一、介绍
- 1、主从模式:
特点:master 节点挂掉后,需要手动指定新的 master,可用性不高
适用场景:基本不用 - 2、哨兵模式:
特点:master 节点挂掉后,哨兵进程会主动选举新的 master,可用性高,但是每个节点存储的数据是一样的,浪费内存空间(这一条是相对下面的集群模式来说的)。
适用场景:数据量不是很多、当集群规模不是很大、需要自动容错容灾的时候使用。 - 3、集群模式:
特点:Redis Cluster 模式是在2015年4月发布的3.0版本中引入的,解决了故障切换,加数据分布均匀的问题(基于slot 槽,类似于一执行hash对数据进行分片)最大限度利用了内存。
使用场景:数据量比较大、QPS 要求较高的时候使用。
二、主从模式
2.1 介绍
redis主从:
1、一主多从,主负责写,从负责读
2、没有故障切换
3、一个主节点可以有多个从节点,但是一个从节点会只会有一个主节点,也就是所谓的一主多从结构。
主从同步流程/原理:主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
详见2.3小节
2.2 配置示例
| 机器名称 | IP | 端口 |
|---|---|---|
| master | 192.168.71.12 | 6379 |
| slave1 | 192.168.71.14 | 6379 |
| slave2 | 192.168.71.15 | 6379 |
| slave3 | 192.168.71.16 | 6379 |
所有节点
setenforce 0
systemctl stop firewalld
yum install redis -y先强调一个点:考虑到后续主从可能会发生切换,所以为了方便,建议无论主从,最开始都在redis.conf中配置上这两项且保持密码一致
masterauth 123456 # 连接主库用的密码,是主库里设置的密码
requirepass 123456 # 为自己这个redis设置的密码主节点配置,随后先启动主节点
# 一、配置文件/etc/redis/redis.conf # 配置项末尾不要加注释
cat > /usr/local/redis/conf/redis.conf << 'EOF'
daemonize yes
bind 0.0.0.0
port 6379
masterauth 123456
requirepass 123456
EOF
# 二、重启
systemctl restart redis从节点配置(三台都一样),然后一台台启动从节点
# =========================》redis.conf配置如下(# 配置项末尾不要加注释)
cat > /usr/local/redis/conf/redis.conf << 'EOF'
# (1)修改
daemonize yes
bind 0.0.0.0
port 6379
# (2)增加
# 配置主节点的ip和端口
slaveof 192.168.71.12 6379
# 从redis2.6开始,从节点默认是只读的
slave-read-only yes
# 主节点有登录密码,则必须指定
masterauth 123456
# 建议在从上也设置与主一模一样的密码,这与后续你切主会方便一些,因为无论哪个节点都是一样的密码
requirepass 123456
