简介
大型软件系统生命周期的绝大部分都处于“使用”阶段,而非“设计”或“实现”阶段。那么为什么我们却总是认为软件工程应该首要关注设计和实现呢?在《SRE:Google运维解密》中,Google SRE的关键成员解释了他们是如何对软件进行生命周期的整体性关注的,以及为什么这样做能够帮助Google成功地构建、部署、监控和运维世界上现存最大的软件系统。通过阅读《SRE:Google运维解密》,读者可以学习到Google工程师在提高系统部署规模、改进可靠性和资源利用效率方面的指导思想与具体实践——这些都是可以立即直接应用的宝贵经验。
任何一个想要创建、扩展大规模集成系统的人都应该阅读《SRE:Google运维解密》。《SRE:Google运维解密》针对如何构建一个可长期维护的系统提供了非常宝贵的实践经验。
详细内容
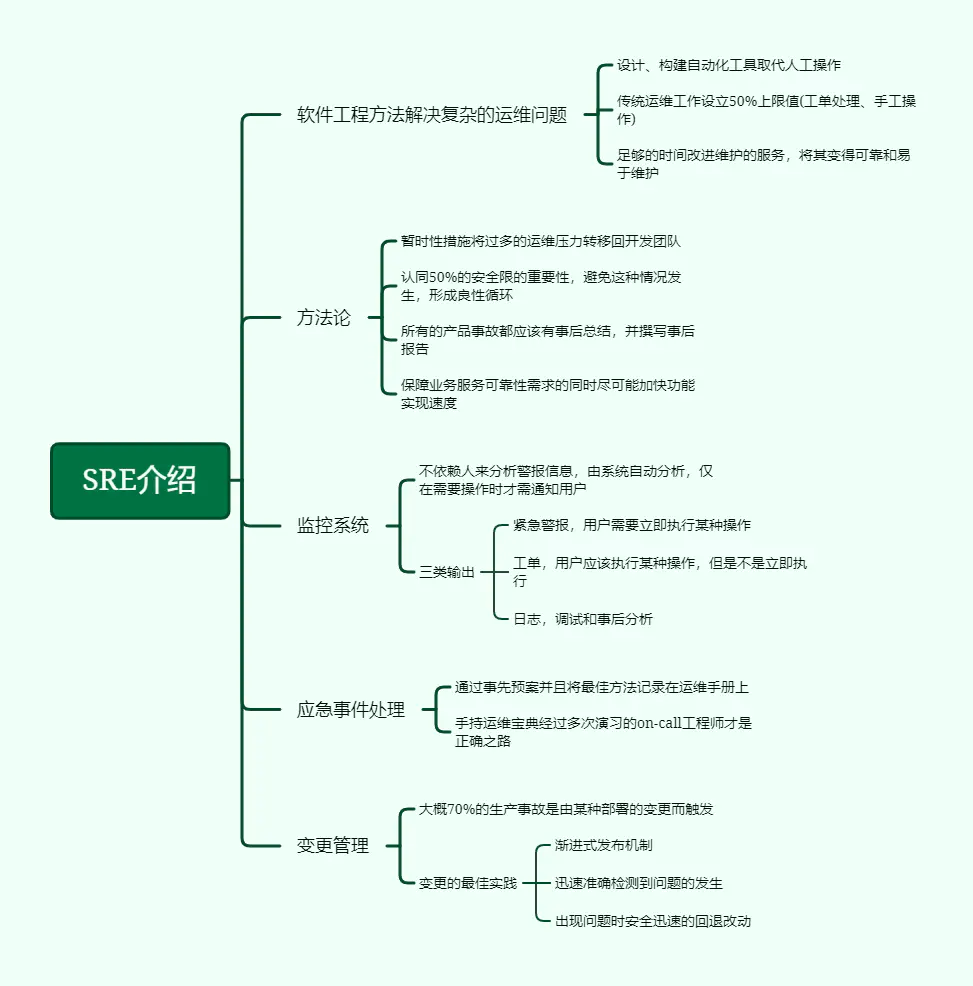
1、SRE介绍
四个方法论也给SRE指明一条可行的方法。手工操作和工单处理等传统运维工作不应该占用非常多的时间。运维SRE与开发团队认同50%的安全线的重要性,暂时性措施将过多的运维压力转移回开发团队,预留时间关注到开发工作上,改进流程或者报警等工作。
2、SRE视角

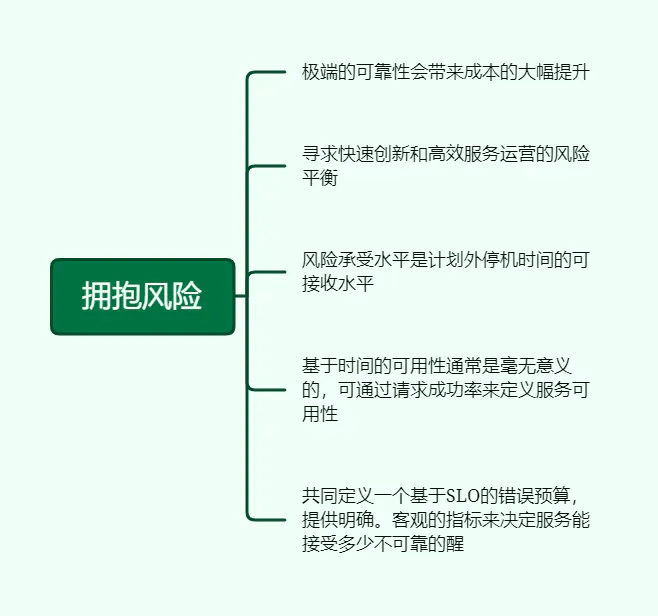
3、拥抱风险
共同定义一个基于SLO的错误预算,提供明确、客观的指标来决定服务能接受多少不可靠性。
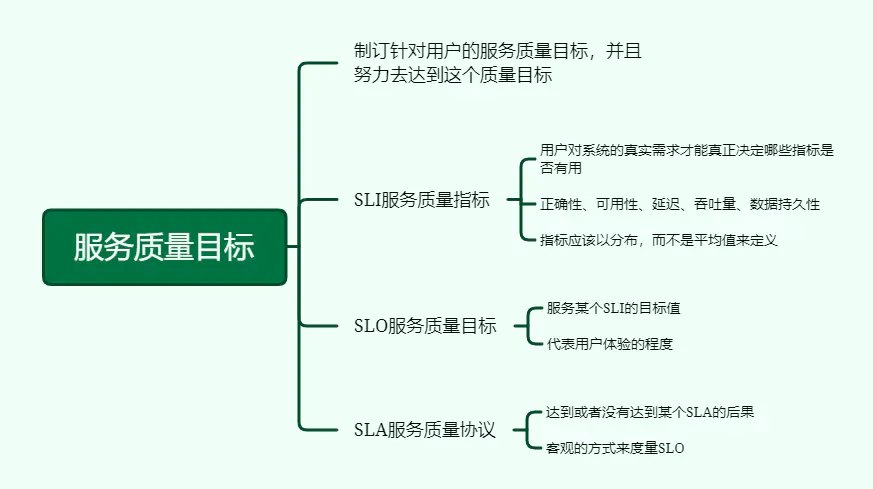
4、服务质量目标
制订针对用户的服务质量目标,并且努力去达到这个质量目标。
