prometheus监控介绍
一、什么是监控
监控===监测+控制
生活中的监控:事故追责
运维中的监控:事后追责,事前预警,性能分析,实时报警二、为什么要监控
监控是整个产品周期中最重要的一环,及时预警减少故障避免影响扩大,根据历史数据可以追溯问题根源,并且分析监控数据,可以找出用户体验优化方案。
随着用户的增多,服务随时可能会被系统oom(out of memory内存溢出)
后果:kill -9 mysql
如何判断?,web服务是因为用户访问过多,达到了瓶颈? 还是程序代码bug导致的,内存过多?
上线一个新网站:压力测试 2000并发,oom(out of memeory)三、监控类型
按照层次划分可简单分为:
应用层:nginx,mysql,java。。
运行层:Windows,linux。。
硬件层:内存,cpu,磁盘,网络。。四、linux常见监控方式
1、命令
cpu、内存、磁盘、网络
1.top 系统时间 登录用户 负载 进程 cpu 内存 swap 进程详细信息
2.htop(eple) 系统时间 登录用户 负载 进程 cpu 内存 swap 进程详细信息 支持鼠标 树状 快捷键
3.uptime 当前系统时间、登录用户、负载
4.free 监控内存
5.vmstat 程、虚存、页面交换空间及 CPU
5.iostat 磁盘I/O统计
6.df 硬盘 -h block -i inode
7.iftop 流量监控工具
8.nethogs 查看进程占用的网络带宽
9.iotop 进程占用的硬盘I/O2、脚本
没有监控工具的时候,shell脚本+定时任务
[root@k8s ~]# cat mem_alter.sh
#!/bin/bash
MEM=`free -m|awk 'NR==2{print $NF}'`
if [ $MEM -lt 100 ];then
echo "web服务器 192.168.15.1 可用内存不足,当前可用内存
$MEM" | mail -s "web服务器内存不足" 212121@qq.com
fi缺点:效率低,不能实现集中报警,不能分析历史数据
什么时候用shell:我只有一台云主机需要监控,适合shell脚本+定时任务
3、监控工具
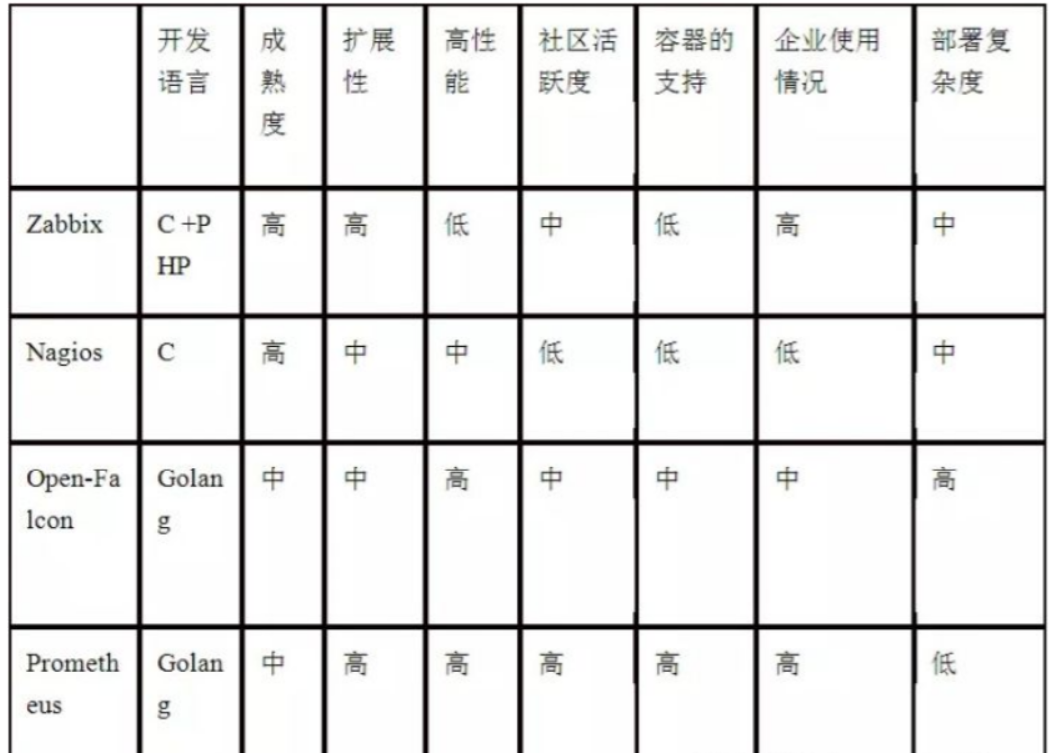
五、监控流程

六、监控指标
| 监控项目 | 监控内容 |
|---|---|
| 主机 | 内存,磁盘(使用空间/剩余空间),系统启动时间,进程数,负载等 |
| 网卡 | ping的响应时间,数据包的收发成功率,网卡的流入&流出量和错误的数据包数量 |
| 文件 | 大小,文件指纹信息等 |
| URL | 指定URL访问过程中的返回码,下载时间及文件大小等 |
| 应用程序 | 服务状态,端口和内存使用率,cpu使用率,请求数量,并发访问请求等 |
| 数据库 | 指定数据库中的表空间,数据库的游标数,会话数,事务数等 |
| 日志 | 错误日志,特定字符串匹配 |
| 硬件 | 温度,风扇转速,电压,电源,主板控制器,磁盘阵列等 |
promethus介绍
一、概述
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包 。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立于任何公司进行维护。为了强调这一点并阐明项目的治理结构,Prometheus 在2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目
Prometheus(由go语言(golang)开发)是一套开源的监控&报警&时间序列数据库的组合。
Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
prometheus和K8S一样属于CNCF
官网地址:https://prometheus.io/
github地址:https://github.com/prometheus二、工作流程
1、架构图
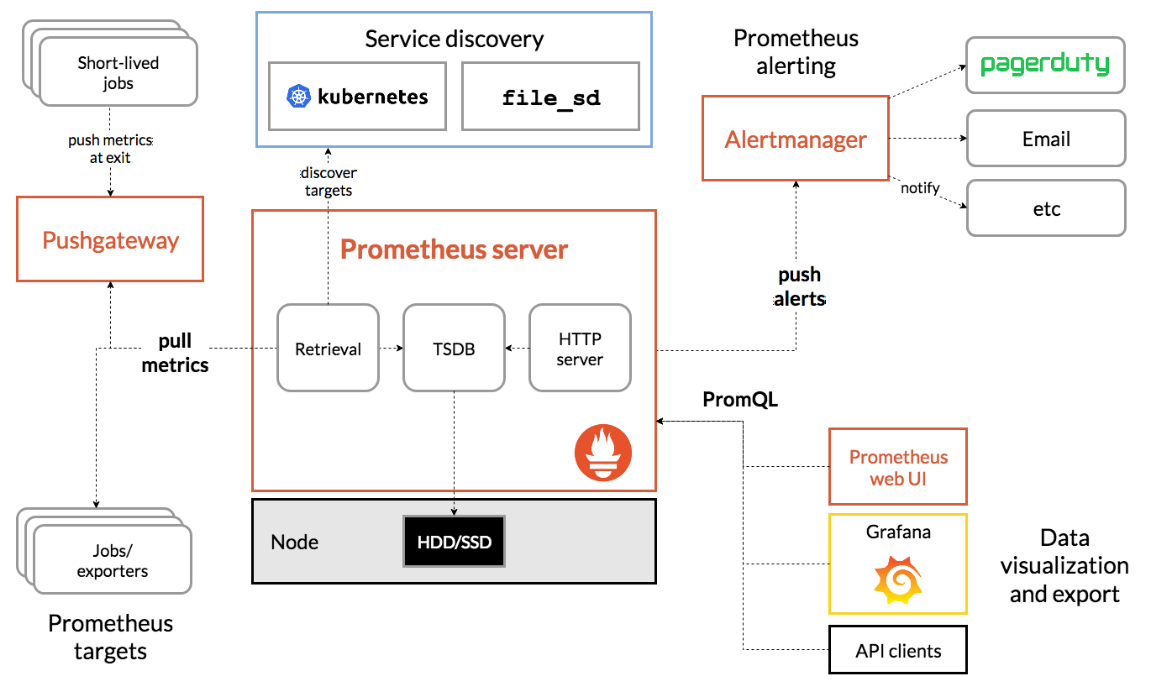
2、组件介绍
1.Prometheus Server
