K-Means聚类算法
K-means聚类算法属于无监督学习算法,它实现简单并且聚类效果优良,所以在工业界也被广泛应用。同时K-Means聚类算法也有大量的变体,本文将从最传统的K-Means聚类算法讲起,让后在其基础上讲解K-Means聚类算法的变体,其中它的变体包括初始化优化K-Means++、距离计算优化elkan K-Means和大数据情况下的优化Mini Batch K-Means算法。
K-Means聚类算法学习目标
- K-Means聚类算法原理以及它的优缺点
- K-Means初始化优化之K-Means++算法
- K-Means距离计算优化之elkan K-Means算法
- 大数据优化之Mini Batch K-Means算法
- K-Means聚类算法和KNN(k近邻算法)的区别
K-Means聚类算法详解
K-Means聚类算法原理
K-Means的思想非常简单,对于给定的样本集,按照样本集之间的距离大小,将样本集分成K个簇。需要注意的是:每个簇之间的点尽量相近,而簇与簇之间的距离尽量较大。
假设目前有k个簇分别为${C_1,C_2,\cdots,Ck}$,在这里我们使用均方误差度量簇内点与点的误差,即误差定义为:
$$
E = \sum{i=1}^k\sum_{x\in{C_i}}||x-\mu_i||_2^2
$$
其中$\mu_i$是簇$C_i$的均值向量,有时有称为质心,表达式为:
$$
\mu_i = \frac{1}{Ci}\sum{x\in{C_i}}x
$$
对于上式,它是一个NP难的问题(计算量非常大的问题),因此求上式的最小值只能采用启发式的迭代方法。
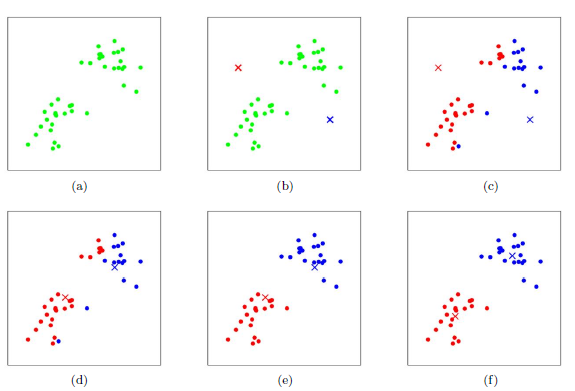
上图a表示初始的数据集,假设k=2,即我们要分成对上述数据集分成两个簇。首先我们需要随机选择两个k类所对应的类别质心,即图b中的红点和蓝点;然后分别计算样本中所有点到这两个质心的距离,同时标记每个样本的类别为该样本距离最小的质心的类别,此时我们得到第一轮迭代后的类别,如图c所示;对于已经被标记为两个不同的类别,我们计算这两个类别的新的质心,如图d所示;然后我们重复图c和图d的过程,将所有点的类别标记为距离最近的质心的类并求新的质心,最终算法将会收敛至图f。
K-Means聚类算法和KNN
相同点:
- K-Means聚类算法和KNN(K近邻算法)都是找到离某一个点最近的点,即两者都使用了最近领的思想
不同点:
- K-Means聚类算法是无监督学习算法,没有样本输出;KNN是监督学习算法,有对应的类别输出
- K-Means在迭代的过程中找到K个类别的最佳质心,从而决定K个簇类别;KNN则是找到训练集中离某个点最近的K个点
传统的K-Means聚类算法流程
对于传统的K-Means聚类算法,我们需要注意以下两点:
- 我们需要注意K-Means聚类算法的K值的选择,一般我们会根据对数据的先验经验选择一个合适的K,即可以通过专家的经验进行选择;如果没有先验知识,我们可以通过交叉验证的方法选择一个合适的K值。
- 确定K值,即质心的个数之后。我们需要确定这个K个质心的位置,因为这K个质心的位置对最后的聚类结果和运行时间都有一定的影响,因此需要选择合适的K个质心,一般情况下这K个质心不要太近。