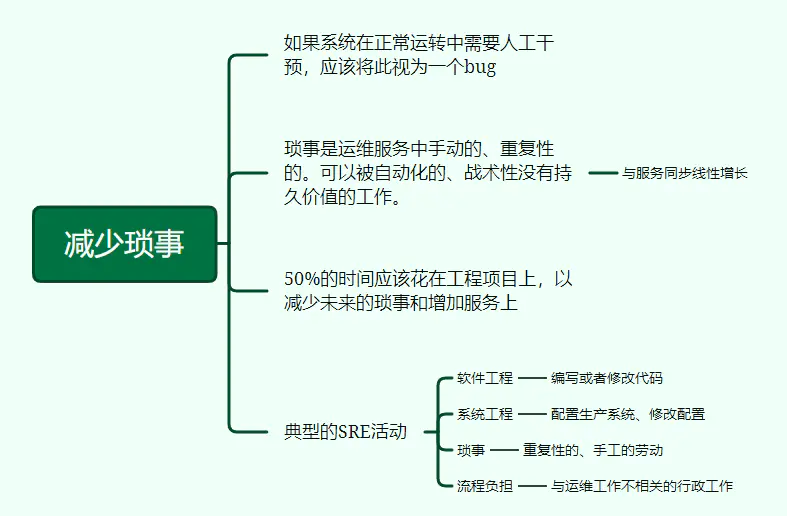
5、减少琐事
50%的时间应该花在工程项目上,以减少未来的琐事和增加服务上。
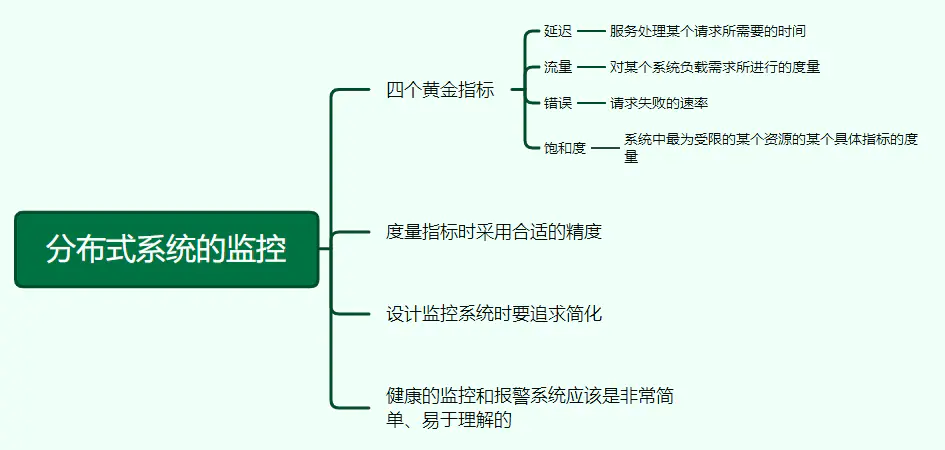
6、分布式系统的监控
健康的监控和报警系统应该是非常简单、易于理解的。四个黄金指标是:延迟、流量、错误、饱和度。
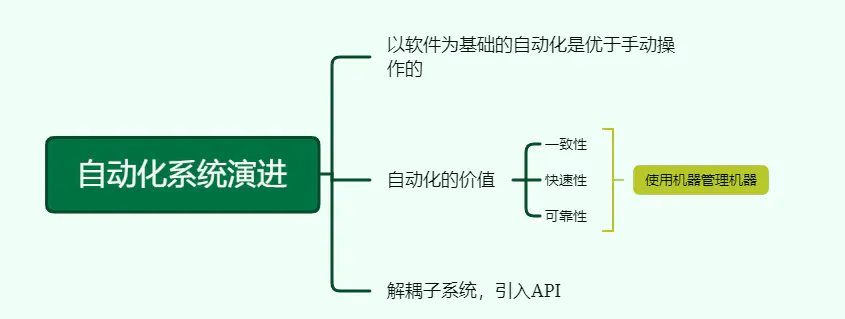
7、自动化系统演进
以软件为基础的自动化是优于手动操作的,自动化的价值体现在一致性、快速性、可靠性。
8、发布工程
采用合适的工具、合理的自动化方式,以及合理的政策来发布。
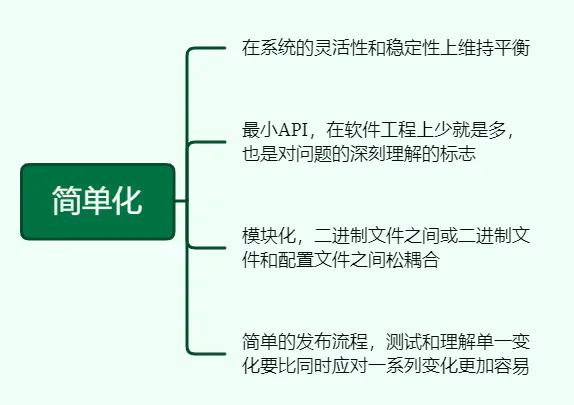
