一 形参与实参介绍

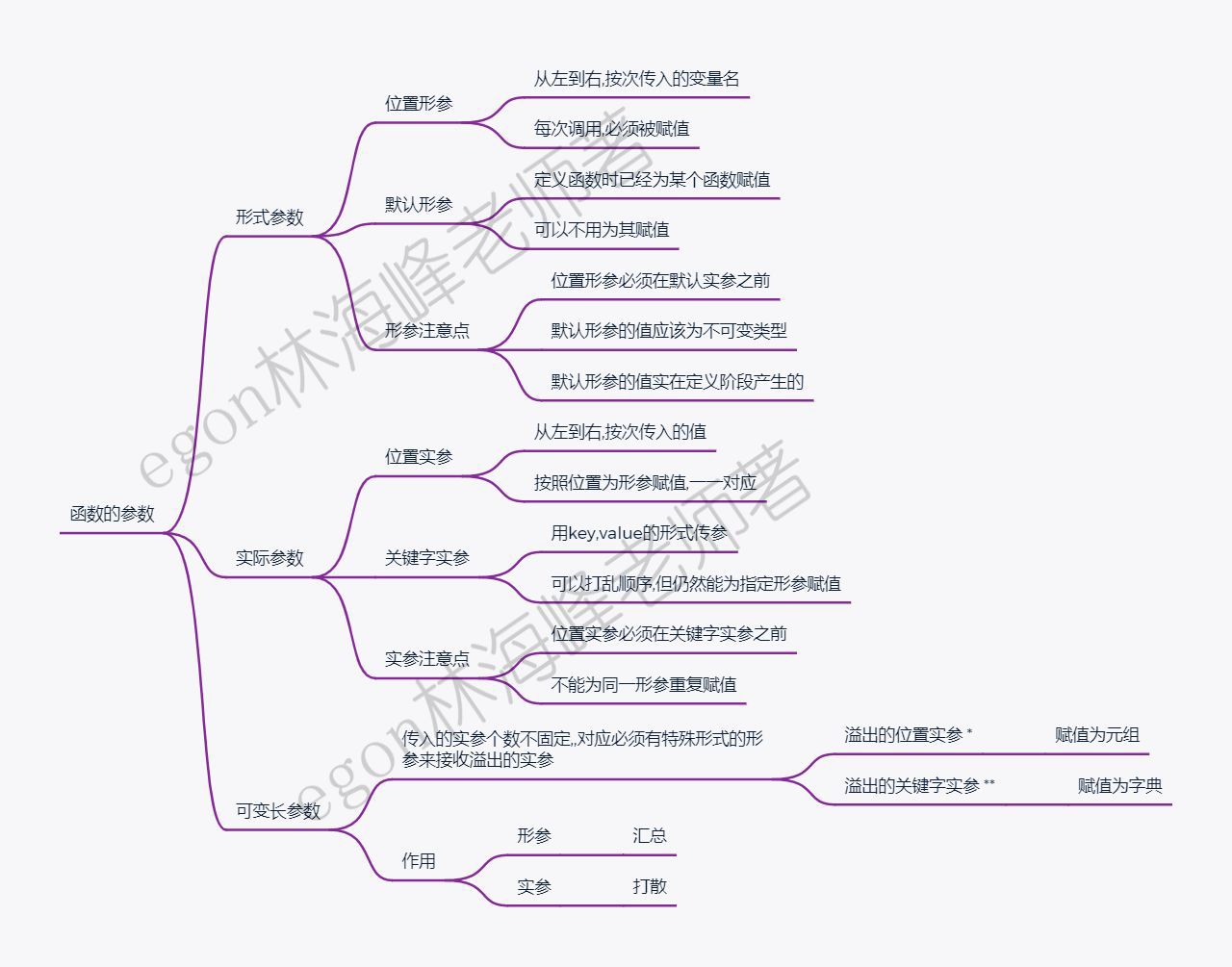
函数的参数分为形式参数和实际参数,简称形参和实参:
形参即在定义函数时,括号内声明的参数。形参本质就是一个变量名,用来接收外部传来的值。
实参即在调用函数时,括号内传入的值,值可以是常量、变量、表达式或三者的组合:
#1:实参是常量
res=my_min(1,2)
#2:实参是变量
a=1
b=2
res=my_min(a,b)
#3:实参是表达式
res=my_min(10*2,10*my_min(3,4))
#4:实参可以是常量、变量、表达式的任意组合
a=2
my_min(1,a,10*my_min(3,4))在调用有参函数时,实参(值)会赋值给形参(变量名)。在Python中,变量名与值只是单纯的绑定关系,而对于函数来说,这种绑定关系只在函数调用时生效,在调用结束后解除。

二 形参与实参的具体使用
2.1 位置参数
位置即顺序,位置参数指的是按顺序定义的参数,需要从两个角度去看:
-
在定义函数时,按照从左到右的顺序依次定义形参,称为位置形参,凡是按照这种形式定义的形参都必须被传值
>>> def register(name,age,sex): #定义位置形参:name,age,sex,三者都必须被传值 ... print('Name:%s Age:%s Sex:%s' %(name,age,sex)) ... >>> register() #TypeError:缺少3个位置参数 -
在调用函数时,按照从左到右的顺序依次定义实参,称为位置实参,凡是按照这种形式定义的实参会按照从左到右的顺序与形参一一对应
>>> register('lili',18,'male') #对应关系为:name=’lili’,age=18,sex=’male’ Name:lili Age:18 Sex:male

2.2 关键字参数
在调用函数时,实参可以是key=value的形式,称为关键字参数,凡是按照这种形式定义的实参,可以完全不按照从左到右的顺序定义,但仍能为指定的形参赋值
>>> register(sex='male',name='lili',age=18)
Name:lili Age:18 Sex:male需要注意在调用函数时,实参也可以是按位置或按关键字的混合使用,但必须保证关键字参数在位置参数后面,且不可以对一个形参重复赋值
>>> register('lili',sex='male',age=18) #正确使用
>>> register(name='lili',18,sex='male') #SyntaxError:关键字参数name=‘lili’在位置参数18之前
>>> register('lili',sex='male',age=18,name='jack') #TypeError:形参name被重复赋值
