一 引入问题
1、思考一个问题
有一个容器,里面运行的进程需要写一个10G的文件,具体是如何写的呢?
从源文件中每次只读取一个100KB大小的数块,然后写入一个新文件,不断地写,直到写完10G大小的数据。
2、问:你如果为该容器分配资源?
很多人都会觉得,只需要保证磁盘空间够用就可以了,不需要考虑内存,这其实是有问题的,此时如果内存很小比如只有1G,你会发现容器的整体读写效率有波动,有时候速度还可以,有时候就很慢
3、为什么???
二 储备知识
2.1 VFS介绍
FS在整个Linux系统中的架构视图如下,了解了这个架构之后我们就能知道用户写入文件的核心流程
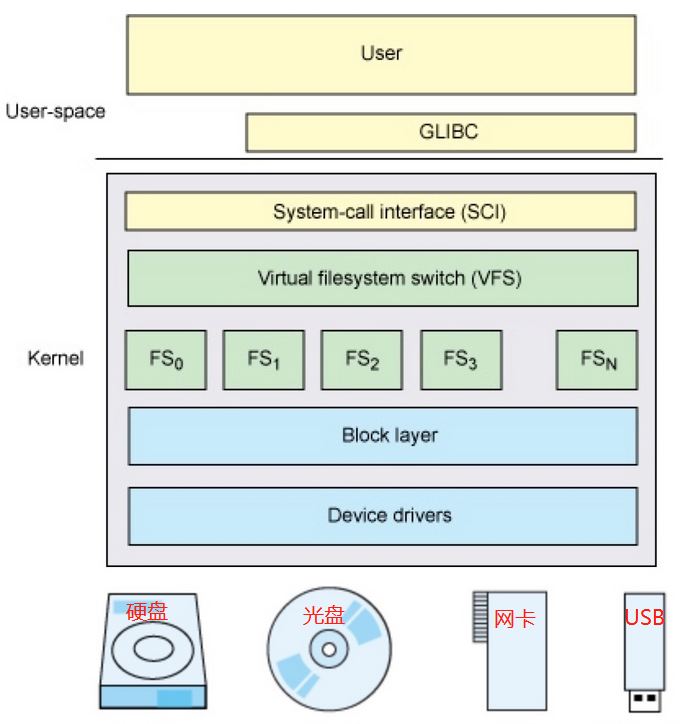
1、先来了解一下VFS虚拟文件系统
-
VFS 是什么
VFS(Virtual Filesystem Switch)称为虚拟文件系统或虚拟文件系统转换,是一个内核软件层,是在具体的文件系统filesystem之上抽象的一层,用来处理与Posix文件系统相关的所有调用,表现为能够给各种文件系统提供一个通用的接口,使上层的应用程序能够使用通用的接口访问不同文件系统filesystem,同时也为不同文件系统的通信提供了媒介。 -
VFS 的作用
概括地讲,VFS 有两个作用:处理与 Unix 标准文件系统相关的所有系统调用
为各种文件系统提供一个通用的接口
-
VFS 的设计思想
VFS 设计的初衷就是要支持所有的文件系统,所以它的设计思想其实就是以面向对象的方式,设计一个通用的文件模型,出于效率考虑,VFS 还是 C 语言写的。
在通用文件系统模型中,每个目录也被当作一个文件,可以包含若干文件和其他的子目录。因此,Linux 有一句经典的话:一切皆文件。
2、然后再来看一下用户写入文件的大概流程