EOF也可以不配置上面的文件,使用 redis-server 命令,在启动从节点时,通过参数–slaveof 指定主节点是谁。。
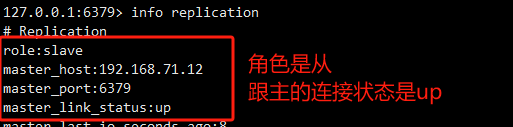
./redis-server --slaveof 192.168.71.12 6379可以登录主或从节点查看主从状态
info replication
# 注意:redis 6.x版本与redis3.x版本不兼容
你用centos7.9默认yum安装的就是redis3.x版本,你用centos9默认yum安装的是redis6.x版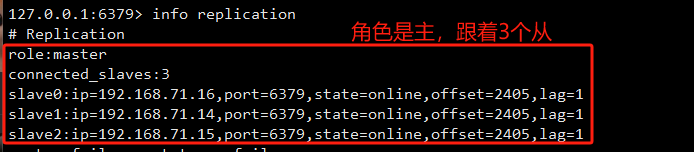
系统运行时,如果 master 挂掉了,可以在一个从库(如 slave1)上手动执行命令,slave2也是一样
slaveof no one # 将 slave1 变成新的 master
slaveof 192.168.71.14 6379 # 将这两个机器的主节点指向的这个新的 master;
补充:
执行命令slaveof no one命令,可以关闭从服务器的复制功能。同时原来同步的所得的数据集都不会被丢弃。挂掉的原 master修复 启动后作为新的 slave 也指向新的 master 上。
2.3 流程详解
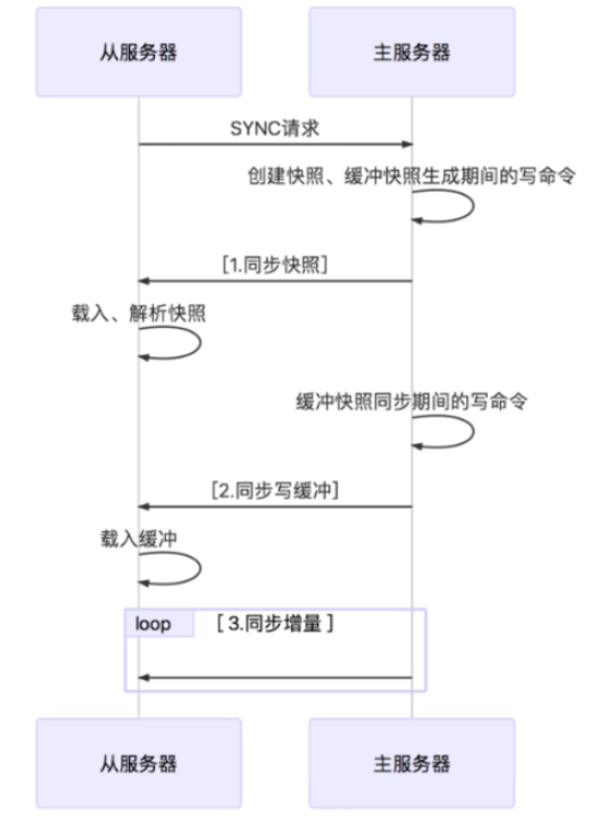
简述:从库执行sync,主收到后先执行bgsave命令并把得到的快照发给从库,从库收到后先进行全量同步数据,全量同步的期间内主库的一直在记录增量数据,待从库同步完全量后,再同步增量,然后后续就是只同步增量了
详解如下
- 从数据库连接主数据库,发送 SYNC 命令;
- 主数据库接收到 SYNC 命令后,可以执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令;
- 主数据库 BGSAVE 执行完后,向所有从数据库发送快照文件,并在发送期间,主库会继续记录被执行的写命令到自己的缓冲区中;
- 从数据库收到快照文件后丢弃所有旧数据,载入收到的快照;-
- 主数据库快照发送完毕后开始向从数据库发送缓冲区中的写命令;
- 从数据库完成对快照的载入,开始接受命令请求,并执行来自主数据库缓冲区的写命令;(从数据库初始化完成)
- 后续主数据库每执行一个写命令就会向从数据库发送相同的写命令,从数据库接收并执行收到的写命令(从数据库初始化完成后的操作)
补充说明:出现断开重连后,2.8 之后的版本会将断线期间的命令传给从数据库,增量复制。
三、哨兵模式
3.1 介绍
1、哨兵模式介绍哨兵模式介绍
哨兵模式就是为了解决主从模式无法自动故障切换而诞生的,把下图的哨兵节点去掉后就是主从模式
哨兵(sentinel)是Redis的高可用性(High Availability)的解决方案:由一个或多个sentinel实例组成sentinel集群可以监视一个或多个主服务器和多个从服务器。当主服务器进入下线状态时,sentinel可以将该主服务器下的某一从服务器升级为主服务器继续提供服务,从而保证redis的高可用性。
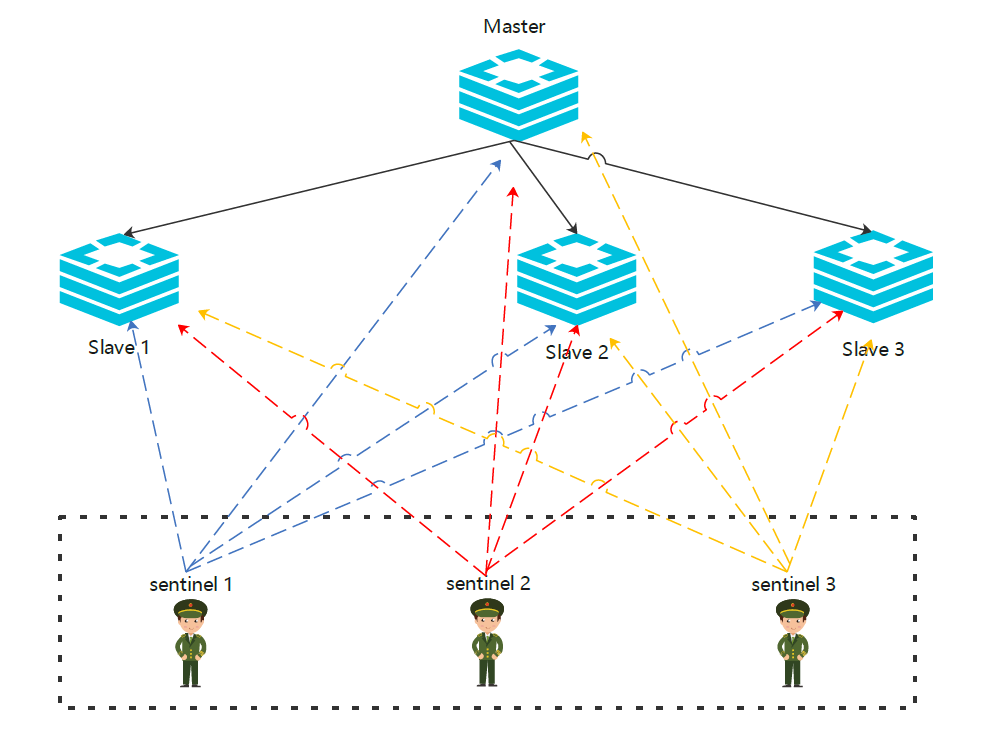
2、哨兵节点是什么?
