反查
res = AuthorDatail.objects.filter(author__name="egon").values("telephone")
print(res) # 名字的大小写不重要,因为mysql中的查询默认也忽略大小写
# 2、查询”nid=1的详情信息对应的作者名字“
===>正查
res = Author.objects.filter(author_detail__nid=1).values_list("name")
print(res) # <QuerySet [('EGON',)]>
===>反查
res = AuthorDatail.objects.filter(nid=1).values_list("author__name")
print(res) # <QuerySet [('EGON',)]>多对多查询:app01_autor,app01_book_autors,app01_book
# 正向案例:查询”跟egon学算命“的所有作者
===>正查
res = Book.objects.filter(name="跟egon学算命").values_list("authors__name")
print(res) # <QuerySet [('EGON',), ('Tom',), ('Jack',)]>
===>反查
res = Author.objects.filter(book__name="跟egon学算命").values_list("name")
print(res) # <QuerySet [('EGON',), ('Tom',), ('Jack',)]>
# 查询”Egon“都出了哪些书
===>正查
res = Author.objects.filter(name="egon").values_list("book__name")
print(res) # <QuerySet [('跟egon学算命',), ('跟egon学风水',)]>
===>反查
res = Book.objects.filter(authors__name="egon").values_list("name")
print(res) # <QuerySet [('跟egon学算命',), ('跟egon学风水',)]>如果有必要,你可以一直连续跨表
# 1、查询“666出版社”出版过的所有书籍及期作者名字
===>正查
res = Book.objects.filter(publish__name="666出版社").values_list("name","authors__name")
print(res)
<QuerySet [('跟egon学算命', 'EGON'), ('跟egon学算命', 'Tom'), ('跟egon学算命', 'Jack'), ('跟egon学风水', 'EGON'), ('跟egon学风水', 'Jack')]>
===>反查
res = Publish.objects.filter(name="666出版社").values_list("book__name","book__authors__name")
print(res)
# 2、2011年出生的作者出版过的所有书籍名称以及出版社名称
===>正查
res=Book.objects.filter(authors__author_detail__birthday__year=2011).values_list("name","publish__name")
print(res)
<QuerySet [('跟egon学算命', '666出版社'), ('跟egon学风水', '666出版社')]>
===>反查
res=AuthorDatail.objects.filter(birthday__year="2011").values_list("author__book__name","author__book__publish__name")
print(res)三、查询相关参数补充
1、多对对参数:symmetrical
仅用于多对多自关联时,指定内部是否创建反向操作的字段。默认为True。
举个例子:
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self")
此时,person对象就没有person_set属性。
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self", symmetrical=False)
此时,person对象现在就可以使用person_set属性进行反向查询。2、foreign key参数:related_name与related_query_name
related_name = "xxx"
反向:小写模型名_set 换成 xxx
related_query_name = "xxx"
反向:小写模型名_set 换成 xxx_set
例如:
class Classes(models.Model):
name = models.CharField(max_length=32)
class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().student_set.all()
当我们在ForeignKey字段中添加了参数 related_name 后,
class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes", related_name="students")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().students.all()四、*聚合与分组查询*
1、annotate
分组查询annotate等同于mysql的group by,但是annotate的分组要分两种情况讨论
1、默认以表的主键字段分组
管理器objects左边的那个模型是谁就以谁的主键字段作为分组依据,例如Book.objects.annotate(),则按照Book的主键字段分组
举例
# 1、每本书的作者个数
res=Book.objects.annotate(authors_num=Count('authors')).values("name","authors_num")
print(res)
原生sql分析:
会先链接表app01_book和app01_authors,然后再按照app01_book表的主键字段分组,此处app01_book表的主键字段为nid
# 2、每个出版社卖的最便宜的那本书的价格
res=Publish.objects.annotate(x=Min("book__price")).values("x")
print(res) # <QuerySet [{'x': Decimal('2.00')}]>
原生sql分析:同上
# 3、统计不止一个作者的图书
res = Book.objects.annotate(n=Count("authors")).filter(n__gt=1).values_list("name", "n")
print(res)