用户写入一个文件,使用POSIX标准的write接口,会被操作系统接管,转调sys_write这个系统调用(属于SCI层)。然后VFS层接受到这个调用,通过自身抽象的模型,转换为对给定文件系统filesystem、给定设备的操作,这一关键性的步骤是VFS的核心,需要有统一的模型,使得对任意支持的文件系统都能实现系统的功能。这就是VFS提供的统一的文件模型(common file model),底层具体的文件系统负责具体实现这种文件模型,负责完成POSIX API的功能,并最终实现对物理存储设备的操作。

VFS这一层建模和抽象是有必要的,如果放在SCI层会导致操作系统的系统调用的功能过于复杂,易出bug。那么就只能让底层文件系统都遵循统一实现,这对于已经出现的各种存储设备来说天然就有不同的特性,也是无法实现的。因此VFS这样一层抽象是有其必要性的。
2.2 Bufferd IO与Direct IO
通常来说,文件I/O可以分为两种:
Buffer I/O:先写buffer后由内核异步把脏数据刷入磁盘
Direct I/O:直接写入
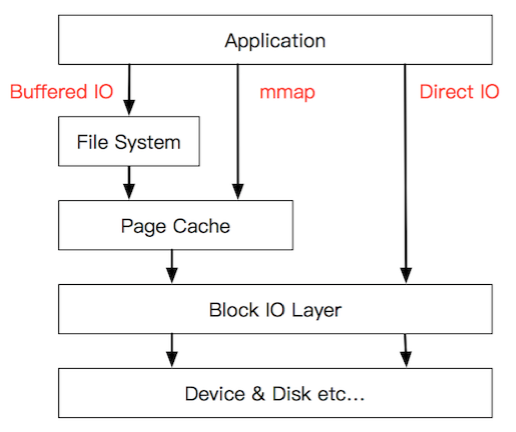
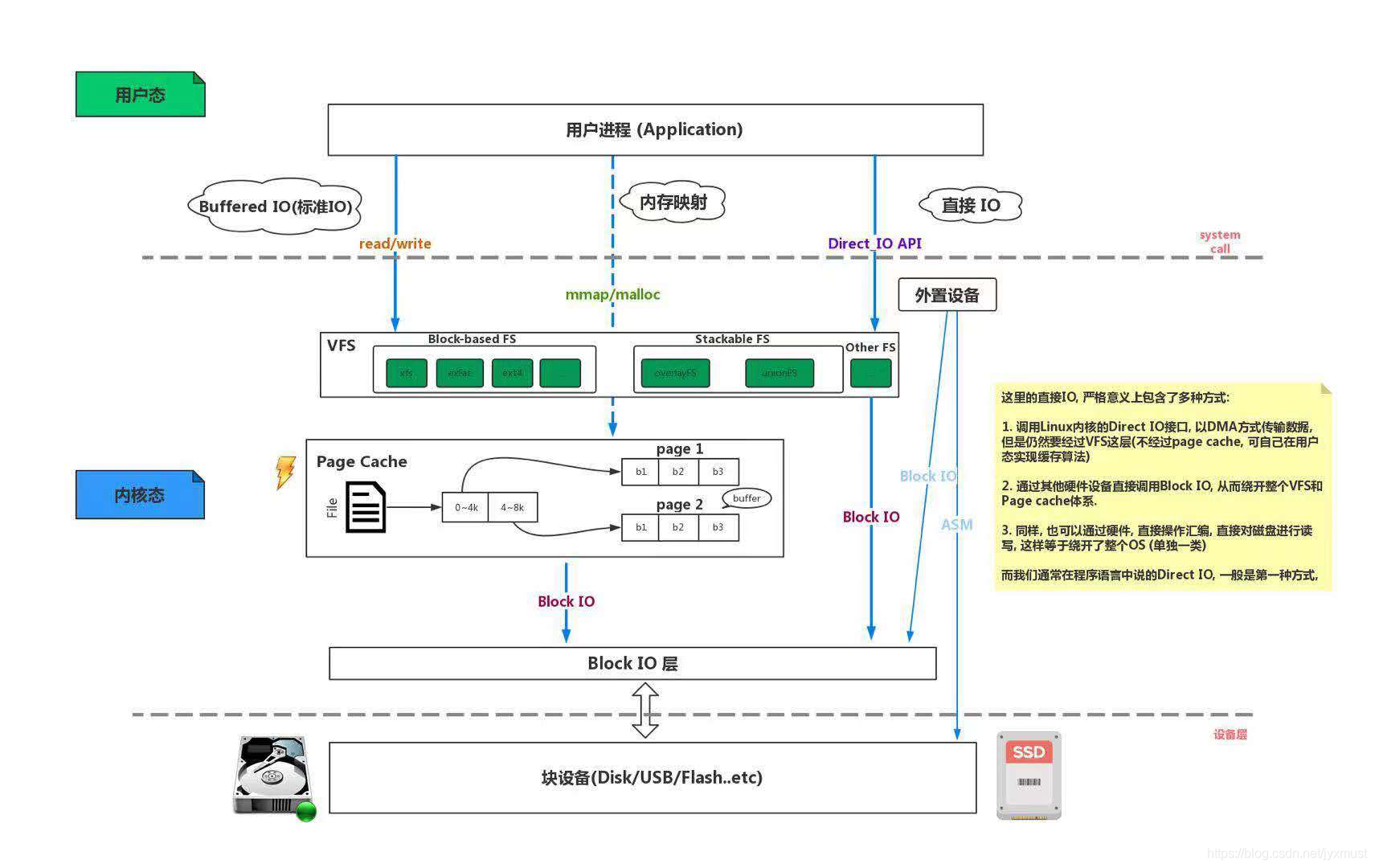
Buffer I/O详解
Buffer I/O又称缓存I/O、标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。
在 Linux 的缓存 I/O 机制中,这种访问文件的方式是通过两个系统调用实现的:read() 和 write()。
(1) 调用read()时:
如果 操作系统内核地址空间的页缓存( page cache )有数据就读取出该数据并直接返回给应用程序;
如果没有就从磁盘读取数据到页缓存。然后再从页缓存拷贝到应用程序的地址空间。
(2) 调用write()时:
数据会先从应用程序的地址空间拷贝到 操作系统内核地址空间的页缓存,然后再写入磁盘。
根据Linux的延迟写机制,当数据写到操作系统内核地址空间的页缓存就意味write()完成了,操作系统会定期地将页缓存的数据刷到磁盘上。所以缓存 I/O 有以下这些优点:
缓存 I/O 使用了操作系统内核的页缓存,保护了磁盘
缓存 I/O 减少读盘的次数,提高了读取速度总的来说,Buffer I/O为了提高读写效率和保护磁盘而使用了页缓存机制。