哨兵节点是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。
3、哨兵节点具体都干什么,主要任务总结如下
(1)监控:哨兵会不断地检查你的Master和Slave是否运作正常。
(2)提醒(通知):当被监控的某个Redis节点出现问题时,哨兵可以通过 API 向管理员或者其他应用程序发送通知。
(3)自动故障转移:当一个Master不能正常工作时,哨兵会进行自动故障迁移操作,将失效Master的其中一个Slave升级为新的Master,并让失效Master的其他Slave改为复制新的Master;当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用新Master代替失效Master。
4、哨兵模式下,客户端程序如何连接redis集群呢?
在Java客户端连接哨兵,只需要配置哨兵节点即可
spring.redis.sentinel.master=mymaster #哨兵配置文件中定义的集群名字 spring.redis.sentinel.nodes=哨兵ip1:哨兵端口1,哨兵ip2:哨兵端口2,哨兵ip3:哨兵端口3
5、哨兵模式下,客户端程序从哨兵那里获取到主节点ip后,以后每次都会询问哨兵要主节点ip吗?
答:不会
哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点。
那主节点挂掉后哨兵推荐出新的master后客户端如何知晓呢?
答:当redis的主节点挂掉时,哨兵会第一时间感知到,并且在slave节点中重新选出来一个新的master,然后将新的master信息通知给client端,从而实现高可用。
这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息。
3.2 配置示例(哨兵节点通常为奇数个)
上我们之前配置的主从模式基础上进行就行
| 机器名称 | IP | 端口 |
|---|---|---|
| master | 192.168.71.12 | 6379 |
| slave1 | 192.168.71.14 | 6379 |
| slave2 | 192.168.71.15 | 6379 |
| slave3 | 192.168.71.16 | 6379 |
| sentinel 1 | 192.168.71.17 | 26379 |
| sentinel 2 | 192.168.71.18 | 26379 |
| sentinel 3 | 192.168.71.19 | 26379 |
这里我们将哨兵进程和 redis 分别部署在不同的机器上,避免因为 redis 宕机导致 sentinel 进程不可用。
所有节点
setenforce 0
systemctl stop firewalld
yum install redis -y之前我们已经部署过redis主从了,我们只需要在此基础之上新增哨兵就行
# 三台哨兵节点都需要安装
yum install redis -y
# 每台机器的哨兵进程都需要一个哨兵的配置文件sentinel.conf,三台机器的哨兵配置是一样的。
====================》 vi /etc/redis/sentinel.conf # 配置项概述
# 1、禁止保护模式,保护模式是增强redis安全防止未经授权的客户端访问redis实例
protected-mode no
# 2、
sentinel monitor <master-name> <ip> <redis-port> <quorum>
# 各部分解释
# (1)sentinel monitor: 代表监控
# (2)<master-name>:mymaster代表哨兵集群的名字,客户端连接的时候需要用这个名字。只能由字母A-z、数字0-9 、这三个字符".-_"组成
# (3)<ip> <redis-port>:被监控的主从集群中主节点的ip与port
# (4)<quorum>:当quorum个数的哨兵节点认为master主节点失联 那么这时客观上认为主节点失联了
# 3、当主从的master存在密码时,需要配置密码
sentinel auth-pass <master-name> <password>