9、简单化
在系统的灵活性和稳定性上维持平衡,软件的简单性是可靠性的前提。
10、基于时间序列进行有效报警
将测试和报警模型变成海量信息收集和中央化规则计算、统一分析和报警的模型。
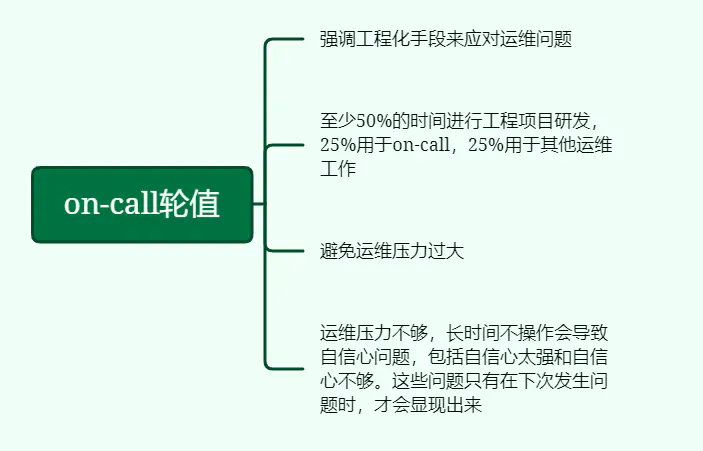
11、on-call轮值
强调工程化手段来应对运维问题。
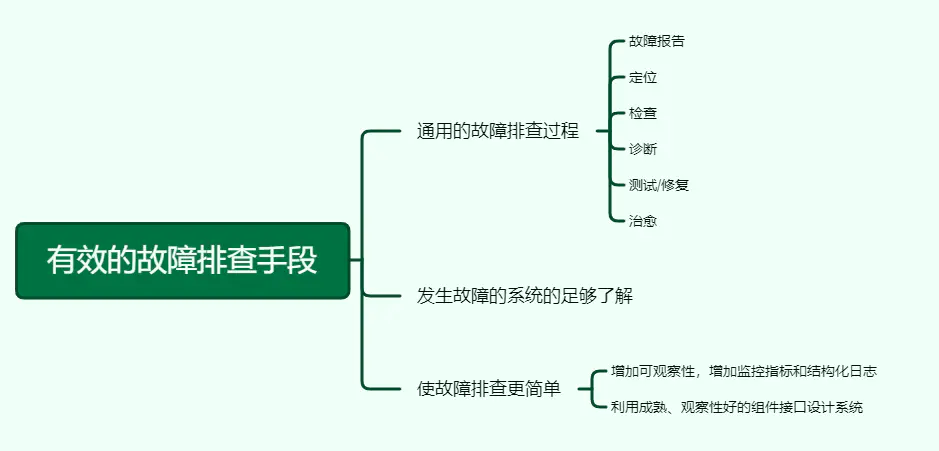
12、有效的故障排查手段
故障排查需要两个条件:通用的故障排查过程和发生故障的系统的足够了解。
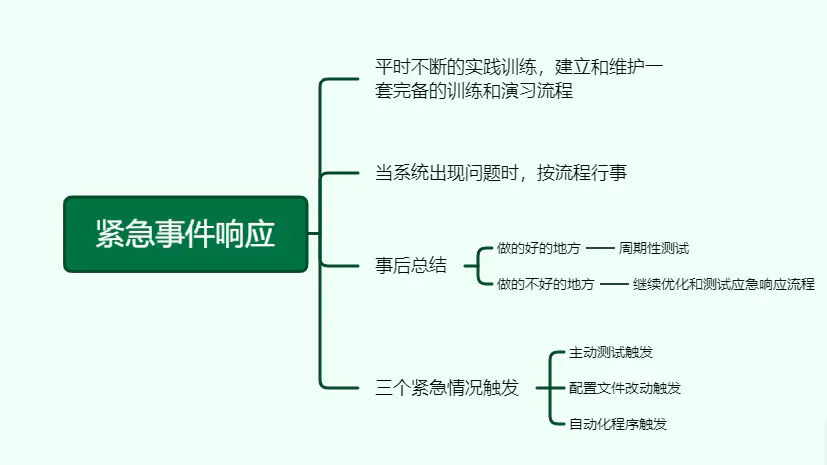
13、紧急事件响应
平时不断的实践训练,建立和维护一套完备的训练和演习流程。
