
1、什么是k8s?
Kubenetes是一个针对容器应用,进行自动部署,弹性伸缩和管理的开源系统。主要功能是生产环境中的容器编排。
K8S是Google公司推出的,它来源于由Google公司内部使用了15年的Borg系统,集结了Borg的精华。
k8s是一个docker集群的管理工具
k8s是容器的编排工具2、k8s的核心功能
1.自愈
自愈: 重新启动失败的容器,在节点不可用时,替换和重新调度节点上的容器,对用户定义的健康检查不响应的容器会被中止,并且在容器准备好服务之前不会把其向客户端广播。2.弹性伸缩
通过监控容器的cpu的负载值,如果这个平均高于80%,增加容器的数量,如果这个平均低于10%,减少容器的数量3.服务的自动发现和负载均衡
不需要修改您的应用程序来使用不熟悉的服务发现机制,Kubernetes 为容器提供了自己的 IP 地址和一组容器的单个 DNS 名称,并可以在它们之间进行负载均衡。4.滚动升级和一键回滚
Kubernetes 逐渐部署对应用程序或其配置的更改,同时监视应用程序运行状况,以确保它不会同时终止所有实例。 如果出现问题,Kubernetes会为您恢复更改,利用日益增长的部署解决方案的生态系统。5.私密配置文件管理
web容器里面,数据库的账户密码(测试库密码)3、k8s的组成?
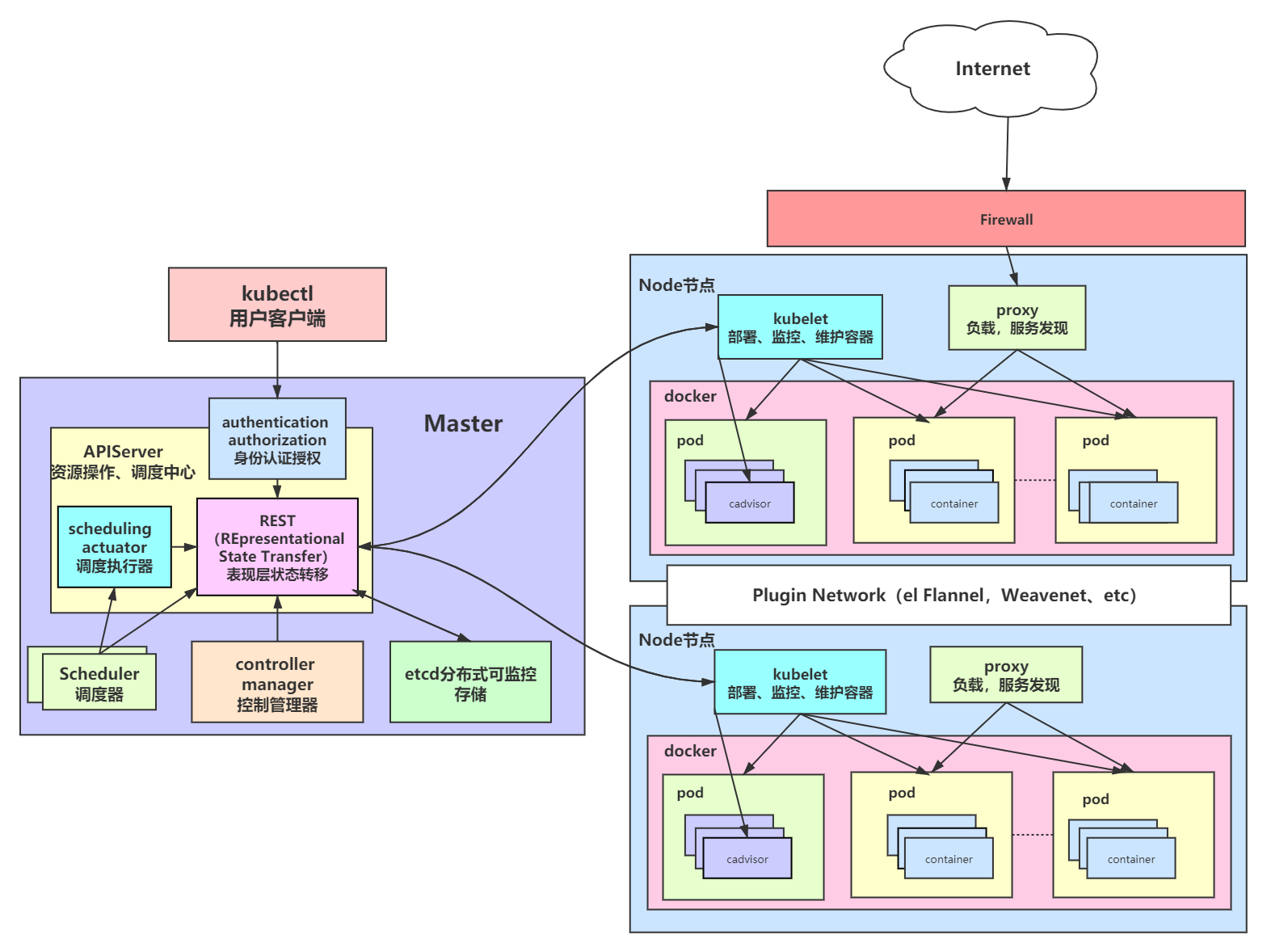
1.Master节点(默认不参加工作)
Kubectl:
客户端命令行工具,作为整个K8s集群的操作入口;
Api Server:
在K8s架构中承担的是“桥梁”的角色,作为资源操作的唯一入口,它提供了认证、授权、访问控制、API注册和发现等机制。客户端与k8s群集及K8s内部组件的通信,都要通过Api Server这个组件;
Controller-manager:
负责维护群集的状态,比如故障检测、自动扩展、滚动更新等
Scheduler:
负责资源的调度,按照预定的调度策略将pod调度到相应的node节点上;Etcd(可以不在master节点):担任数据中心的角色,保存了整个群集的状态;
2.Node节点
Kubelet:
负责维护容器的生命周期,同时也负责Volume和网络的管理,一般运行在所有的节点,是Node节点的代理,当Scheduler确定某个node上运行pod之后,会将pod的具体信息(image,volume)等发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向master返回运行状态。(自动修复功能:如果某个节点中的容器宕机,它会尝试重启该容器,若重启无效,则会将该pod杀死,然后重新创建一个容器);
Kube-proxy:
Service在逻辑上代表了后端的多个pod。负责为Service提供cluster内部的服务发现和负载均衡(外界通过Service访问pod提供的服务时,Service接收到的请求后就是通过kube-proxy来转发到pod上的);
container-runtime:
是负责管理运行容器的软件,比如docker3.扩展组件
| 组件名称 | 说明 |
|---|---|
| kube-dns | 负责为整个集群提供DNS服务 |
| Ingress Controller | 为服务提供外网入口 |
| Heapster | 提供资源监控 |
| Dashboard | 提供GUI |
| Federation | 提供跨可用区的集群 |
| Fluentd-elasticsearch | 提供集群日志采集、存储与查询 |
| flannel | 提供集群间的网络 |
4、说出对fannel的了解