# 各部分解释
# (1)<master-name>:是你的哨兵集群名字
# (2)<password>:是哨兵 sentinel 连接主从的密码,与你在主从redis.conf配置的requirepass保持一致
# 补充:由于master挂了之后,哨兵会进行重新的选举,如果slave也配置了连接密码,那么最好在其他的节点都配置上 masterauth xxx,保证挂了的服务重启之后能正常加入主从中去。
# 4、修改心跳检测的主观下线时间
sentinel down-after-milliseconds <master-name> <milliseconds> # 单位毫秒,即千分之一秒
# 5、默认情况一旦主redis节点发生故障,哨兵会将所有的从都切换到新主,这个切换过程中,所有从服务器将暂时无法提供服务。为了解决这一问题,官方提供了如下设置
sentinel parallel-syncs <master-name> <numslaves>
假设你有5个从服务器,故障切换发生之后,如果parallel-syncs的<numslaves>设置为3,那么在故障切换发生后:
- 1、最初的3个从服务器开始与新主建立连接并同步数据。
- 2、在这3个从服务器完成同步并作为新主的从服务器提供服务后,剩下的2个从服务器开始切换过程。
- 3、这2个从服务器断开与旧主的连接,然后尝试与新主建立连接并同步数据。
- 4、当这2个从服务器完成同步后,它们也将作为新主的从服务器恢复服务。
通过这个设置,你可以控制并发切换的从服务器的数量,保留一部分从服务器在切换过程中提供服务,
从而在一定程度上减轻由于主服务器故障切换导致的服务中断时间。尤其在新主服务器数据量大,
同步需要较长时间的情况下,这个设置可以有效地缓解服务中断的影响。配置示例 /etc/redis/sentinel.conf # 如果你是源码安装,那在源码包解压目录下就有一个模版配置sentinel.conf
# 完整配置如下
cat > /usr/local/redis/conf/sentinel.conf << 'EOF'
#1、哨兵默认端口
protected-mode no
bind 0.0.0.0
port 26379
#2、常规配置:目录要创建好
daemonize yes
pidfile /var/run/redis-sentinel.pid
loglevel notice
logfile "/soft/sentinel/sentinel.log"
dir "/soft/sentinel/data"
#3、表示配置哨兵,有2个哨兵作出同样的决策,才有决策权
sentinel monitor mymaster 192.168.71.101 6379 2
#4、登录密码
sentinel auth-pass mymaster 123456
#5、master被sentinel认定为失效的间隔时间
sentinel down-after-milliseconds mymaster 30000
#6、剩余的slaves重新和新的master做同步的并行个数
sentinel parallel-syncs mymaster 2
#7、主备切换的超时时间,哨兵要去做故障转移,这个时候哨兵也是一个进程,如果他没有去执行,超过这个时间后,会由其他的哨兵来处理
sentinel failover-timeout mymaster 180000
#8、其他配置
acllog-max-len 128
sentinel deny-scripts-reconfig yes
SENTINEL resolve-hostnames no
SENTINEL announce-hostnames no
SENTINEL master-reboot-down-after-period mymaster 0
EOF
启动
#1、先创建好目录
mkdir -p /soft/sentinel/
mkdir -p /soft/sentinel/data
# 2、然后启动
pkill -9 redis-sentinel
redis-sentinel /usr/local/redis/conf/sentinel.conf # 因为我们设置了daemonize yes所以可以直接启动
# 3、查看端口监听情况
[root@m01 ~]# netstat -an |grep 26379
tcp 0 0 0.0.0.0:26379 0.0.0.0:* LISTEN
tcp6 0 0 :::26379 :::* LISTEN
# 4、查看日志
tail -f /soft/sentinel/sentinel.log
