文件管理之(高级)
一 文本处理三剑客命令初探
三剑客命令我们将在shell编程里深入讲解,此处先学会最基本的使用
1.1 sed
流式编辑器,主要擅长对文件的编辑操作,我们可以事先定制好编辑文件的指令,然后让sed自动完成对文件的整体编辑
# 用法
sed 选项 '定位+命令' 文件路径
# 选项
-n 取消默认输出
-r 支持扩展正则元字符(由于尚未学习正则,所以此处暂作了解,正则表达式将会在shell编程第九章第一节介绍)
-i 立即编辑文件
# 定位
行定位:
1定位到第一行
1,3代表从第1行到第3行
不写定位代表定位所有行
正则表达式定位:
/egon/ 包含egon的行
/^egon/ 以egon开头的行
/egon$/以egon结尾的行
数字+正则表达式定位
"1,8p"代表打印1到8行,
"1,/egon/p"则代表取从第1行到首次匹配到/egon/的行
# 命令
d
p
s///g
命令可以用;号连接多多条,如1d;3d;5d代表删除1,3,5行
# =========================》用法示例:p与d
[root@localhost ~]# sed '' a.txt
egon1111
22222egon
3333egon33333
4444xxx44444
5555xxx55555xxxx555xxx
6666egon6666egon666egon
[root@localhost ~]# sed -n '' a.txt
[root@localhost ~]#
[root@localhost ~]# sed -n '1,/xxx/p' a.txt
egon1111
22222egon
3333egon33333
4444xxx44444
[root@localhost ~]# sed '1,/xxx/d' a.txt
5555xxx55555xxxx555xxx
6666egon6666egon666egon
[root@localhost ~]# sed '1d;3d;5d' a.txt
22222egon
4444xxx44444
6666egon6666egon666egon
# =========================》用法示例: s///g
[root@localhost ~]# cat a.txt
egon1111
22222egon
3333egon33333
4444xxx44444
5555xxx55555xxxx555xxx
6666egon6666egon666egon
[root@localhost ~]# sed 's/egon/BIGEGON/g' a.txt # 把所有行的所有的egon都换成BIGEGON
BIGEGON1111
22222BIGEGON
3333BIGEGON33333
4444xxx44444
5555xxx55555xxxx555xxx
6666BIGEGON6666BIGEGON666BIGEGON
[root@localhost ~]#
[root@localhost ~]# sed '/^egon/s/egon/GAGAGA/g' a.txt # 以egon开头的行中的egon换成GAGAGA
GAGAGA1111
22222egon
3333egon33333
4444xxx44444
5555xxx55555xxxx555xxx
6666egon6666egon666egon
[root@localhost ~]# sed '6s/egon/BIGEGON/' a.txt # 只把第6行的egon换成BIGEGON,加上g代表???
egon1111
22222egon
3333egon33333
4444xxx44444
5555xxx55555xxxx555xxx
6666BIGEGON6666egon666egon
[root@localhost ~]#
[root@localhost ~]# sed '1,3s/egon/BIGEGON/g' a.txt # 把1到3行的egon换成BIGEGON
BIGEGON1111
22222BIGEGON
3333BIGEGON33333
4444xxx44444
5555xxx55555xxxx555xxx
6666egon6666egon666egon
[root@localhost ~]# cat a.txt | sed '1,5d' # sed也支持管道
6666egon6666egon666egon
# 加上-i选项,直接修改文件,通常会在调试完毕确保没有问题后再加-i选项1.2 awk
awk主要用于处理有格式的文本,例如/etc/passwd这种
# 用法
awk 选项 'pattern{action}' 文件路径
# 选项
-F 指定行分隔符
# 工作流程
awk -F: '{print $1,$3}' /etc/passwd
1、awk会读取文件的一行内容然后赋值给$0
2、然后awk会以-F指定的分隔符将该行切分成n段,最多可以达到100段,第一段给$1,第二段给$2,依次次类推
3、print输出该行的第一段和第三段,逗号代表输出分隔符,默认与-F保持一致
4、重复步骤1,2,3直到文件内容读完
# 内置变量
$0 一整行内容
NR 记录号,等同于行号
NF 以-F分隔符分隔的段数
# pattern可以是
/正则/
/正则/ # 该行内容匹配成功正则
$1 ~ /正则/ # 第一段内容匹配成功正则
$1 !~ /正则/ # 第一段内容没有匹配成功正则
比较运算:
NR >= 3 && NR <=5 # 3到5行
$1 == "root" # 第一段内容等于root