2.3 默认参数
在定义函数时,就已经为形参赋值,这类形参称之为默认参数,当函数有多个参数时,需要将值经常改变的参数定义成位置参数,而将值改变较少的参数定义成默认参数。例如编写一个注册学生信息的函数,如果大多数学生的性别都为男,那完全可以将形参sex定义成默认参数
>>> def register(name,age,sex='male'): #默认sex的值为male
... print('Name:%s Age:%s Sex:%s' %(name,age,sex))
...定义时就已经为参数sex赋值,意味着调用时可以不对sex赋值,这降低了函数调用的复杂度
>>> register('tom',17) #大多数情况,无需为sex传值,默认为male
Name:tom Age:17 Sex:male
>>> register('Lili',18,'female') #少数情况,可以为sex传值female
Name:Lili Age:18 Sex:female
需要注意:
- 默认参数必须在位置参数之后
- 默认参数的值仅在函数定义阶段被赋值一次
>>> x=1
>>> def foo(arg=x):
... print(arg)
...
>>> x=5 #定义阶段arg已被赋值为1,此处的修改与默认参数arg无任何关系
>>> foo()
1-
默认参数的值通常应设为不可变类型
>>> def foo(n,arg=[]): ... arg.append(n) ... return arg ... >>> foo(1) [1] >>> foo(2) [1, 2] >>> foo(3) [1, 2, 3]每次调用是在上一次的基础上向同一列表增加值,修改如下
>>> def foo(n,arg=None): ... if arg is None: ... arg=[] ... arg.append(n) ... return arg ... >>> foo(1) [1] >>> foo(2) [2] >>> foo(3) [3]

2.4 可变长度的参数(*与**的用法)

参数的长度可变指的是在调用函数时,实参的个数可以不固定,而在调用函数时,实参的定义无非是按位置或者按关键字两种形式,这就要求形参提供两种解决方案来分别处理两种形式的可变长度的参数
2.4.1 可变长度的位置参数
如果在最后一个形参名前加号,那么在调用函数时,溢出的位置实参,都会被接收,以元组的形式保存下来赋值给该形参
>>> def foo(x,y,z=1,*args): #在最后一个形参名args前加*号
... print(x)
... print(y)
... print(z)
... print(args)
...