# 5、你可以停掉主库,做测试,会发现30s就会判定ok完成自动选主 ,因为我们设置的判定时间就是30s3.3、哨兵工作原理
哨兵是一个分布式系统,可以在一个架构中运行多个哨兵进程,这些进程使用流言协议(gossip protocols)来传播Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。具体工作原理下面讲述。
(1)心跳检测机制
- Sentinel 与 Redis Node的关系
Redis Sentinel 哨兵节点 是一个特殊的 Redis 节点。在哨兵模式创建时,需要通过配置指定 Sentinel 与 Redis Master Node 之间的关系,然后 Sentinel 会从主节点上获取所有从节点的信息,之后 Sentinel 会定时向主节点和从节点发送 info 命令获取其拓扑结构和状态信息。 - Sentinel与Sentinel之间是如何沟通的
答:基于 Redis 的订阅发布功能, 每个 Sentinel 节点会向主 sentinel:hello 频道上发送该 Sentinel 节点对于redis master node的判断以及当前 Sentinel 节点的信息 ,同时每个 Sentinel 节点也会订阅该频道, 来获取其他 Sentinel 节点的信息以及它们对redis master node的判断。
通过以上两步所有的 Sentinel 节点以及它们与所有的 Redis 节点之间都已经彼此感知到,之后每个 Sentinel 节点会向主节点、从节点、以及其余 Sentinel 节点定时发送 ping 命令作为心跳检测, 来确认这些节点是否可达。
(2)判断master节点是否下线
- 每个Sentinel每秒一次向所有与它建立了命令连接的实例(主服务器、从服务器和其他Sentinel)发送PING命令,作用是通过心跳检测,检测主从服务器的网络连接状态。
- 如果 master 节点回复 PING 命令的时间超过 down-after-milliseconds 设定的阈值(默认30s),则这个 master 会被 sentinel 标记为主观下线,修改其 flags 状态为SRI_S_DOWN。
- 当sentinel 哨兵节点将 master 标记为主观下线后,会向其余所有的 sentinel 发送sentinel is-master-down-by-addr消息,询问其他sentinel是否同意该master下线。
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> # ip:主观下线的服务ip # port:主观下线的服务端口 # current_epoch:sentinel的纪元 # runid:*表示检测服务下线状态,如果是sentinel的运行id,表示用来选举领头sentinel - 每个sentinel收到命令之后,会根据发送过来的 ip和port 检查自己判断的结果,回复自己是否认为该master节点已经下线了。
<down_state>< leader_runid >< leader_epoch > # down_state(1表示已下线,0表示未下线) # leader_runid(领头sentinal id) #leader_epoch(领头sentinel纪元) - sentinel收到回复之后,如果同意master节点进入主观下线的sentinel数量大于等于quorum,则master会被标记为客观下线,即认为该节点已经不可用。
- 在一般情况下,每个 Sentinel 每隔 10s 向所有的Master,Slave发送 INFO 命令。当Master 被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次。作用:发现最新的集群拓扑结构。
(3)基于Raft协议的哨兵leader选举
到现在为止,已经知道了master客观下线,那就需要一个sentinel来负责故障转移,那到底是哪个sentinel节点来做这件事呢?需要通过选举实现,具体的选举过程如下:
- 判断客观下线的sentinel节点向其他 sentinel 节点发送 SENTINEL is-master-down-by-addr ip port current_epoch runid;(注意:这时的runid是自己的run id,每个sentinel节点都有一个自己运行时id)
- 目标sentinel回复是否同意master下线并选举领头sentinel,选择领头sentinel的过程符合先到先得的原则。举例:sentinel1判断了客观下线,向sentinel2发送了第一步中的命令,sentinel2回复了sentinel1,说选你为领头,这时候sentinel3也向sentinel2发送第一步的命令,sentinel2会直接拒绝回复;