# action可以是
print $1,$3
# 用法示例
[root@localhost ~]# cat a.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost ~]# awk -F: '/^root/{print $1,$3}' a.txt
root 0
[root@localhost ~]# awk -F: '$1 ~ /^d/{print $1,$3}' a.txt
daemon 2
[root@localhost ~]# awk -F: '$1 !~ /^d/{print $1,$3}' a.txt
root 0
bin 1
adm 3
lp 4
[root@localhost ~]# awk -F: 'NR>3{print $1}' a.txt
adm
lp
[root@localhost ~]# awk -F: '$1 == "lp"{print $0}' a.txt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost ~]#
[root@localhost ~]# cat a.txt | awk -F: '{print $1}' # awk也支持管道
root
bin
daemon
adm
lp
[root@localhost ~]# 事实上awk是一门编程语言,可以独立完成很强大的操作,我们将在shell编程中详细介绍
1.3 grep
grep擅长过滤内容
# 用法
grep 选项 '正则' 文件路径
# 选项
-n, --line-number 在过滤出的每一行前面加上它在文件中的相对行号
-i, --ignore-case 忽略大小写
--color 颜色
-l, --files-with-matches 如果匹配成功,则只将文件名打印出来,失败则不打印
通常-rl一起用,grep -rl 'root' /etc
-R, -r, --recursive 递归
# 示例
[root@localhost ~]# grep '^root' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# grep -n 'bash$' /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
44:egon:x:1000:1000:egon:/home/egon:/bin/bash
[root@localhost ~]# grep -rl 'root' /etc
# grep也支持管道,我们可以发现三剑客命令都支持管道
[root@localhost ~]# ps aux |grep ssh
root 968 0.0 0.2 112908 4312 ? Ss 14:05 0:00 /usr/sbin/sshd -D
root 1305 0.0 0.3 163604 6096 ? Ss 14:05 0:00 sshd: root@pts/0
root 1406 0.0 0.3 163600 6240 ? Ss 14:05 0:00 sshd: root@pts/1
root 2308 0.0 0.0 112724 984 pts/1 R+ 15:30 0:00 grep --color=auto ssh
[root@localhost ~]# ps aux |grep [s]sh
root 968 0.0 0.2 112908 4312 ? Ss 14:05 0:00 /usr/sbin/sshd -D
root 1305 0.0 0.3 163604 6096 ? Ss 14:05 0:00 sshd: root@pts/0
root 1406 0.0 0.3 163600 6240 ? Ss 14:05 0:00 sshd: root@pts/1二 文件管理之:文件查找
一、查看命令所属文件
[root@localhost ~]# which ip
/usr/sbin/ip
# ps: 一些命令的路径都被配置到了环境变量PATH里
echo $PATH二、查找文件
find [options] [path...] [expression]按文件名:
[root@localhost ~]# find /etc -name "ifcfg-eth0"
[root@localhost ~]# find /etc -iname "ifcfg-eth0" # -i忽略大小写
[root@localhost ~]# find /etc -iname "ifcfg-eth*"按文件大小:
[root@localhost ~]# find /etc -size +3M # 大于3M
[root@localhost ~]# find /etc -size 3M
[root@localhost ~]# find /etc -size -3M
[root@localhost ~]# find /etc -size +3M -ls # -ls找到的处理动作指定查找的目录深度:
-maxdepth levels
[root@localhost ~]# find / -maxdepth 5 -a -name "ifcfg-eth0" # -a并且,-o或者,不加-a,默认就是-a按时间找(atime,mtime,ctime):
[root@localhost ~]# find /etc -mtime +3 # 修改时间超过3天
[root@localhost ~]# find /etc -mtime 3 # 修改时间等于3天