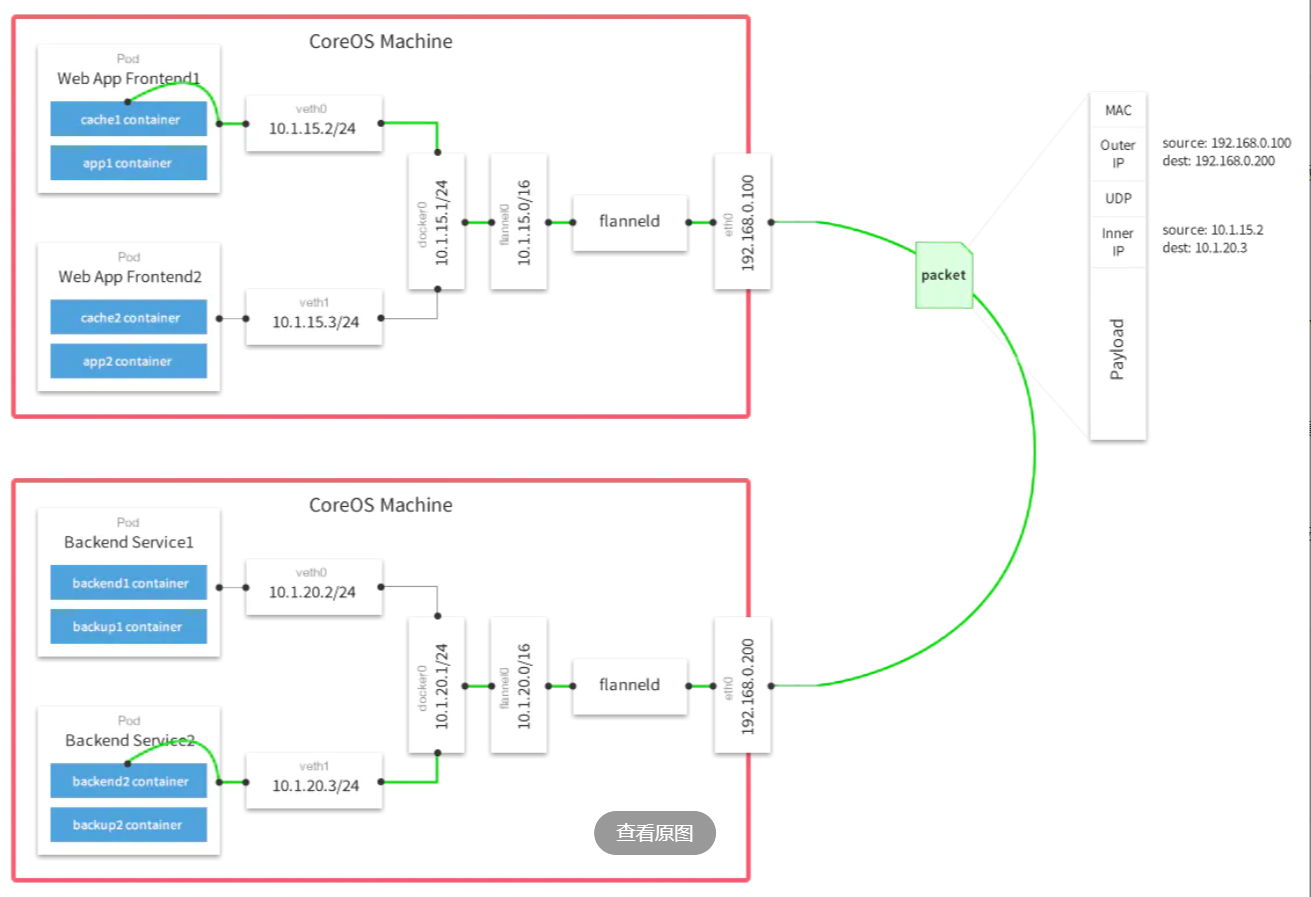
1.功能
让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。但在默认的Docker配置中,每个Node的Docker服务会分别负责所在节点容器的IP分配。Node内部得容器之间可以相互访问,但是跨主机(Node)网络相互间是不能通信。Flannel设计目的就是为集群中所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得"同属一个内网"且"不重复的"IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。2.原理
Flannel 使用etcd存储配置数据和子网分配信息。flannel 启动之后,后台进程首先检索配置和正在使用的子网列表,然后选择一个可用的子网,然后尝试去注册它。etcd也存储这个每个主机对应的ip。flannel 使用etcd的watch机制监视/coreos.com/network/subnets下面所有元素的变化信息,并且根据它来维护一个路由表。为了提高性能,flannel优化了Universal TAP/TUN设备,对TUN和UDP之间的ip分片做了代理。3.工作流程
1、数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
2、Flannel通过Etcd服务维护了一张节点间的路由表,该张表里保存了各个节点主机的子网网段信息。
3、源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一样的由docker0路由到达目标容器。5、说一下你对fannel和calico了解及区别?