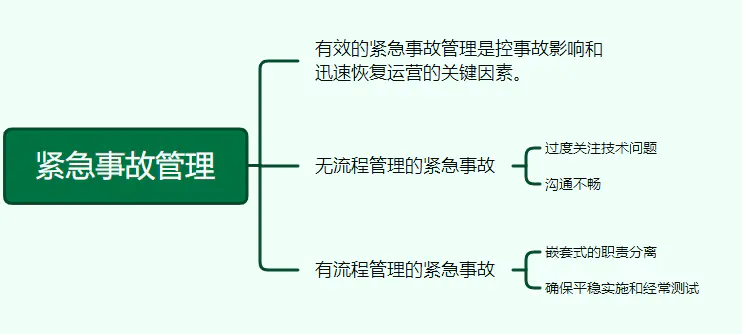
14、紧急事故管理
有效的紧急事故管理是控事故影响和迅速恢复运营的关键因素。
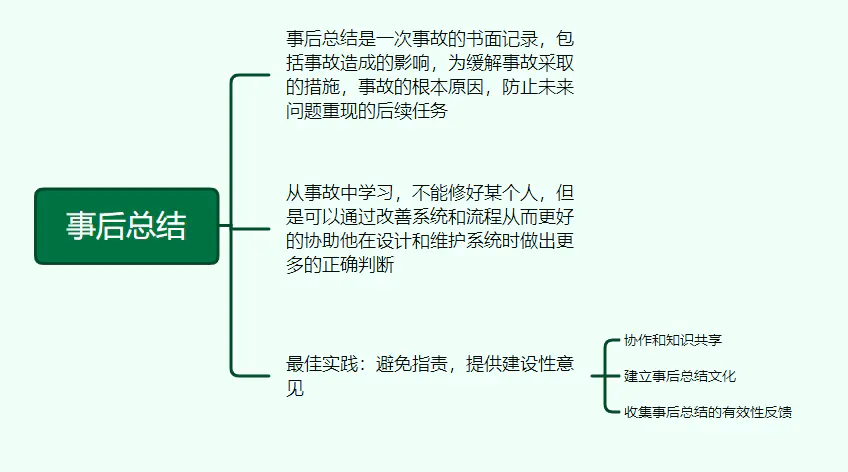
15、事后总结
事后总结是一次事故的书面记录,包括事故造成的影响,为缓解事故采取的措施,事故的根本原因,防止未来问题重现的后续任务。
16、跟踪故障
提高可靠性的唯一方法是建立一个基线,不断跟踪改变。收集监控系统发出的报警信息,同时提供标记、分组和数据分析功能。
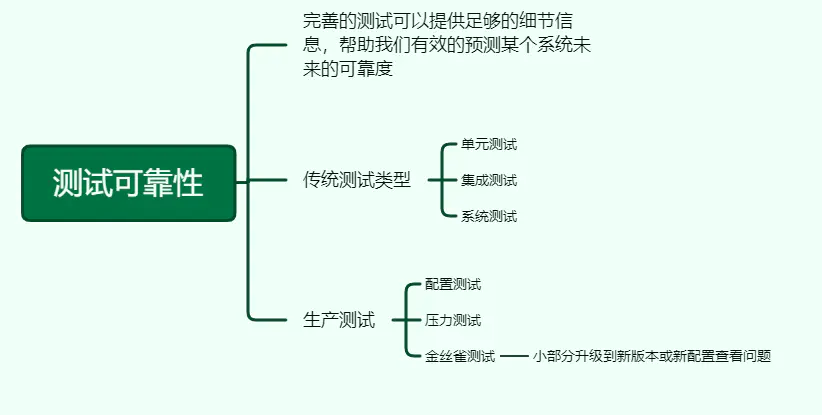
17、测试可靠性
完善的测试可以提供足够的细节信息,帮助我们有效的预测某个系统未来的可靠度。