[root@localhost ~]# find /etc -mtime -3 # 修改时间3天以内按文件属主、属组找:
[root@localhost ~]# find /home -user egon # 属主是egon的文件
[root@localhost ~]# find /home -group it # 属组是it组的文件
[root@localhost ~]# find /home -user egon -group it
[root@localhost ~]# find /home -user egon -a -group it # 同上意思一样
[root@localhost ~]# find /home -user egon -o -group it
[root@localhost ~]# find /home -nouser # 用户还存在,在/etc/passwd中删除了记录
[root@localhost ~]# find /home -nogroup # 用户还存在,在/etc/group中删除了记录
[root@localhost ~]# find /home -nouser -o -nogroup 按文件类型:
[root@localhost ~]# find /dev -type f # f普通
[root@localhost ~]# find /dev -type d # d目录
[root@localhost ~]# find /dev -type l # l链接
[root@localhost ~]# find /dev -type b # b块设备
[root@localhost ~]# find /dev -type c # c字符设备
[root@localhost ~]# find /dev -type s # s套接字
[root@localhost ~]# find /dev -type p # p管道文件根据inode号查找:-inum n
[root@localhost ~]# find / -inum 1811按文件权限:
[root@localhost ~]# find . -perm 644 -ls
[root@localhost ~]# find . -perm -644 -ls
[root@localhost ~]# find . -perm -600 -ls
[root@localhost ~]# find /sbin -perm -4000 -ls # 包含set uid
[root@localhost ~]# find /sbin -perm -2000 -ls # 包含set gid
[root@localhost ~]# find /sbin -perm -1000 -ls # 包含sticky找到后处理的动作:
-print
-ls
-delete
-exec
-ok
[root@localhost ~]# find /etc -name "ifcfg*" -print # 必须加引号
[root@localhost ~]# find /etc -name "ifcfg*" -ls
[root@localhost ~]# find /etc -name "ifcfg*" -exec cp -rvf {} /tmp \; # 非交互
[root@localhost ~]# find /etc -name "ifcfg*" -ok cp -rvf {} /tmp \; # 交互
[root@localhost ~]# find /etc -name "ifcfg*" -exec rm -rf {} \;
[root@localhost ~]# find /etc -name "ifcfg*" -delete # 同上扩展知识:find结合xargs
[root@localhost ~]# find . -name "egon*.txt" |xargs rm -rf
[root@localhost ~]# find /etc -name "ifcfg-eth0" |xargs -I {} cp -rf {} /var/tmp
[root@localhost ~]# find /test -name "ifcfg-ens33" |xargs -I {} mv {} /ttt
[root@localhost ~]# find /ttt/ -name "ifcfg*" |xargs -I {} chmod 666 {}find作业:
- 查找ifconfig命令文件的位置,用不同的方式实现
- 查找/etc/中的所有子目录(仅目录)复制到/tmp下
- 查找/etc目录复制到/var/tmp/,
将/var/tmp/etc中的所有目录设置权限777(仅目录)
将/var/tmp/etc中所有文件权限设置为666
三 文件管理之:上传与下载
(1)下载
wget命令
wget -O 本地路径 远程包链接地址 # 将远程包下载到本地,-O指定下载到哪里,可以生路-O 本地路径
# ps:如果wget下载提示无法建立SSL连接,则加上选项--no-check-certificate
wget --no-check-certificate -O 本地路径 远程包链接地址 curl命令
#curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、[ftp]等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
[root@localhost ~]# curl -o 123.png https://www.xxx.com/img/hello.png