- 当sentinel发现选自己的节点个数超过 majority 的个数的时候,自己就是领头节点;
- 如果没有一个sentinel达到了majority的数量,等一段时间,重新选举。
(4)故障转移
有了领头sentinel之后,下面就是要做故障转移了,故障转移的一个主要问题和选择领头sentinel问题差不多,到底要选择哪一个slaver节点来作为master呢?按照我们一般的常识,我们会认为哪个slave节点中的数据和master中的数据相识度高哪个slaver就是master了,其实哨兵模式也差不多是这样判断的,不过还有别的判断条件,详细介绍如下:
- 在进行选择之前需要先剔除掉一些不满足条件的slaver,这些slaver不会作为变成master的备选;
- 剔除列表中已经下线的从服务
- 剔除有5s没有回复sentinel的info命令的slave
- 剔除与已经下线的主服务连接断开时间超过 down-after-milliseconds * 10 + master宕机时长 的slaver
- 选主
- 选择优先级最高的节点,通过sentinel配置文件中的replica-priority配置项,这个参数越小,表示优先级越高
- 如果第一步中的优先级相同,选择offset最大的,offset表示主节点向从节点同步数据的偏移量,越大表示同步的数据越多
- 如果第二步offset也相同,选择run id较小的
- 故障转移,当选举出Leader Sentinel后,Leader Sentinel会对下线的主服务器执行故障转移操作,主要有三个步骤:
- 它会将失效 Master 的其中一个 Slave 升级为新的 Master,并让失效 Master的其他 Slave 改为复制新的 Master;
- 当客户端试图连接失效的 Master 时,集群也会向客户端返回新 Master 的地址,使得集群可以使用现在的 Master 替换失效 Master;
- Master 和 Slave 服务器切换后, Master 的 redis.conf 、 Slave 的 redis.conf 和sentinel.conf 的配置文件的内容都会发生相应的改变,即, Master 主服务器的 redis.conf配置文件中会多一行 replicaof 的配置, sentinel.conf 的监控目标会随之调换。
3.4 总结哨兵
优点
- 哨兵模式是基于主从模式的,所以,主从有的优点,哨兵模式都具有,哨兵只是在它的基础上加了哨兵集群
- 主从可以自动切换,系统更健壮,可用性更高。
缺点
- 具有主从模式的缺点,每台机器上的数据是一样的,内存的可用性较低。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
四、集群模式
4.1 介绍
1、集群模式介绍
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在 redis3.0 上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,对数据进行分片,也就是说每台 Redis 节点上存储不同的内容;
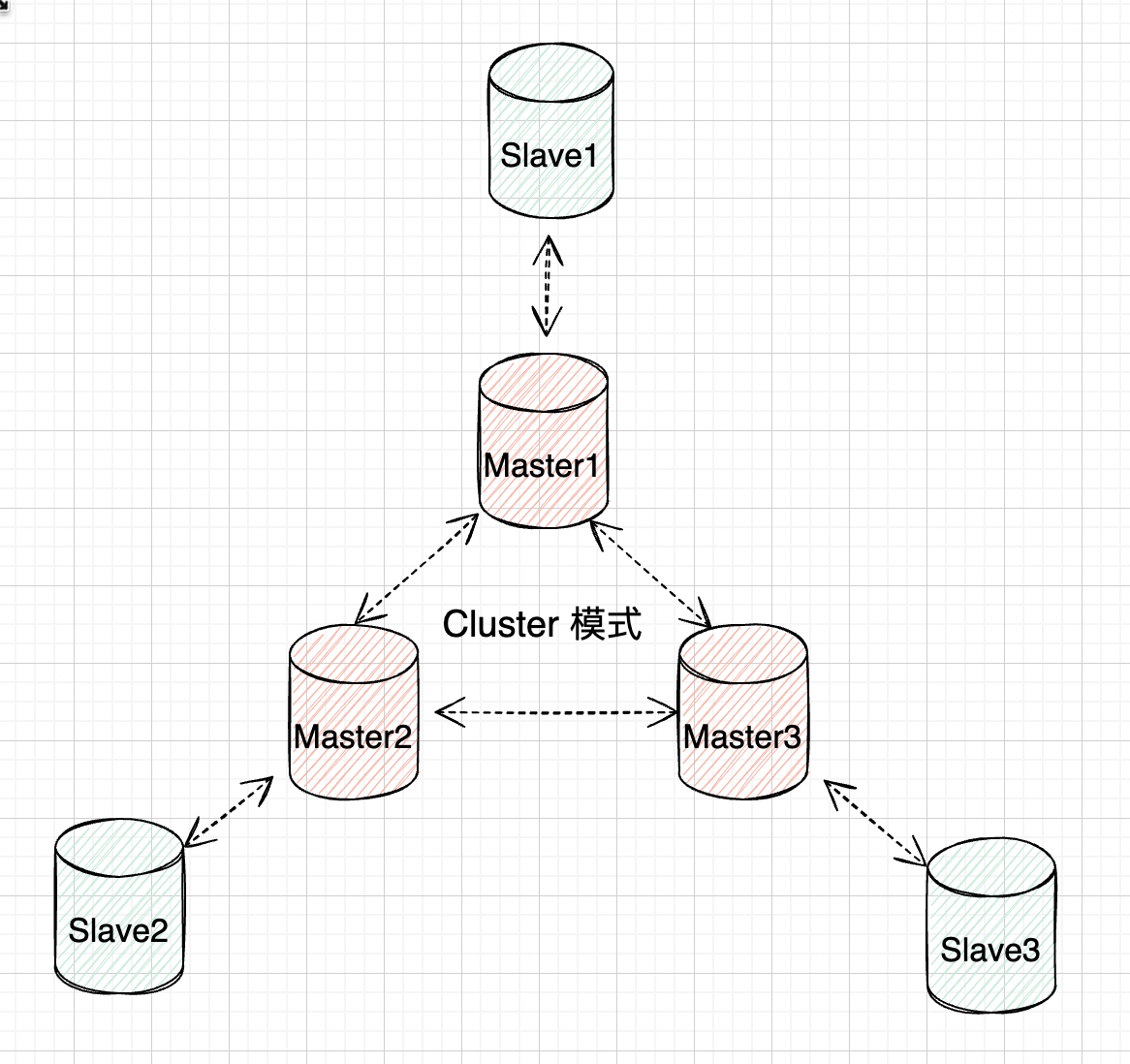
2、集群模式工作原理
Cluster模式是Redis的一种高级集群模式,它通过数据分片和分布式存储实现了负载均衡和高可用性。在Cluster模式下,Redis将所有的键值对数据分散在多个节点上。每个节点负责一部分数据,称为槽位。通过对数据的分片,Cluster模式可以突破单节点的内存限制,实现更大规模的数据存储。
3、数据分片与槽位
Redis Cluster将数据分为16384个槽位,每个节点负责管理一部分槽位。当客户端向Redis Cluster发送请求时,Cluster会根据键的哈希值将请求路由到相应的节点。具体来说,Redis Cluster使用CRC16算法计算键的哈希值,然后对16384取模,得到槽位编号。
4、主负责读写和写,从库只负责备份
在redis的官方文档中,对redis-cluster架构上,有这样的说明:在cluster架构下,默认的,一般redis-master用于接收读写,而redis-slave则用于备份,当有请求是在向slave发起时,会直接重定向到对应key所在的master来处理
5、客户端程序如何链接redis集群?
