一、数字类型及操作
- 整数类型的无限范围及4种进制表示
- 浮点数类型的近似无限范围、小尾数及科学计数法
- +、-、*、/、//、%、**、二元增强赋值操作符
- abs()、divmod()、pow()、round()、max()、min()
- int()、float()、complex()
# DayDayUpQ3.py
dayup = 1.0
dayfactor = 0.01
for i in range(365):
if i % 7 in [6, 0]:
dayup = dayup * (1 - dayfactor)
else:
dayup = dayup * (1 + dayfactor)
print("工作日的力量:{:.2f} ".format(dayup)) # 工作日的力量:4.63
工作日的力量:4.63
def dayUP(df):
dayup = 1
for i in range(365):
if i % 7 in [6, 0]:
dayup = dayup * (1 - 0.01)
else:
dayup = dayup * (1 + df)
return dayup
dayfactor = 0.01
while dayUP(dayfactor) < 37.78:
dayfactor += 0.001
print("工作日的努力参数是:{:.3f} ".format(dayfactor)) # 工作日的努力参数是:0.019
工作日的努力参数是:0.019
二、字符串类型及操作
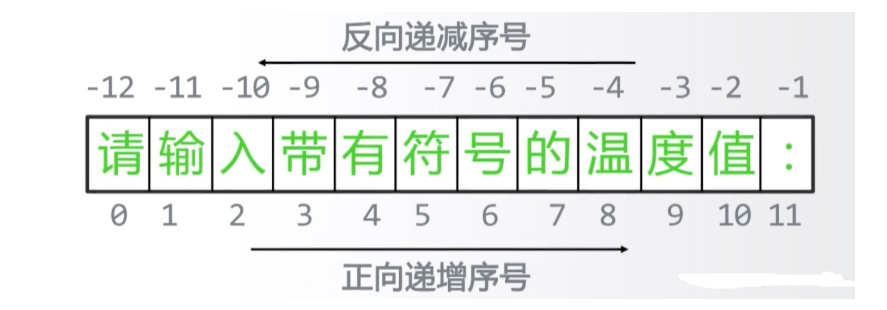
- 正向递增序号、反向递减序号、<字符串>[M:N:K]
- +、*、len()、str()、hex()、oct()、ord()、chr()
- .lower()、.upper()、.split()、.count()、.replace()
- .center()、.strip()、.join()、.format()格式化
# TextProBarV1.py
import time
scale = 10
print("执行开始".center(scale // 2, "-"))
start = time.perf_counter()
for i in range(scale + 1):
a = '*' * i
b = '.' * (scale - i)
c = (i / scale) * 100
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c, a, b, dur), end='')
time.sleep(0.1)
print("\n" + "执行结束".center(scale // 2, '-'))
-执行开始
100%[**********->]1.02s
-执行结束
三、程序的分支结构
- 单分支
if 二分支 if-else 及紧凑形式
- 多分支
if-elif-else 及条件之间关系
not and or > >= == <= < !=- 异常处理
try-except-else-finally
# CalBMIv3.py
height, weight = eval(input("请输入身高(米)和体重\(公斤)[逗号隔开]: "))
bmi = weight / pow(height, 2)
print("BMI 数值为:{:.2f}".format(bmi))
who, nat = "", ""
if bmi < 18.5:
who, nat = "偏瘦", "偏瘦"
elif 18.5 <= bmi < 24:
who, nat = "正常", "正常"
elif 24 <= bmi < 25:
who, nat = "正常", "偏胖"
elif 25 <= bmi < 28:
who, nat = "偏胖", "偏胖"
elif 28 <= bmi < 30:
who, nat = "偏胖", "肥胖"
else:
who, nat = "肥胖", "肥胖"
print("BMI 指标为:国际'{0}', 国内'{1}'".format(who, nat))
请输入身高(米)和体重\(公斤)[逗号隔开]: 1.8,70
BMI 数值为:21.60
BMI 指标为:国际'正常', 国内'正常'
四、程序的循环结构
for…in 遍历循环:计数、字符串、列表、文件…while无限循环continue和break保留字:退出当前循环层次- 循环else的高级用法:与
break有关
# CalPiV2.py
from random import random
from time import perf_counter
DARTS = 1000 * 1000
hits = 0.0
start = perf_counter()
for i in range(1, DARTS + 1):
x, y = random(), random()
dist = pow(x**2 + y**2, 0.5)
if dist <= 1.0:
hits = hits + 1
pi = 4 * (hits / DARTS)
print("圆周率值是: {}".format(pi))
print("运行时间是: {:.5f}s".format(perf_counter() - start))
圆周率值是: 3.141364
运行时间是: 0.71023s
五、代码复用与函数递归
- 模块化设计:松耦合、紧耦合
- 函数递归的2个特征:基例和链条
- 函数递归的实现:函数 + 分支结构
六、集合类型及操作
- 集合使用{}和set()函数创建
- 集合间操作:交(&)、并(|)、差(-)、补(^)、比较(>=<)
- 集合类型方法:.add()、.discard()、.pop()等
- 集合类型主要应用于:包含关系比较、数据去重
七、序列类型及操作
- 序列是基类类型,扩展类型包括:字符串、元组和列表
- 元组用()和tuple()创建,列表用[]和set()创建
- 元组操作与序列操作基本相同
- 列表操作在序列操作基础上,增加了更多的灵活性
八、字典类型及操作
- 映射关系采用键值对表达
- 字典类型使用{}和dict()创建,键值对之间用:分隔
- d[key] 方式既可以索引,也可以赋值
- 字典类型有一批操作方法和函数,最重要的是.get()
8.1 文件的使用
- 文件的使用方式:打开-操作-关闭
- 文本文件&二进制文件,open( , )和.close()
- 文件内容的读取:.read() .readline() .readlines()
- 数据的文件写入:.write() .writelines() .seek()
8.2 一维数据的格式化和处理
- 数据的维度:一维、二维、多维、高维
- 一维数据的表示:列表类型(有序)和集合类型(无序)
- 一维数据的存储:空格分隔、逗号分隔、特殊符号分隔
- 一维数据的处理:字符串方法 .split() 和 .join()
8.3 二维数据的格式化和处理
- 二维数据的表示:列表类型,其中每个元素也是一个列表
- CSV格式:逗号分隔表示一维,按行分隔表示二维
- 二维数据的处理:for循环+.split()和.join()