不过由于页缓存处于内核空间,不能被应用程序(用户进程)直接寻址,所以还需要将页缓存数据再拷贝到内存对应的用户空间中。这样,需要两次数据拷贝才能完成用户进程对数据的读取操作。写操作也是一样,将页缓存的数据写入磁盘的时候,必须先拷贝到内核空间对应的主存,然后在写入磁盘中。因此,Buffer I/O 中引入一类特别的操作叫做内存映射文件(mmap),它的不同点在于,中间会减少一层数据从用户地址空间到操作系统地址空间的复制开销 。使用mmap函数的时候,会在当前进程的用户地址空间中开辟一块内存,这块内存与系统的文件进行映射。对其的读取和写入,会转化为对相应文件的操作。 并且,在进程退出的时候,会将变化的内容(脏页)自动回写到对应的文件里面。
Direct I/O详解
凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,中间少了页缓存page Cache的支持。
虽然说操作系统层提供的page Cache缓存往往会使应用程序在读写数据的时候获得更好的性能,但是对于某些特殊的应用程序,比如说数据库管理系统这类应用,他们更倾向于选择他们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。例如:Java 中目前是没有直接支持 Direct I/O的,只支持Buffer I/O。我们可以通过JNA 来实现其支持,linux通过将O_DIRECT标志传递给 open()系统调用来实现对Direct I/O 的支持,不过直接操作磁盘,所有写入内存块数量必须是文件系统块大小的倍数,而且要与内存页大小对齐。这些对齐规则参数操作我们可以使用JNA来完成。 JNA 是 Java 中一种用来与本地共享库进行互操作的便捷方式,使用它可以直接调用操作系统本地库。
什么是脏数据?
针对bufferd I/O,写数据是先写入了page cache,还没来得及写入磁盘,这部分数据称之为脏数据,即dirty pages,脏数据脏数据何时会落盘???