>>> foo(1,2,3,4,5,6,7) #实参1、2、3按位置为形参x、y、z赋值,多余的位置实参4、5、6、7都被*接收,以元组的形式保存下来,赋值给args,即args=(4, 5, 6,7)
1
2
3
(4, 5, 6, 7)如果我们事先生成了一个列表,仍然是可以传值给*args的
>>> def foo(x,y,*args):
... print(x)
... print(y)
... print(args)
...
>>> L=[3,4,5]
>>> foo(1,2,*L) # *L就相当于位置参数3,4,5, foo(1,2,*L)就等同于foo(1,2,3,4,5)
1
2
(3, 4, 5)
注意:如果在传入L时没有加*,那L就只是一个普通的位置参数了
>>> foo(1,2,L) #仅多出一个位置实参L
1
2
([1, 2, 3],)如果形参为常规的参数(位置或默认),实参仍可以是*的形式
>>> def foo(x,y,z=3):
... print(x)
... print(y)
... print(z)
...
>>> foo(*[1,2]) #等同于foo(1,2)
1
2
3如果我们想要求多个值的和,*args就派上用场了
>>> def add(*args):
... res=0
... for i in args:
... res+=i
... return res
...
>>> add(1,2,3,4,5)
15
2.4.2 可变长度的关键字参数
如果在最后一个形参名前加号,那么在调用函数时,溢出的关键字参数,都会被接收,以字典的形式保存下来赋值给该形参
>>> def foo(x,**kwargs): #在最后一个参数kwargs前加**
... print(x)
... print(kwargs)
...
>>> foo(y=2,x=1,z=3) #溢出的关键字实参y=2,z=3都被**接收,以字典的形式保存下来,赋值给kwargs
1
{'z': 3, 'y': 2}如果我们事先生成了一个字典,仍然是可以传值给**kwargs的
>>> def foo(x,y,**kwargs):
... print(x)
... print(y)
... print(kwargs)
...
>>> dic={'a':1,'b':2}
>>> foo(1,2,**dic) #**dic就相当于关键字参数a=1,b=2,foo(1,2,**dic)等同foo(1,2,a=1,b=2)
1
2
{'a': 1, 'b': 2}
注意:如果在传入dic时没有加**,那dic就只是一个普通的位置参数了
>>> foo(1,2,dic) #TypeError:函数foo只需要2个位置参数,但是传了3个如果形参为常规参数(位置或默认),实参仍可以是**的形式
>>> def foo(x,y,z=3):
... print(x)
... print(y)
... print(z)
...
>>> foo(**{'x':1,'y':2}) #等同于foo(y=2,x=1)
1
2
3如果我们要编写一个用户认证的函数,起初可能只基于用户名密码的验证就可以了,可以使用**kwargs为日后的扩展供良好的环境,同时保持了函数的简洁性。
>>> def auth(user,password,**kwargs):
... pass
...2.5 命名关键字参数
在定义了**kwargs参数后,函数调用者就可以传入任意的关键字参数key=value,如果函数体代码的执行需要依赖某个key,必须在函数内进行判断
>>> def register(name,age,**kwargs):
... if 'sex' in kwargs:
... #有sex参数
... pass
... if 'height' in kwargs:
... #有height参数
... pass
... 想要限定函数的调用者必须以key=value的形式传值,Python3提供了专门的语法:需要在定义形参时,用作为一个分隔符号,号之后的形参称为命名关键字参数。对于这类参数,在函数调用时,必须按照key=value的形式为其传值,且必须被传值
>>> def register(name,age,*,sex,height): #sex,height为命名关键字参数
... pass
...