对客户端来说,整个 cluster 被看做是一个整体,客户端可以连接任意一个 node 进行操作,接入任何一个实例就相当于接入了整个集群,就像操作单一 Redis 实例一样,当客户端操作的 key 没有分配到该 node 上时,Redis 会返回转向指令,指向正确的 node,这有点儿像浏览器页面的 302 redirect 跳转。
4.2 配置示例
根据官方推荐,集群部署至少要 3 台以上的 master 节点,最好使用 3 主 3 从六个节点的模式
找六台机器
| 机器名称 | IP | 端口 |
|---|---|---|
| master1 | 192.168.71.11 | 6379 |
| master2 | 192.168.71.12 | 6379 |
| master3 | 192.168.71.13 | 6379 |
| slave1 | 192.168.71.14 | 6379 |
| slave2 | 192.168.71.16 | 6379 |
| slave3 | 192.168.71.17 | 6379 |
所有节点
setenforce 0
systemctl stop firewalld
yum install redis -y一、开启集群模式:每台机器均配置如下
daemonize yes
bind 0.0.0.0
protected-mode no
# 开启集群模式
cluster-enabled yes
# 节点超时时间
cluster-node-timeout 15000二、创建集群:
6 个 Redis 服务分别启动成功之后,这时虽然配置了集群开启,但是这六台机器还是独立的。使用集群管理命令将这 6 台机器添加到一个集群中。
redis-cli --cluster create 192.168.71.11:6379 192.168.71.12:6379 192.168.71.13:6379 192.168.71.14:6379 192.168.71.16:6379 192.168.71.17:6379 --cluster-replicas 1cluster-replicas 表示从节点的数量,1代表每个主节点都有一个从节点。执行完成后自动生成配置的 redis-cluster.conf 文件。
[root@m01 ~]# redis-cli --cluster create 192.168.71.11:6379 192.168.71.12:6379 192.168.71.13:6379 192.168.71.14:6379 192.168.71.16:6379 192.168.71.17:6379 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.71.16:6379 to 192.168.71.11:6379
Adding replica 192.168.71.17:6379 to 192.168.71.12:6379
Adding replica 192.168.71.14:6379 to 192.168.71.13:6379
M: 32a7c50944fd31015d2e7e8a94db88bc9634501c 192.168.71.11:6379
slots:[0-5460] (5461 slots) master
M: d079093147721a0a9913ae0f8f952642f18c18b0 192.168.71.12:6379
slots:[5461-10922] (5462 slots) master
M: 62dec14d2669b0cd4cf73452b5bd6927f246fbee 192.168.71.13:6379
slots:[10923-16383] (5461 slots) master
S: 62226042b257b0454ea06f10bf98883b2b887af8 192.168.71.14:6379
replicates 62dec14d2669b0cd4cf73452b5bd6927f246fbee
S: 83e27af0d92efc5038817e11e25ab24f86b3e4c1 192.168.71.16:6379
replicates 32a7c50944fd31015d2e7e8a94db88bc9634501c
S: 48ec8a2732594980fe13a77bca502d8ffa6803b8 192.168.71.17:6379
replicates d079093147721a0a9913ae0f8f952642f18c18b0
Can I set the above configuration? (type 'yes' to accept): yes # 输入yes,接受上面配置
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 192.168.71.11:6379)
M: 32a7c50944fd31015d2e7e8a94db88bc9634501c 192.168.71.11:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 48ec8a2732594980fe13a77bca502d8ffa6803b8 192.168.71.17:6379
slots: (0 slots) slave
replicates d079093147721a0a9913ae0f8f952642f18c18b0