在linux内核中会有专门的内核线程(每个磁盘设备对应的kworker/flush线程)会定期负责把脏数据落到磁盘中。因为bufferd IO的读写效率更高,所以大多数场景使用的都是该模式。
但该模式下,关于读和写需要考虑的内容还是有区别的
-
1、读缓存在绝大多数情况下是有益无害的(程序可以直接从
RAM中读取数据)。 -
2、写缓存比较复杂
-
(1)
Linux内核将磁盘写入缓存,过段时间再异步将它们刷新到磁盘。这对加速磁盘I/O有很好的效果,但是当数据未写入磁盘时,丢失数据的可能性会增加。 -
(2)也存在缓存被写爆的情况。
-
(3)还可能出现一次性往磁盘写入过多数据,以致使系统卡顿。这些卡顿是因为系统认为,缓存太大用异步的方式来不及把它们都写进磁盘,于是切换到同步的方式写入。
-
针对写缓存的这些诸多问题,如何解决呢?我们来看几个重要的内存参数
2.3 几个重要的内核参数
$ sysctl -a | grep dirty
vm.dirty_background_bytes = 0 # 配置路径:/proc/sys/vm/dirty_background_bytes
vm.dirty_background_ratio = 10 # 配置路径:/proc/sys/vm/dirty_background_ratio
vm.dirty_bytes = 0 # 配置路径:/proc/sys/vm/dirty_bytes
vm.dirty_ratio = 20 # 配置路径:/proc/sys/vm/dirty_ratio
vm.dirty_writeback_centisecs = 500 # 配置路径: /proc/sys/vm/dirty_writeback_centisecs
vm.dirty_expire_centisecs = 3000 # 配置路径: /proc/sys/vm/dirty_expire_centisecs
vm.dirtytime_expire_seconds = 43200 # 配置路径: /proc/sys/vm/dirtytime_expire_seconds
补充:
/proc/sys/vm/dirty_*, 在容器和宿主机上是一样的,这些值没有namespace.下面几个内核参数,原理大致相同,都是控制什么时候就刷一波dirty page,防止它一直增长把available内存吃满
vm.dirty_background_ratio是内存可以填充脏数据的百分比。这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。比如,该值设为10,那么我有32G内存,则允许有3.2G的脏数据待在内存里,超过3.2G的话就会有后台进程来清理。vm.dirty_ratio是可以用脏数据填充的绝对最大系统内存量,当内存脏数据量到达此点时,必须将所有脏数据提交到磁盘,同时所有新的bufferedI/O块都会被阻塞,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。- 参数一与二的另外一种写法:
vm.dirty_background_bytes和vm.dirty_bytes是另一种指定这些参数的方法。如果设置_bytes版本,则_ratio版本将变为0,反之亦然。 vm.dirty_writeback_centisecs指定默认多长时间pdflush/flush/kdmflush这些进程会唤醒一次,然后来检查是否有缓存需要清理。vm.dirty_expire_centisecs指定脏数据能存活的时间。在这里它的值是30秒。当pdflush/flush/kdmflush在运行的时候,他们会检查是否有数据超过这个时限,如果超过则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。- dirtytime_expire_seconds:默认值12 60 60,即12小时。一个inode在12小时内未存在任何更新,则很可能其时间戳在过去的12小时内存在过变更,比如lazy方式更新。因此系统默认以12小时为周期的强制查看inode是否存在时间戳变更,避免文件时间戳更新过于迟滞。
如何理解上述参数呢???
脏数据占用比例=等于 dirty pages 的内存 / 节点可用内存 *100%,下面简称A
ps:
可用内存可以理解为执行free命令输出的"available" 内存。我们可以把整个buffer空间当成一个水桶
/proc/sys/vm/dirty_background_ratio如果为50,代表水盛放到一个半,就立刻开闸放水,但是但是但是,需要注意的是
你在放水的时候,同时可能有水进入,而注水的速度是有可能超过放水的速度
所以有可能出现的一个现象就是,A值超过了dirty_background_ratio值,linux内核开始不停地放水,放水的目的是为了让A降下来,但是因为
注水速度大于放水速度,而出现,A不降反增
能让它增满吗???肯定不能,这就需要有另外一个参数来限制,如果注水的速度实在太离谱了,那你就别注,你原地停止,可别真别把内存吃满了
等放水放到安全线你再继续注水
这就是dirty_radio,控制最大水位,一旦达到这个最大水位,所有的buffer I/O写文件操作都会被阻塞住,直到它写的数据页都写入磁盘为止
比如dirty_background_ratio设为50,而dirty_radio设为60,A值超过了50则开始泄洪,但泄的同时可能也在注水,泄的没有注的快,以至于水位涨到了60,即达到了dirty_radio的值,那么就会禁止注水,阻塞住,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
有没有可能A永远没有超过dirty_background_ratio ,也没有超过dirty_ratio,那么脏数据就不往硬盘刷了吗,肯定不行,断电数据就没了啊,而且长期不刷是要闹哪样,写完了之后很长一段时间用户却发现磁盘没有这可不行
这就需要用到下面的内核参数,固定时间来刷新
这就需要用到参数dirty_writeback_centisecs:默认值为500,单位为1/100秒,所以默认代表5秒唤醒内核的flush线程来处理dirty pages
另外,为了防止一些脏数据在内存中停留时间过久,就需要用到内核参数dirty_expire_centisecs:与上面一样都是以百分之一秒为单位,所以默认为30s,指的是dirty page 在内存中存放的最长时间,如果一个 dirty page 超过这里定义的时间,那么内核的 flush 线程也会把这个页面写入磁盘