Retrieval
获取监控数据
TSDB:
时间序列数据库(Time Series Database),我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。具备以下特点:
大部分时间都是顺序写入操作,很少涉及修改数据
删除操作都是删除一段时间的数据,而不涉及到删除无规律数据
读操作一般都是升序或者降序
HTTP Server
为告警和出图提供查询接口2.Pull metrics 指标采集
Exporters:
Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取
用于暴露已有的第三方服务的 metrics 给 Prometheus。
Pushgateway
用于网络不可直达或者生命周期比较短的数据采集job,居于exporter与server端的中转站,将多个节点数据汇总到Push Gateway,再统一推送到server。3. service discovery 服务发现
Kubernetes_sd
支持从Kubernetes中自动发现服务和采集信息。而Zabbix监控项原型就不适合Kubernets,因为随着Pod的重启或者升级,Pod的名称是会随机变化的。
file_sd
通过配置文件来实现服务的自动发现4.Alertmanager 单独抽离的告警组件
从 Prometheus server 端接收到 alerts(告警) 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。5. 图形化展示
通过ProQL语句查询指标信息,并在页面展示。虽然Prometheus自带UI界面,但是大部分都是使用Grafana出图。另外第三方也可以通过 API 接口来获取监控指标。3、工作流程
1、Prometheus server 定期从配置好的 jobs 或者 exporters(出口) 中拉metrics(指标),或者接收来自 Pushgateway 发过来的 metrics(指标),或者从其他的 Prometheus server 中拉 metrics(指标)。
2、默认使用的拉取方式是pull,也可以使用pushgateway提供的push方式获取各个监控节点的数据。
3、将获取到的数据存入TSDB,一款时序型数据库。
4、此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。
5、它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。
6、prometheus原生的图标功能过于简单,可将prometheus数据接入grafana,由grafana进行统一管理。三、promethus的优缺点及特点
1、优点
1、非常少的外部依赖,安装使用超简单
2、已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等
3、服务自动化发现
4、直接集成到代码
5、设计思想是按照分布式、微服务架构来实现的2、特点
1、一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据
2、PromQL,一种灵活的查询语言 ,可利用此维度
3、不依赖分布式存储;单服务器节点是自治的
4、时间序列收集通过HTTP上的拉模型进行
5、通过中间网关支持推送时间序列
6、通过服务发现或静态配置发现目标
7、多种图形和仪表板支持模式3、不足
1、Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
2、Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
3、对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos 等方案。
4、监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
5、Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。