# ps: 如果遇到下载提示无法简历SSL链接,使用-k选项或者--insecure
curl -k -o 123.png https://www.xxx.com/img/hello.png
# 下载远程脚本并直接在本地执行
# 你可以在远程在test.sh所在的文件夹下执行python3 -m http.server 8899启动一个服务,Python2则用python2 -m SimpleHTTPServer 8899
# 然后在本地执行(注意关闭防火墙与selinux)
curl -s http://192.168.71.206:8899/test.sh | bash # -s代表静默模式,会屏蔽掉curl命令本身的输出sz命令
# 系统默认没有该命令,需要下载:yum install lrzsz -y
# 将服务器上选定的文件下载/发送到本机,
[root@localhost ~]# sz bak.tar.gz(2)上传
rz命令
# 系统默认没有该命令,需要下载:yum install lrzsz -y
# 运行该命令会弹出一个文件选择窗口,从本地选择文件上传到服务器。
[root@localhost opt]# rz # 如果文件已经存,则上传失败,可以用-E选项解决
[root@localhost opt]# rz -E # -E如果目标文件名已经存在,则重命名传入文件。新文件名将添加一个点和一个数字(0..999)四 文件管理之:输出与重定向
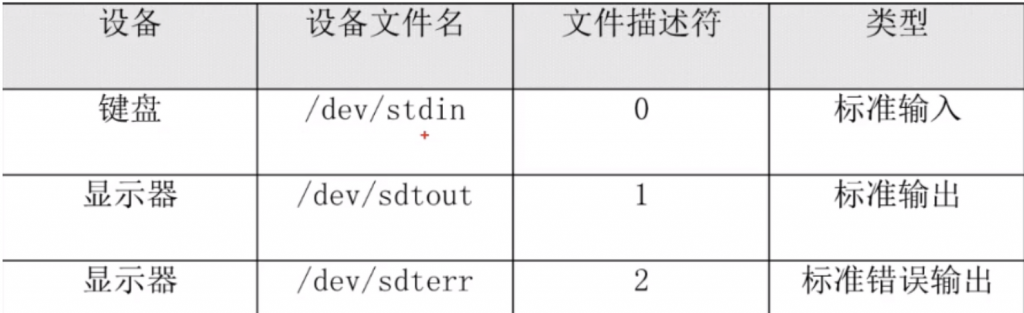
输出即把相关对象通过输出设备(显示器等)显示出来,输出又分正确输出和错误输出
一般情况下标准输出设备为显示器,标准输入设备为键盘。
linux中用
-
0代表标准输入
-
1代表标准正确输出
-
2代表标准错误输出。
输出重定向:
正常输出是把内容输出到显示器上,而输出重定向是把内容输出到文件中,>代表覆盖,>>代表追加
Ps:标准输出的1可以省略
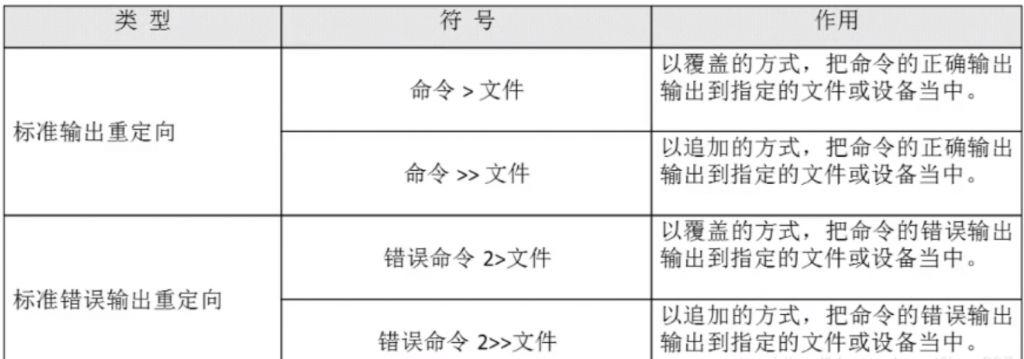
例如:ifconfig > test.log 即把ifconfig执行显示的正确内容写入test.log.当前页面不再显示执行结果。
注意:错误输出重定向>与>>后边不要加空格

注意:
-
1、下述两个命令作用相同
命令 >>file.log 2>&1 命令 &>>file.log -
2、正确日志和错误日志分开保存
命令 >>file1.log 2>>file2.log -
3、系统有个常见用法 ls &>/dev/null 正确输出或错误输出结果都不要。(null可以理解为黑洞或垃圾站)
输入重定向
#没有改变输入的方向,默认键盘,此时等待输入
[root@egon ~]# tr 'N' 'n'
No
no
[root@egon ~]# tr 'N' 'n' < file.txt
#没有改变输入的方向,默认键盘,此时等待输入
[root@egon ~]# grep 'root'
oldboy
root
root
[root@egon ~]# grep 'root' < /etc/passwd
root:x:0:0:root:/root:/bin/bash
# 读写块设备
[root@egon ~]# dd if=/dev/zero of=/file1.txt bs=1M count=20
[root@egon ~]# dd </dev/zero >/file2.txt bs=1M count=20
# mysql如何恢复备份,了解即可,不用关注。
[root@qls ~]# mysql -uroot -p123 < bbs.sql五 文件管理之:字符处理命令
5.1 sort命令
用于将文件内容加以排序
- -n # 依照数值的大小排序
- -r # 以相反的顺序来排序
- -k # 以某列进行排序
- -t # 指定分割符,默认是以空格为分隔符
准备文件,写入一段无序的内容
[root@localhost ~]# cat >> file.txt <<EOF
b:3
c:2
a:4
e:5
d:1
f:11
EOF例1
[root@localhost ~]# sort file.txt
a:4
b:3
c:2
d:1
e:5
f:11例2
[root@localhost ~]# sort -t ":" -n -k2 file.txt
d:1
c:2
b:3
a:4
e:5
f:11例3
[root@localhost ~]# sort -t ":" -n -r -k2 file.txt
f:11
e:5
a:4
b:3
c:2
d:15.2 uniq 命令
用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
- -c # 在每列旁边显示该行重复出现的次数。
- -d # 仅显示重复出现的行列。
- -u # 仅显示出一次的行列。
准备文件,写入一段无序的内容
[root@localhost ~]# cat > file.txt <<EOF
hello
123
hello
123
func
EOF例1
[root@localhost ~]# sort file.txt
123
123
func
hello
hello例2
[root@localhost ~]# sort file.txt | uniq
123
func
hello例3
[root@localhost ~]# sort file.txt | uniq -c
2 123
1 func