>>> register('lili',18,sex='male',height='1.8m') #正确使用
>>> register('lili',18,'male','1.8m') # TypeError:未使用关键字的形式为sex和height传值
>>> register('lili',18,height='1.8m') # TypeError没有为命名关键字参数height传值。
命名关键字参数也可以有默认值,从而简化调用
>>> def register(name,age,*,sex='male',height):
... print('Name:%s,Age:%s,Sex:%s,Height:%s' %(name,age,sex,height))
...
>>> register('lili',18,height='1.8m')
Name:lili,Age:18,Sex:male,Height:1.8m需要强调的是:sex不是默认参数,height也不是位置参数,因为二者均在后,所以都是命名关键字参数,形参sex=’male’属于命名关键字参数的默认值,因而即便是放到形参height之前也不会有问题。另外,如果形参中已经有一个args了,命名关键字参数就不再需要一个单独的*作为分隔符号了
>>> def register(name,age,*args,sex='male',height):
... print('Name:%s,Age:%s,Args:%s,Sex:%s,Height:%s' %(name,age,args,sex,height))
...
>>> register('lili',18,1,2,3,height='1.8m') #sex与height仍为命名关键字参数
Name:lili,Age:18,Args:(1, 2, 3),Sex:male,Height:1.8m

2.6 组合使用
综上所述所有参数可任意组合使用,但定义顺序必须是:位置参数、默认参数、*args、命名关键字参数、**kwargs
可变参数*args与关键字参数*kwargs通常是组合在一起使用的,如果一个函数的形参为args与**kwargs,那么代表该函数可以接收任何形式、任意长度的参数
>>> def wrapper(*args,**kwargs):
... pass
...
在该函数内部还可以把接收到的参数传给另外一个函数(这在4.6小节装饰器的实现中大有用处)
>>> def func(x,y,z):
... print(x,y,z)
...
>>> def wrapper(*args,**kwargs):
... func(*args,**kwargs)
...
>>> wrapper(1,z=3,y=2)
1 2 3按照上述写法,在为函数wrapper传参时,其实遵循的是函数func的参数规则,调用函数wrapper的过程分析如下:
- 位置实参1被*接收,以元组的形式保存下来,赋值给args,即args=(1,),关键字实参z=3,y=2被**接收,以字典的形式保存下来,赋值给kwargs,即kwargs={‘y’: 2, ‘z’: 3}
- 执行func(args,kwargs),即func(*(1,),** {‘y’: 2, ‘z’: 3}),等同于func(1,z=3,y=2)
提示: *args、**kwargs中的args和kwargs被替换成其他名字并无语法错误,但使用args、kwargs是约定俗成的。
三 练习题
练习1
写函数,,用户传入修改的文件名,与要修改的内容,执行函数,完成批了修改操作
def modify_file(filename,old,new):
import os
with open(filename,'r',encoding='utf-8') as read_f,\
open('.bak.swap','w',encoding='utf-8') as write_f:
for line in read_f:
if old in line:
line=line.replace(old,new)
write_f.write(line)
os.remove(filename)
os.rename('.bak.swap',filename)
modify_file('/Users/egon/PycharmProjects/python/a.txt','egon','egon_new')
练习2
写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
def check_str(msg):
res={
'num':0,
'string':0,
'space':0,
'other':0,
}
for s in msg:
if s.isdigit():
res['num']+=1
elif s.isalpha():
res['string']+=1
elif s.isspace():
res['space']+=1
else:
res['other']+=1
return res
res=check_str('WELCOME to egon's world 1234321')
print(res)
练习3
写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。
练习4
写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
def func1(seq):
if len(seq) > 2:
seq=seq[0:2]
return seq
print(func1([1,2,3,4]))
练习5
写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
def func2(seq):
return seq[::2]
print(func2([1,2,3,4,5,6,7]))
练习6
写函数,检查字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
dic = {"k1": "v1v1", "k2": [11,22,33,44]}
PS:字典中的value只能是字符串或列表
def func3(dic):
d={}
for k,v in dic.items():
if len(v) > 2:
d[k]=v[0:2]
return d
print(func3({'k1':'abcdef','k2':[1,2,3,4],'k3':('a','b','c')}))