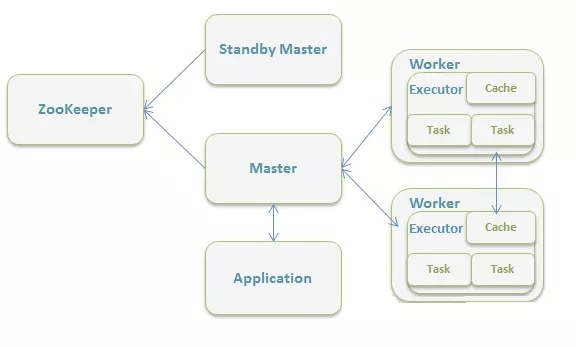
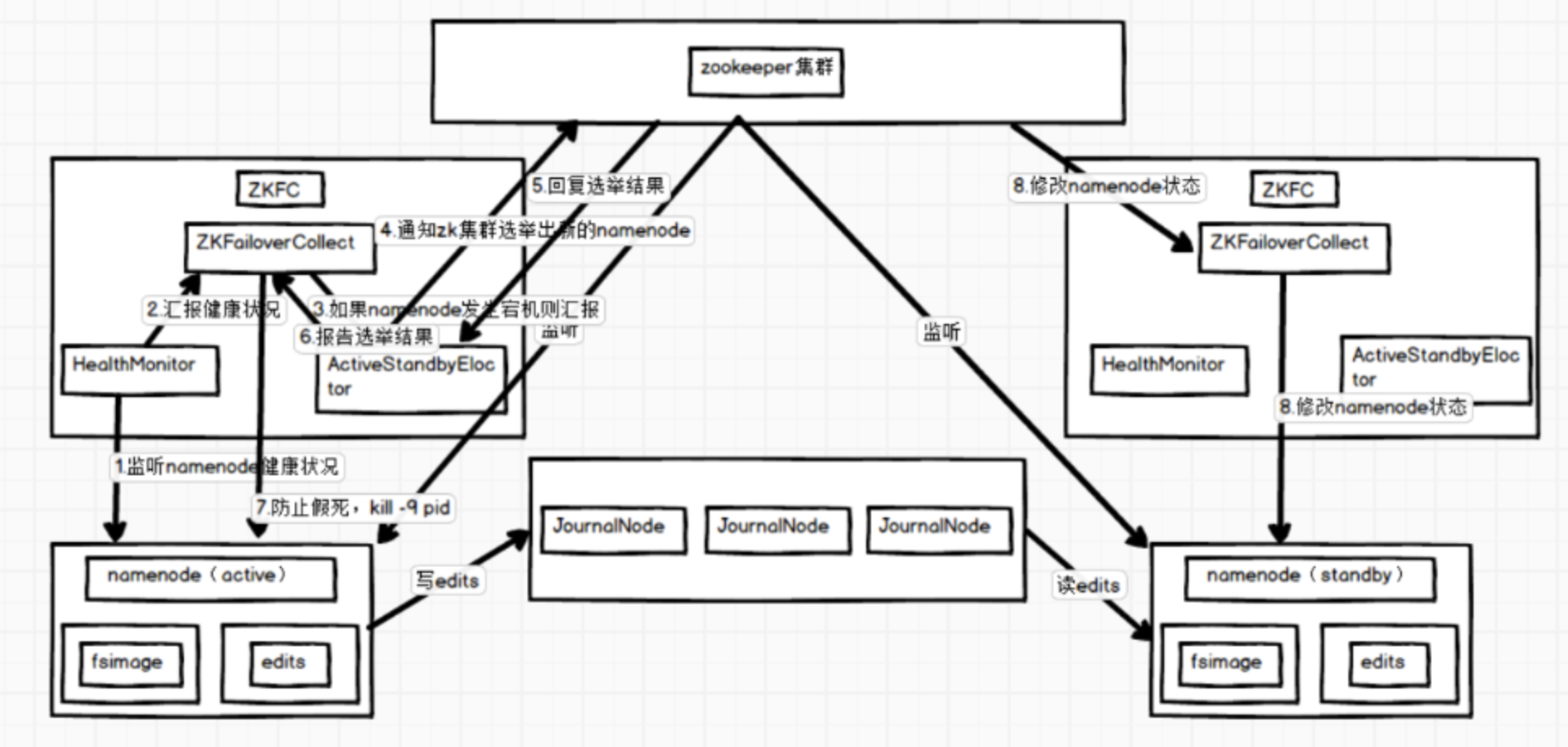
Hadoop、Hive、Spark 之间是什么关系?
一 前言 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽然奇怪的组合也能工作,但是未必是最佳选择。 二 大数据,首先…
haproxy+keepalived
spark01 主 10.61.187.24 spark02 从 10.61.187.20 vip: 10.61.187.51 在spark01与spark02部署 yum -y install haproxy keepalived -y # yum源已配置过了,此处直接安装即可 在spark01与spark02修改haproxy配置:vim /e…
Zookeeper完全分布式集群的搭建
一、集群模式 1、单机模式 在zoo.cfg中只配置一个server.id就是单机模式了。 这种模式下,如果当前主机宕机,那么所有依赖于当前zookeeper服务工作的其他服务器都不能在进行正常工作,这种事件称为单节点故障。所以这种模式一般用在测试环境。 2、伪分布式 在zoo.cfg中配置多个server.id,其中ip都是当前机器,而端口各不相…