2 hello例4
[root@localhost ~]# sort file.txt | uniq -d
123
hello5.3 cut 命令
cut命令用来显示行中的指定部分,删除文件中指定字段
- -d # 指定字段的分隔符,默认的字段分隔符为"TAB";
- -f # 显示指定字段的内容;
[root@localhost ~]# head -1 /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# head -1 /etc/passwd | cut -d ":" -f1,3,4,6
root:0:0:/root练习:
# 筛选出当天访问ip排在前十的ip地址
cat access.log | grep `LANG="en_US.UTF-8" && date +"%d/%b/%Y"`|awk '{print $1}' |sort |uniq -c |sort -rn|awk '{print $1":"$2}' | head -10
# 筛选出固定某一天的、访问ip排在前十的ip地址
cat access.log | grep "16/Mar/2024" |awk '{print $1}' |sort |uniq -c |sort -rn|awk '{print $1":"$2}' | head -10
# 查询访问最频繁的URL
awk '{print $7}' access.log|sort | uniq -c |sort -n -k 1 -r|more
# 查询访问最频繁的IP
awk '{print $1}' access.log|sort | uniq -c |sort -n -k 1 -r|more
# 根据时间段统计查看日志
cat access.log| sed -n '/14\/Mar\/2015:21/,/14\/Mar\/2015:22/p'|more
access.log练习文件下载
链接:https://pan.baidu.com/s/1WiDO3vqGNiLhHv4vj29fUA
提取码:Egon 5.4 tr命令
替换或删除命令
- -d # 删除字符
例1
[root@localhost ~]# head -1 /etc/passwd |tr "root" "ROOT"
ROOT:x:0:0:ROOT:/ROOT:/bin/bash
[root@localhost ~]#
[root@localhost ~]# head -1 /etc/passwd |tr -d "root"
:x:0:0::/:/bin/bash例2
[root@localhost ~]# echo "hello egon qq:378533872" > a.txt
[root@localhost ~]# tr "egon" "EGON" < a.txt
hEllO EGON qq:3785338725.5 wc命令
统计,计算数字
- -c # 统计文件的Bytes数;
- -l # 统计文件的行数;
- -w # 统计文件中单词的个数,默认以空白字符做为分隔符
例1
[root@localhost ~]# ll file.txt
-rw-r--r--. 1 root root 25 8月 12 20:09 file.txt
[root@localhost ~]# wc -c file.txt
25 file.txt例2
[root@localhost ~]# cat file.txt
hello
123
hello
123
func
[root@localhost ~]# wc -l file.txt
5 file.txt
[root@localhost ~]# grep "hello" file.txt |wc -l
2例3
[root@localhost ~]# cat file.txt
hello
123
hello
123
func
[root@localhost ~]# wc -w file.txt
5 file.txt六 文件管理之:打包压缩/大文件切分
1. 什么是打包压缩
打包指的是将多个文件和目录合并为一个特殊文件
然后将该特殊文件进行压缩
最终得到一个压缩包
2. 为什么使用压缩包
1.减少占用的体积
2.加快网络的传输
3. Windows的压缩和Linux的有什么不同
windows: zip rar(linux不支持)
linux: zip tar.gz tar.bz2 .gz
如果希望windows的软件能被linux解压,或者linux的软件包被windows能识别,选择zip.
PS: 压缩包的后缀不重要,但一定要携带.
4. Linux下常见的压缩包类型
| 格式 | 压缩工具 |
|---|---|
| .zip | zip压缩工具 |
| .gz | gzip压缩工具,只能压缩文件,会删除源文件(通常配合tar使用) |
| .bz2 | bzip2压缩工具,只能压缩文件,会删除源文件(通常配合tar使用) |
| .tar.gz | 先使用tar命令归档打包,然后使用gzip压缩 |
| .tar.bz2 | 先使用tar命令归档打包,然后使用bzip压缩 |
ps:windows下支持.rar,linux不支持.rar
6、打包压缩方法
方法一:
# 1、打包
[root@localhost test]# tar cvf etc_bak.tar /etc/ # c创建 v详细 f打包后文件路径
ps:
打包的目标路径如果是绝对路径,会提示:tar: 从成员名中删除开头的“/”,不影响打包,
添加-P选项便不再提示:tar cvPf ...