M: 62dec14d2669b0cd4cf73452b5bd6927f246fbee 192.168.71.13:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: d079093147721a0a9913ae0f8f952642f18c18b0 192.168.71.12:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 83e27af0d92efc5038817e11e25ab24f86b3e4c1 192.168.71.16:6379
slots: (0 slots) slave
replicates 32a7c50944fd31015d2e7e8a94db88bc9634501c
S: 62226042b257b0454ea06f10bf98883b2b887af8 192.168.71.14:6379
slots: (0 slots) slave
replicates 62dec14d2669b0cd4cf73452b5bd6927f246fbee
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
三、测试验证
# 1、登录集群:选择任一节点
redis-cli -c -h 192.168.71.12 -p 6379 # -c,使用集群方式登录,有密码的话就在加上参数-a 123456
# 2、查看集群信息
CLUSTER INFO # 查看集群信息:
CLUSTER NODES # 列出节点信息
# 3、添加与查询(读写操作都会定向到master库上,不可能跑到从库上,因为从库只负责备份)
[root@m01 ~]# redis-cli -c -h 192.168.71.17 -p 6379
192.168.71.17:6379>
192.168.71.12:6379> set age 18
-> Redirected to slot [741] located at 192.168.71.11:6379
OK
[root@m01 ~]# redis-cli -c -h 192.168.71.13 -p 6379
192.168.71.13:6379>
192.168.71.13:6379> keys *
(empty array)
192.168.71.13:6379>
192.168.71.13:6379> get age
-> Redirected to slot [741] located at 192.168.71.11:6379
"18"
192.168.71.11:6379>
4.3 原理
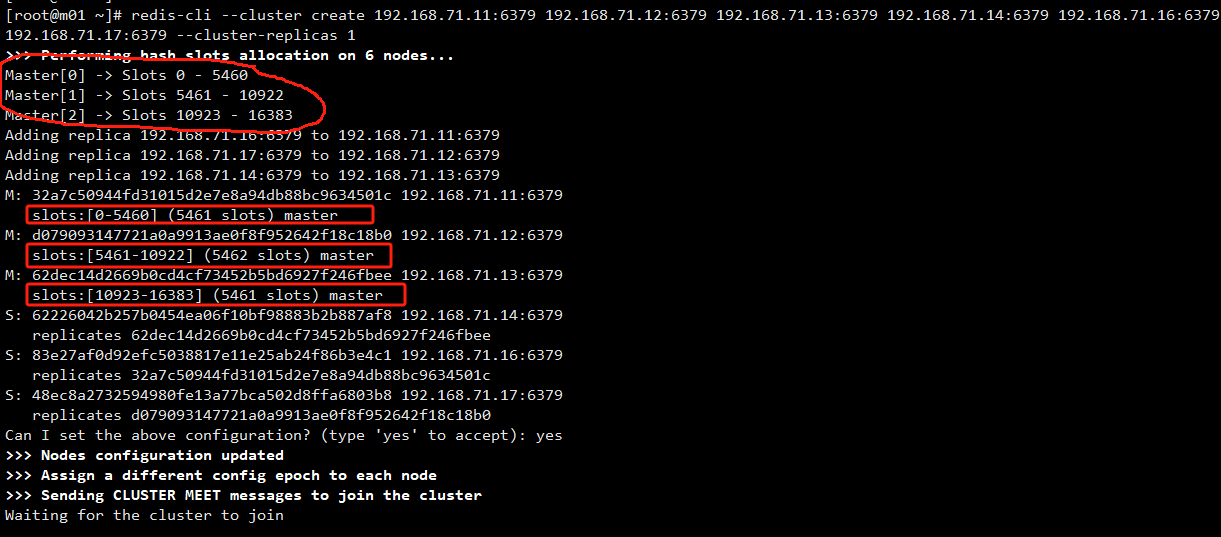
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383,可以从上面redis-trib.rb执行的结果看到这 16383 个 slot 在三个 master 上的分布。还有一个就是 cluster,可以理解为是一个集群管理的插件,类似的哨兵。
当我们的存取的 Key 到达的时候,Redis 会根据 crc16 的算法对计算后得出一个结果,然后把结果和 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
当数据写入到对应的 master 节点后,这个数据会同步给这个 master 对应的所有 slave 节点。
为了保证高可用,redis-cluster 集群引入了主从模式,一个主节点对应一个或者多个从节点。当其它主节点 ping 主节点 master 1 时,如果半数以上的主节点与 master 1 通信超时,那么认为 master 1 宕机了,就会启用 master 1 的从节点 slave 1,将 slave 1 变成主节点继续提供服务。
如果 master 1 和它的从节点 slave 1 都宕机了,整个集群就会进入 fail 状态,因为集群的 slot 映射不完整。如果集群超过半数以上的 master 挂掉,无论是否有 slave,集群都会进入 fail 状态。
redis-cluster 采用去中心化的思想,没有中心节点的说法,客户端与 Redis 节点直连,不需要中间代理层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4.4 总结
优点:
1)集群完全去中心化,采用多主多从;自动化故障转移
2)省去了中间商,简化了使用,提升了效率
客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
每一个master节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个node都知道具体数据存储到哪个node上
缺点:
- 1.集群内部的通信会消耗大量带宽:Redis Cluster 是无中心节点的集群架构,依靠 Goss 协议(谣言传播)协同自动化修复集群的状态
但 GosSIp 有消息延时和消息冗余的问题,在集群节点数量过多的时候,节点之间需要不断进行 PING/PANG 通讯(所有的redis节点彼此互联基于PING-PONG机制),这些额外的流量占用了大量的网络资源。虽然 Reds4.0 对此进行了优化内部使用二进制协议优化传输速度和带宽(内部使用二进制协议优化传输速度和带宽),但这个问题仍然存在。 - 2.复杂性:相比于单实例部署,Cluster配置和日常管理更为复杂,需要更多的维护工作。