Flannel
由CoreOS开发的项目Flannel,可能是最直接和最受欢迎的CNI插件。它是容器编排系统中最成熟的网络结构示例之一,旨在实现更好的容器间和主机间网络。随着CNI概念的兴起,Flannel CNI插件算是早期的入门。1)安装简单,不需要专门的数据存储
Flannel相对容易安装和配置。它被打包为单个二进制文件flanneld,许多常见的Kubernetes集群部署工具和许多Kubernetes发行版都可以默认安装Flannel。Flannel可以使用Kubernetes集群的现有etcd集群来使用API存储其状态信息,因此不需要专用的数据存储。 Flannel配置第3层IPv4 overlay网络。它会创建一个大型内部网络,跨越集群中每个节点。在此overlay网络中,每个节点都有一个子网,用于在内部分配IP地址。在配置pod时,每个节点上的Docker桥接口都会为每个新容器分配一个地址。同一主机中的Pod可以使用Docker桥接进行通信,而不同主机上的pod会使用flanneld将其流量封装在UDP数据包中,以便路由到适当的目标。 Flannel有几种不同类型的后端可用于封装和路由。默认和推荐的方法是使用VXLAN,因为VXLAN性能更良好并且需要的手动干预更少。 总的来说,Flannel是大多数用户的不错选择。从管理角度来看,它提供了一个简单的网络模型,用户只需要一些基础知识,就可以设置适合大多数用例的环境。一般来说,在初期使用Flannel是一个稳妥安全的选择,直到你开始需要一些它无法提供的东西。Calico
1)功能全面、灵活性高。
Calico是Kubernetes生态系统中另一种流行的网络选择。虽然Flannel被公认为是最简单的选择,但Calico以其性能、灵活性而闻名。Calico的功能更为全面,不仅提供主机和pod之间的网络连接,还涉及网络安全和管理。Calico CNI插件在CNI框架内封装了Calico的功能。2)不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
它创建的网络环境具有简单和复杂的属性。与Flannel不同,Calico不使用overlay网络。相反,Calico配置第3层网络,该网络使用BGP路由协议在主机之间路由数据包。这意味着在主机之间移动时,不需要将数据包包装在额外的封装层中。BGP路由机制可以本地引导数据包,而无需额外在流量层中打包流量。3)有标准的调试工具,方便排错
除了性能优势之外,在出现网络问题时,用户还可以用更常规的方法进行故障排除。虽然使用VXLAN等技术进行封装也是一个不错的解决方案,但该过程处理数据包的方式同场难以追踪。使用Calico,标准调试工具可以访问与简单环境中相同的信息,从而使更多开发人员和管理员更容易理解行为。总结
两者都属于k8s网络插件。我们公司使用的是flannel, calico性能更好也更灵活,但是flannel更加简单好用,当公司由二次开发kubernetes的场景时,建议使用calico,当有IPV6使用场景时,必须使用calico。6、kubectl这个命令执行的过程?(以部署nginx服务为例)
1、kubectl发送了一个部署nginx的任务
2、进入Master节点,进行安全认证,
3、认证通过后,APIserver接受指令
4、将部署的命令数据记录到etcd中
5、APIserver再读取etcd中的命令数据
6、APIserver找到scheduler(调度器),说要部署nginx
7、scheduler(调度器)找APIserver调取工作节点数据。
8、APIserver调取etcd中存储的数据,并将数据发给scheduler。
9、scheduler通过计算,比较找到适合部署nginx的最佳节点是node1,发送给APIserver。
10、APIserver将要部署在node1的计划存储到etcd中。
11、APIserver读取etcd中的部署计划,通知node1节点的kubelet部署容器
12、kubelet根据指令部署nginx容器,kube-proxy为nginx容器创建网桥
13、容器网桥部署完成后,kubelet通知APIserver部署工作完成。
14、APIserver将部署状态存储到etcd当中,同时通知controller manager(控制器)有新活了
15、controller manager向APIserver要需要监控容器的数据
16、APIserver找etcd读取相应数据,同时通知kubelet要源源不断发送监控的数据
17、APIserver将kubelet发送来的数据存储到etcd当中
18、APIserver将etcd的数据返回给controller manager
19、controller manager根据数据计算判断容器是否存在或健康7、容器和主机部署应用的区别是什么?