可以cd 到 /etc下然后tar cvf etc_bak.tar *打包,这样去掉了一层文件夹
# 2、压缩
[root@localhost test]# gzip etc_bak.tar # 文件体积变小,并且加上后缀.gz
ps:
gzip -> gunzip
bzip2-> bunzip2
#3、上述两步可以合二为一
[root@localhost test]# tar czvf etc1_bak.tar.gz /etc/ # 选项z代表gzip压缩算法
[root@localhost test]# tar cjvf etc1_bak.tar.bz2 /etc/ # 选项j代表bzip2压缩算法方法二:
#zip压缩
选项:
-r #递归压缩 压缩目录
-q #静默输出
# 示例1、
[root@localhost ~]# zip /test/bak.zip a.txt b.txt c.txt # zip后的第一个参数是压缩包路径,其余为被压缩的文件
adding: a.txt (stored 0%)
adding: b.txt (stored 0%)
adding: c.txt (stored 0%)
[root@localhost ~]# ls /test/
bak.zip
# 示例1、
[root@localhost ~]# zip -rq etc.zip /etc # 加上-q后压缩过程不再提示7、解压缩
#1、针对xxx.tar.gz 或者 xxx.tar.bz2,统一使用
[root@localhost test]# tar xvf 压缩包 -C 解压到的目录 # 无需指定解压算法,tar会自动判断
#2、针对xxx.zip,用unzip
选项:
-l #显示压缩包的列表信息
-q #静默输出
-d #解压到指定的目录
[root@localhost test]# unzip -q xxx.zip -d /opt8 拓展
打包压缩通常用于备份文件,文件的名字必须见名知意且应该带上时间、主机名之类
时间命令date
#选项
-d #根据你的描述显示日期
-s #修改日期
%H #小时,24小时制(00~23)
%M #分钟(00~59)
%s #从1970年1月1日00:00:00到目前经历的秒数
%S #显示秒(00~59)
%T #显示时间,24小时制(hh:mm:ss)
%d #一个月的第几天(01~31)
%j #一年的第几天(001~366)
%m #月份(01~12)
%w #一个星期的第几天(0代表星期天)
%W #一年的第几个星期(00~53,星期一为第一天)
%y #年的最后两个数字(1999则是99)
%Y #年,实际
%F #显示日期(%Y-%m-%d)示例
[root@localhost ~]# date
2020年 08月 12日 星期三 20:55:48 CST
[root@localhost ~]# date +%F
2020-08-12
[root@localhost ~]# date +%Y-%m-%d
2020-08-12
[root@localhost ~]#
[root@localhost ~]# date +%y-%m-%d
20-08-12
[root@localhost ~]# date +%T
00:01:03
[root@localhost ~]# date +%H:%M:%S
00:01:11
[root@localhost ~]#
[root@localhost ~]# date +%w
3
[root@localhost ~]# date +%s
1597236988
[root@localhost ~]# date +%d
12
[root@localhost ~]# date +%W
32
[root@localhost ~]# date +%j
225
[root@localhost ~]# date -d "-1 day" +%F
2020-08-11
[root@localhost ~]# date -d "1 day" +%F
2020-08-13
[root@localhost ~]# date -d "+1 day" +%F
2020-08-13
[root@localhost ~]# date -d "3 years" +%F
2023-08-12
[root@localhost ~]# date -d "+3 years" +%F
2023-08-12
[root@localhost ~]# date -d "+3 hours" +%F_%H:%M:%S
2020-08-12_23:58:06
[root@localhost ~]# date -s 20201111
2020年 11月 11日 星期三 00:00:00 CST
[root@localhost ~]# date -s 11:11:11
2020年 11月 11日 星期三 11:11:11 CST
[root@localhost ~]# date -s "20201111 11:11:11"
2020年 11月 11日 星期三 11:11:11 CST
[root@localhost ~]# date +%F
2020-11-11