# 4、查询每个作者的书的总价格
res=Author.objects.annotate(s=Sum("book__price")).values('s')
print(res)
原生sql分析:
会先链接表app01_author、app01_book_authors、app01_book
然后再按照app01_author表的主键字段分组,此处为app01_author.nid2、如果想按照指定的字段分组,则需要引入values()
annotate()前面的出现了values(),就会以values()中指定的字段分组
如果没有,就会默认按照模型的主键字段分组,例如
Book.objects.values("price").annotate() # 按照Book模型的price字段分组
# 1、统计每年出版的书个数
res=Book.objects.values("publish_date__year").annotate(n=Count("nid")).values("publish_date__year","n")
print(res)
# 输出结果
<QuerySet [{'publish_date__year': 2021, 'n': 2}, {'publish_date__year': 2022, 'n': 1}]>如果我们想统计哪一年哪一月出版的书个数,需要用到date_format函数,此时就需要调用extra来执行date_format了,如下,注意%要连续写两个,第一个代表取消第二%的特殊意义
res=Book.objects.extra(select={"y_m":"date_format(publish_date,'%%Y-%%m')"}).values("y_m").annotate(n=Count("nid")).values("y_m","n")
print(res)
# 输出结果
<QuerySet [{'y_m': '2021-02', 'n': 2}, {'y_m': '2022-02', 'n': 1}]>ps:
在严格模式下(ONLY_FULL_GROUP_BY)分组之后默认只能获取分组依据,若查询了非分组字段,会导致错误,需要修改数据库模式:
#设置sql_mole如下操作(我们可以去掉ONLY_FULL_GROUP_BY模式):
mysql> set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';五、F查询与Q查询
1、 aggregate
若想把整张表当成一个组来使用聚合函数,应该调用aggregate
# 1、先导入聚合函数
from django.db.models import Max, Min, Avg, Sum, Count
"""
小窍门:
只要是跟数据库相关的模块基本都在django.db.models里面
如果没有那么应该在django.db里
"""
# 2、查询所有作者的最大nid、最小年龄、平均年龄、年龄之和、作者个数
res = Author.objects.aggregate(
Max("age"),
Min("age"),
Avg("age"),
Sum("age"),
Count("nid")
)
print(res) # 调用的sql为:select avg("age"),max("nid"),... from app01_author;
{'age__max': 30, 'age__min': 10, 'age__avg': 20.0, 'age__sum': 60, 'nid__count': 3}
# 3、也可以指定key值
res = Author.objects.aggregate(
x=Max("age"),
y=Min("age"),
)
print(res)
{'x': 30, 'y': 10}2、F查询
F查询够帮你直接获取到表中的某个字段对应的值,具体应用如下
# 修改模型Book增加阅读数与评论数字段,然后重新迁移数据库,新增好记录
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 阅读数
read_num=models.IntegerField(default=0)
# 评论数
comment_num=models.IntegerField(default=0)
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.name
from django.db.models import F
# 1、查询阅评论数大于阅读数的书籍名
res = Book.objects.filter(comment_num__gt=F("read_num"))
print(res)
# 2、将所有书的价格在原来的基础上增加50元
Book.objects.update(price=F("price")+50)注意,针对数字运算,F可以直接与数字进行数学运算,但如果我们想拼接字符串,则需要引入Concat并配合Value一起实现,如下
# 3、将所有书籍的名称后面加爆款两个字
from django.db.models.functions import Concat
from django.db.models import Value, F
Book.objects.update(name=Concat(F('name'), Value("爆款")))
# Book.objects.update(name=F('name') + "爆款") # 错误,所有书的名字都会被改为03、Q查询
对于filter()方法内逗号分隔开的多个条件,都是and关系,如果想用or或者not关系,则需要使用Q
from django.db.models import Q
Book.objects.filter(Q(nid__gte=3), Q(nid__lte=5)) # 还是and关系
Book.objects.filter(Q(nid__lte=3) | Q(nid__gte=5)) # or关系
Book.objects.filter(~Q(nid__gt=2)) # ~ 等同于在条件前加了not 代表: ! nid>2即nid<=2
Book.objects.filter(~Q(nid__gt=2) | Q(nid__gte=5)) # 代表nid<=2 or nid>=5Q查询的高阶用法:能够以字符串作为查询字段
q = Q()
q.children.append(('nid__gt', 2)) # 条件中引用的字段为字符串类型
q.children.append(('price__lt', 50))
res = Book.objects.filter(q) # filter内可以直接放q对象,默认还是and关系
print(res)
q = Q()
q.connector = 'or'
q.children.append(('nid__lte', 2))
q.children.append(('nid__gte', 5))
res = Book.objects.filter(q) # 此时是or关系
print(res)
# 那什么场景下,我们查询条件中的字段是字符串类型呢?
# 比如我们制作一个搜索功能,我们需要根据用户输入搜索字段完成查询,而用户输入的都是字符串类型,此时就用到了Q的高阶用法