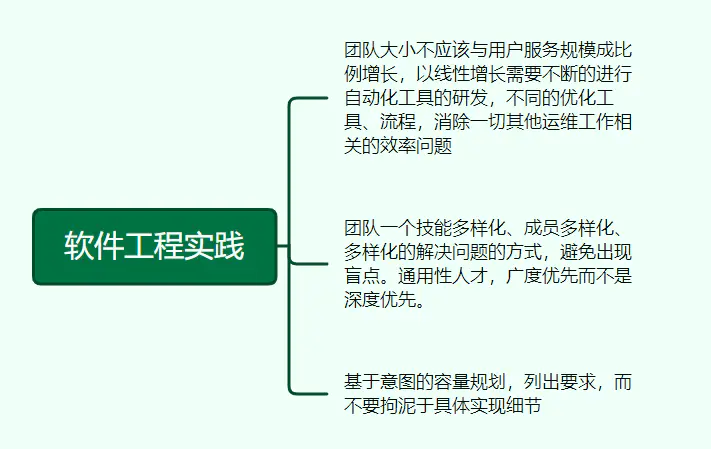
18、软件工程实践
团队大小不应该与用户服务规模成比例增长,以线性增长需要不断的进行自动化工具的研发,不同的优化工具、流程,消除一切其他运维工作相关的效率问题。
19、前端服务器的负载均衡
使用DNS和VIP进行负载均衡。
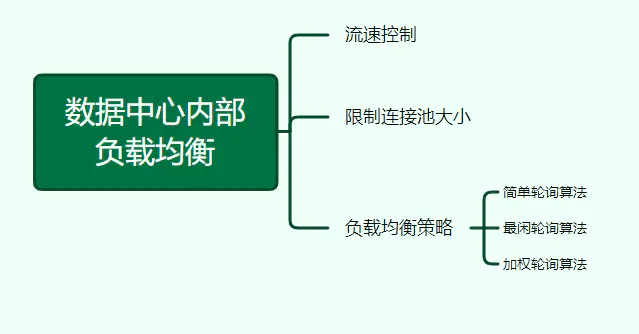
20、数据中心内部的负载均衡
21、应对过载
应对过载的一个选项就是服务降级,系统能够优雅的处理过载情况。
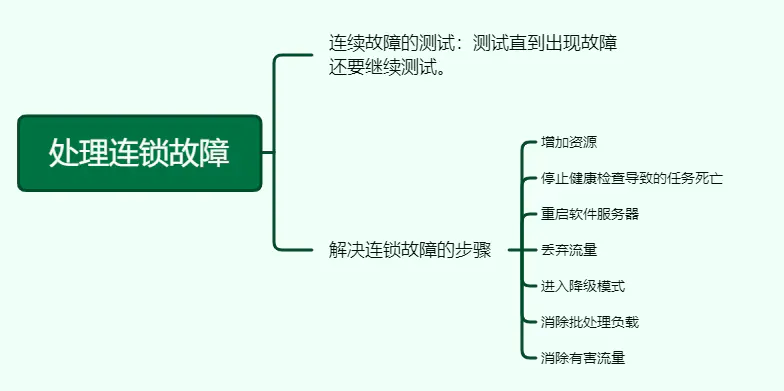
22、处理连锁故障
连续故障的测试:测试直到出现故障还要继续测试。
23、分布式来提高可靠性