[root@localhost ~]# date +%T
11:11:29再看备份
[root@localhost ~]# tar czvf `date +%F`_bak.tar.gz /etc
[root@localhost ~]# tar czvf `date +%F_%H_%M_%S`_bak.tar.gz /etc # 如果带有时分秒,不要用冒号分隔,因为文件名的命名里不能带有冒号9 大文件切分
# 生产环境中,一些文件比较大,动则几个G,有的安装包和镜像可达到十几G,但是有些平台显示传输文 件大小,所以一些比较大的文件会被切割上传再合并。
# 这里介绍了个比较常用简单的切割方式split
linhaifeng01@appledeMacBook-Pro test % split -b 1024m vgpu-0.3.6.tgz
linhaifeng01@appledeMacBook-Pro test %
linhaifeng01@appledeMacBook-Pro test % ls
vgpu-0.3.6.tgz xaa xab xac
linhaifeng01@appledeMacBook-Pro test % ls -lh
total 16206432
-rw-r--r-- 1 linhaifeng01 staff 2.6G 8 7 13:03 b.tar
-rw-r--r--@ 1 linhaifeng01 staff 2.6G 8 5 16:22 vgpu-0.3.6.tgz
-rw-r--r-- 1 linhaifeng01 staff 1.0G 8 7 13:03 xaa
-rw-r--r-- 1 linhaifeng01 staff 1.0G 8 7 13:03 xab
-rw-r--r-- 1 linhaifeng01 staff 582M 8 7 13:03 xac
linhaifeng01@appledeMacBook-Pro test %
linhaifeng01@appledeMacBook-Pro test %
# 重新合并比对md5值是一致的
linhaifeng01@appledeMacBook-Pro test % md5 vgpu-0.3.6.tgz
MD5 (vgpu-0.3.6.tgz) = 94583a6e02508d142594701234a080ff
linhaifeng01@appledeMacBook-Pro test %
linhaifeng01@appledeMacBook-Pro test %
linhaifeng01@appledeMacBook-Pro test %
linhaifeng01@appledeMacBook-Pro test %
linhaifeng01@appledeMacBook-Pro test % cat x* > b.tar
linhaifeng01@appledeMacBook-Pro test % md5 b.tar
MD5 (b.tar) = 94583a6e02508d142594701234a080ff
七 文件系统
7.1 文件系统介绍
文件系统filesystem是操作系统内核中负责组织管理磁盘的程序。
在传统的磁盘与档案系统(又称为文件系统filesystem)的应用中,一个磁盘分割槽/分区只能被格式化成为一个文件系统,所以我们可以说一个filesystem就是一个partition分区。但是由于新技术的利用,例如我们常听到的LVM与软体磁盘阵列(software raid,又称软raid),这些技术可以将一个分区格式化为多个文件系统(例如LVM),也能够将多个分区合成一个文件系统(LVM, RAID)!所以说,目前我们在格式化时已经不再说成针对分区来格式化了,通常我们可以称呼一个可被挂载的资料为一个文件系统而不是一个分区!。
linux常见文件系统有xfs、ext4 和 btrfs 文件系统,它们都是日志文件系统(其特点是文件系统将没提交的数据变化保存到日志文件,以便在系统崩溃或者掉电时恢复数据),三者各有优势和劣势:
- btrfs (B-tree 文件系统) 是个很新的文件系统(Oracel 在2014年8月发布第一个稳定版),它将会支持许多非常高大上的功能,比如 透明压缩( transparent compression)、可写的COW 快照(writable copy-on-write snapshots)、去重(deduplication )和加密(encryption )。因此,Ceph 建议用户在非关键应用上使用该文件系统。 更多的参考包括 (1)(2)(3)。
- xfs 和 btrfs 相比较ext3/4而言,在高伸缩性数据存储方面具有优势。
- Ceph 的这篇文章 明确推荐在生产环境中使用 XFS,在开发、测试、非关键应用上使用 btrfs。
- 网上有很多的文章比较这几种文件系统,包括:
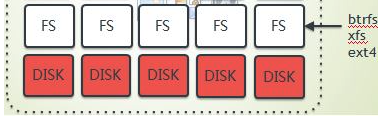
ps:windows文件系统格式: FAT32、NTFS
总结
操作系统---------》文件系统 文件系统 文件系统
硬盘------------》 分区1 分区2 分区37.2 文件系统工作原理
文件系统如何工作的呢?