容器的中心思想就是秒级启动;一次封装、到处运行;这是主机部署应用无法达到的效果,但同时也更应该注重容器的数据持久化问题。
另外,容器部署可以将各个服务进行隔离,互不影响,这也是容器的另一个核心概念。8、说一下pod的生命周期?
1、启动包括初始化容器的任何容器之前先创建pause基础容器,它初始化Pod环境并为后续加入的容器提供共享的名称空间。
2、按顺序以串行的方式运行用户定义的各个初始化容器进行Pod环境初始化;任何一个初始化容器运行失败都将导致Pod创建失败,并按其restartPolicy的策略进行处理,默认为重启。
3、等待所有容器初始化成功完成后,启动业务容器,多容器Pod环境中,此步骤会并行启动所有业务容器。他们各自按其自定义展开其生命周期;容器启动的那一刻会同时运行业务容器上定义的PostStart钩子事件,该步骤失败将导致相关容器被重启。
4、运行容器启动健康状态监测(startupProbe),判断容器是否启动成功;该步骤失败,同样参照restartPolicy定义的策略进行处理;未定义时,默认状态为Success。
5、容器启动成功后,定期进行存活状态监测(liveness)和就绪状态监测(readiness);存活监测状态失败将导致容器重启,而就绪状态监测失败会是的该容器从其所属的Service对象的可用端点列表中移除。
6、终止Pod对象时,会想运行preStop钩子事件,并在宽限期(termiunationGracePeriodSeconds)结束后终止主容器,宽限期默认为30秒。
#简述
1、创建pod,并调度到合适节点
2、创建pause基础容器,提供共享名称空间
3、串行业务容器容器初始化
4、启动业务容器,启动那一刻会同时运行主容器上定义的Poststart钩子事件
5、健康状态监测,判断容器是否启动成功
6、持续存活状态监测、就绪状态监测
7、结束时,执行prestop钩子事件
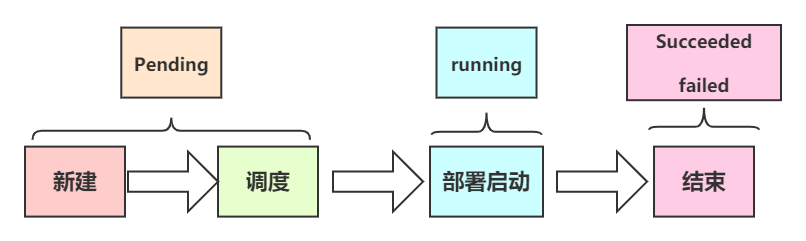
8、终止容器9、描述一下pod的生命周期有哪些状态?
Pending:表示pod已经被同意创建,正在等待kube-scheduler选择合适的节点创建,一般是在准备镜像;
Running:表示pod中所有的容器已经被创建,并且至少有一个容器正在运行或者是正在启动或者是正在重启;
Succeeded:表示所有容器已经成功终止,并且不会再启动;
Failed:表示pod中所有容器都是非0(不正常)状态退出;
Unknown:表示无法读取Pod状态,通常是kube-controller-manager无法与Pod通信。10、说一下PostStart、PreStop钩子?
PostStart :在容器创建后立即执行。但是,并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。 主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费时间过长以及于不能运行或者挂起,容器将不能达到Running状态。
容器启动后执行,注意由于是异步执行,它无法保证一定在ENTRYPOINT之后运行。如果失败,容器会被杀死,并根据RestartPolicy决定是否重启
PreStop :在容器终止前立即被调用。它是阻塞的,意味着它是同步的,所以它必须在删除容器的调用出发之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起,Pod阶段将停留在Running状态并且不会达到failed状态
容器停止前执行,常用于资源清理。如果失败,容器同样也会被杀死11、请你说一下kubenetes针对pod资源对象的健康监测机制,以及三种检查方式?
1.livenessProbe探针(检查是否存活)
可以根据用户自定义规则来判定pod是否健康,如果livenessProbe探针探测到容器不健康,则kubelet会根据其重启策略来决定是否重启,如果一个容器不包含livenessProbe探针,则kubelet会认为容器的livenessProbe探针的返回值永远成功。