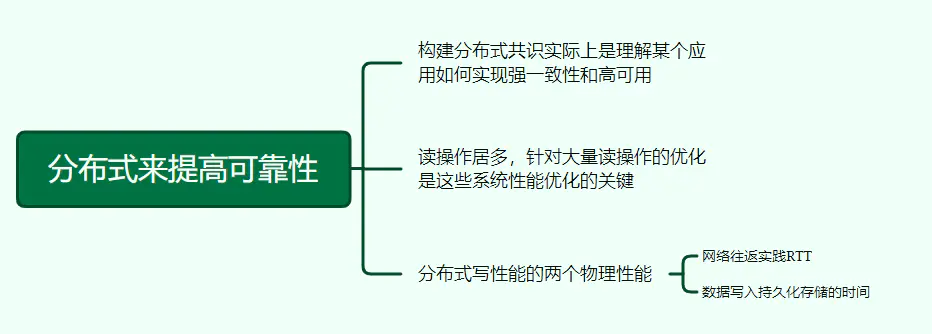
24、分布式周期性任务系统
为提升cron的可靠性,将实际进程与物理机分开。
25、数据处理流水线
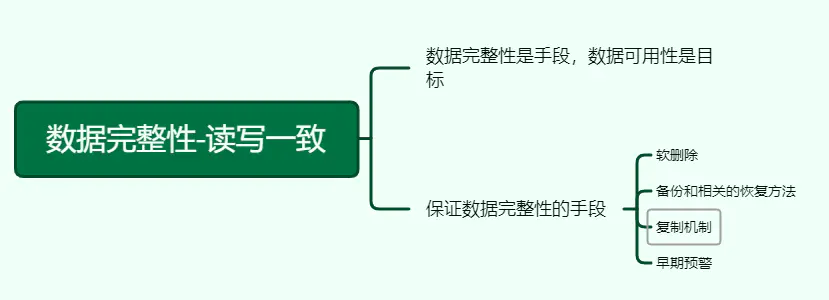
26、数据完整性-读写一致
数据完整性是手段,数据可用性是目标。
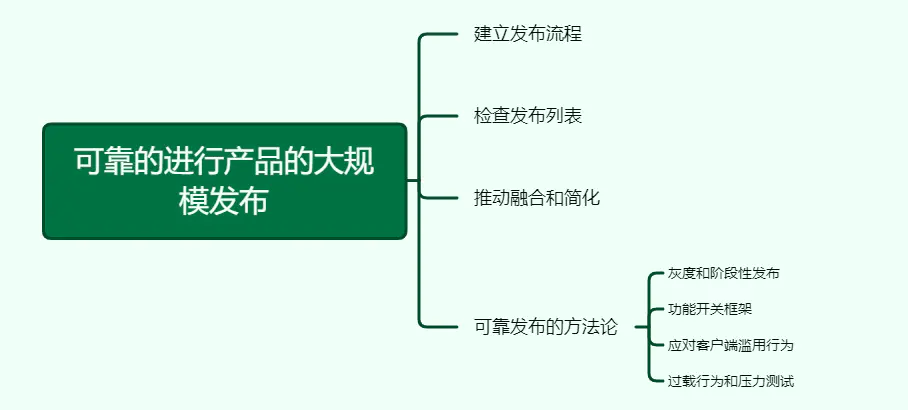
27、可靠的进行产品的大规模发布
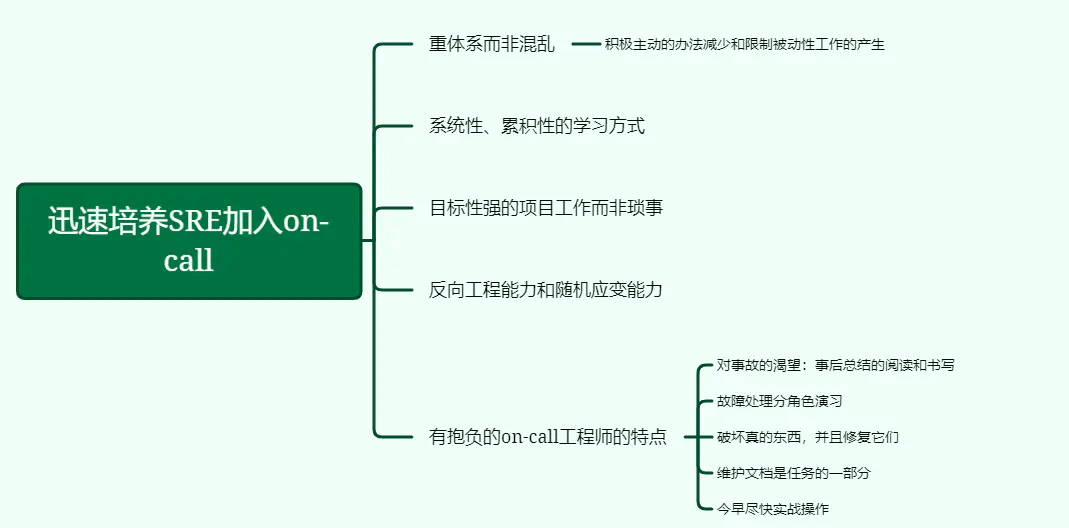
28、迅速培养SRE加入on-call
系统性、累积性的学习方式,SRE应该积极主动的办法减少和限制被动性工作的产生。
29、处理中断性任务
为了限制干扰数量,应该减少上下文切换(工作类型、环境等改变)。
30、从运维过载中恢复
减少花在改进服务上的时间,服务的可扩展性和可靠性随之变差。
31、与其他团队的沟通协作
做任何高价值的事情都需要很多人协作。
32、参与模式的演进历程
SRE参与的时机越早,该服务的质量提升越快,最终质量也越好。
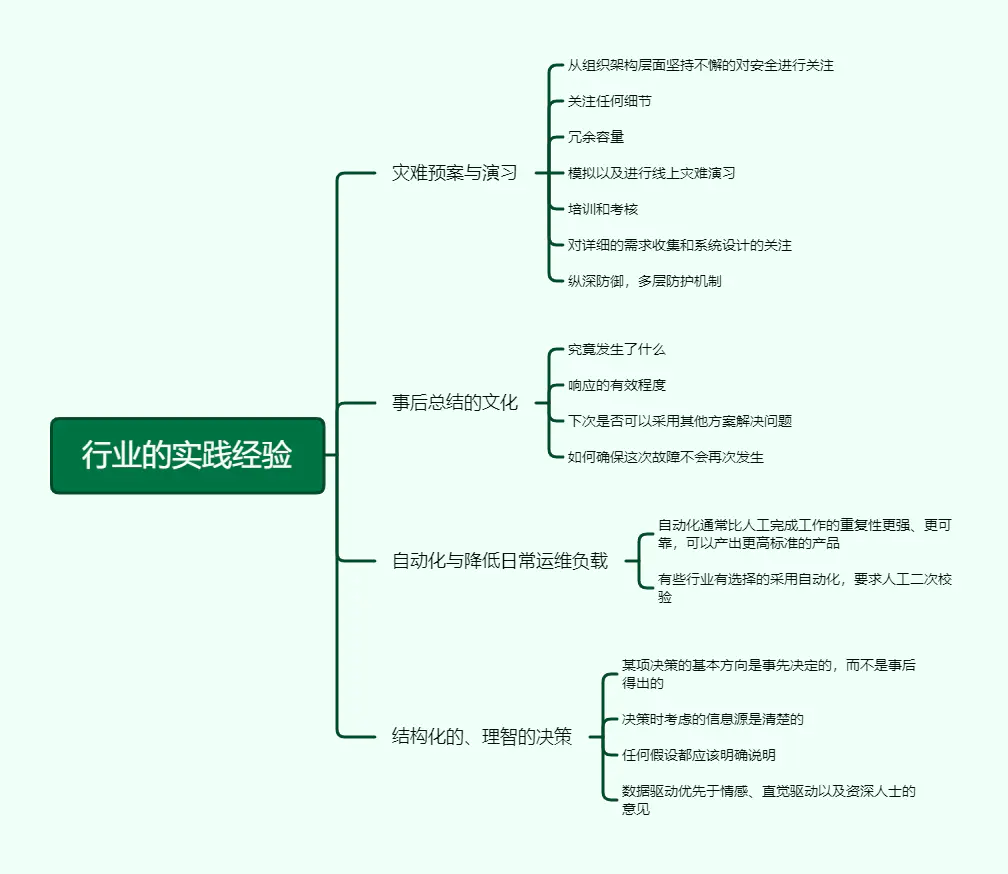
33、其他行业实践经验
在高可靠性的预期和快速变更与创新的追求之间寻求平衡。
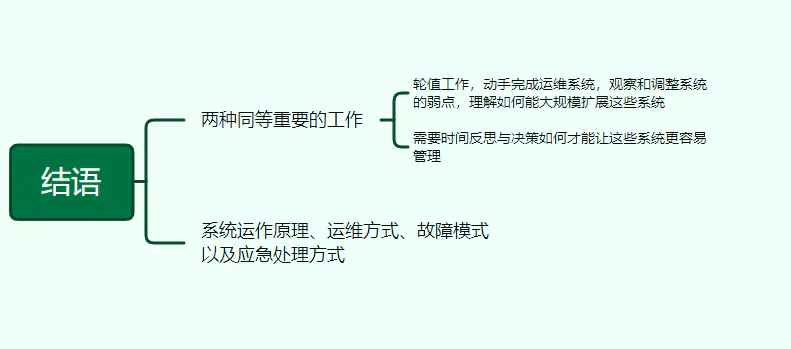
34、结语
两种同等重要的工作:轮值工作,动手完成运维系统,观察和调整系统的弱点,理解如何能大规模扩展这些系统。另外需要时间反思与决策如何才能让这些系统更容易管理。
下载地址
链接: 立即下载 提取码: wtjy