须知一个文件的由两部分内容组成:
- 1、文件的元信息,例如权限(rwx)、拥有者、群组、时间参数等。
- 2、文件的实际内容
文件系统通常会将这两部份的分别存放在不同的区块
- 1、文件的元信息放置到inode区块中
- 2、文件的实际内容则放置到data block区块中。
# 强调:每个inode 与block 都有自己的编号 另外,文件还有一个超级区块(superblock)会记录整个档案系统的整体信息,包括inode与block的总量、使用量、剩余量等。
补充说明:
# 硬盘的最小存取单位-》扇区
# 操作系统的最小存取单位-》block块
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector),每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个扇区一个扇区地读取,这样效率太低,于是操作系统中的文件系统负责将磁盘的多扇区组织成一个个的block块,这样操作系统就可以一次性读取一个"块"(block),即一次性连续读取多个扇区。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
总结文件系统的三种区块inode、block、superblock的意义如下:
#1、superblock:
记录此filesystem的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
#2、inode:
(1) 记录文件元信息,包括文件对应的一个或多个block块号码
(2) 一个文件被分配唯一一个inode
#3、block:
(1) 记录文件实际内容
(2) 一个文件过大时可能会被分配多个block快,即一个文件可能对应多个block块的号码,这些号码都存放在该文件的innode里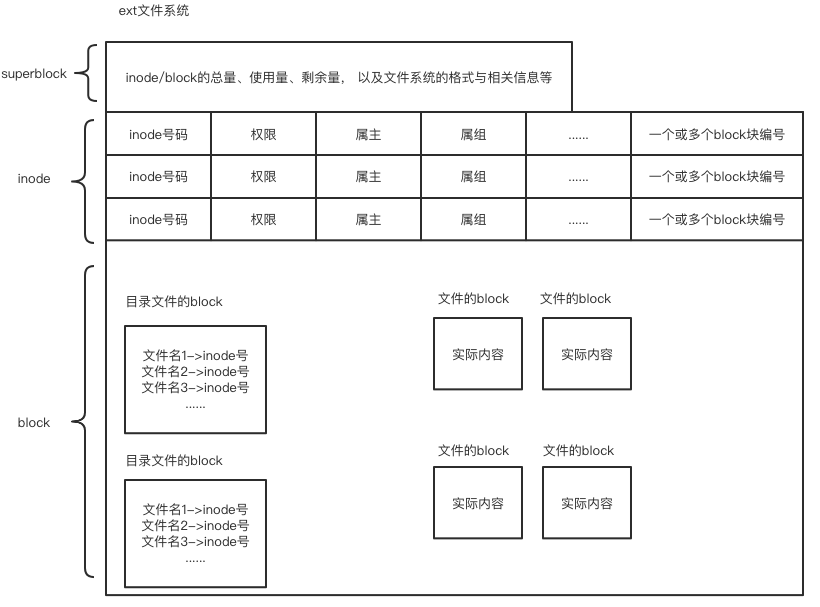
举例
[root@localhost ~]# ls -di /
64 /
[root@localhost ~]# ls -di /etc
8388673 /etc
[root@localhost ~]# ls -i /etc/passwd
8769396 /etc/passwd
[root@localhost ~]# cat /etc/passwd的整体过程如下
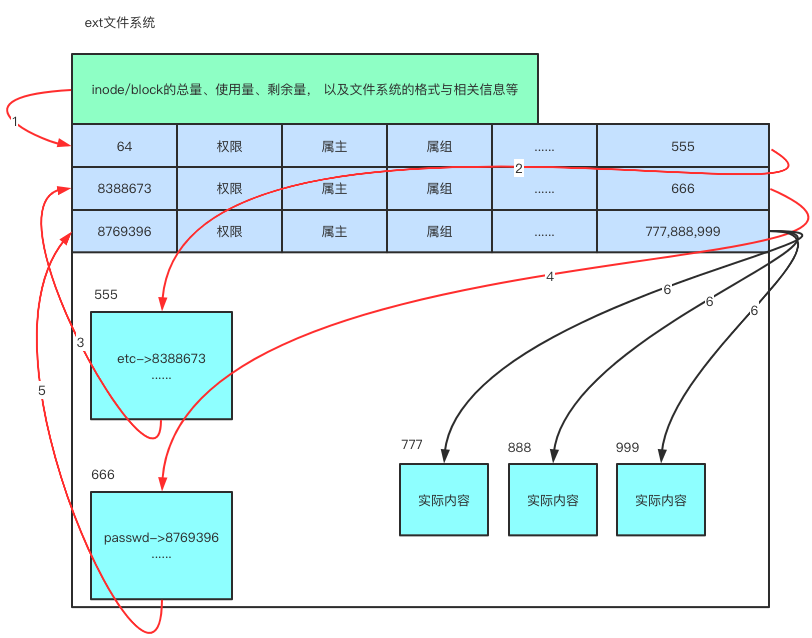
依据上述存取方式的特点,我们通常称ext文件系统为索引式文件系统(indexed allocation)。
7.3 扩展阅读
7.3.1 inode信息
文件的inode中文译名为"索引节点",是 UNIX 操作系统中的一种数据结构,其本质是结构体。
Inode负责储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小inode 。
从根本上讲, inode 中存放的是除了文件的名字以及文件真实内容之外、所有有关文件的信息/元数据(metadata),如下
● inode 编号
● 用来识别文件类型,以及用于 stat C 函数的模式信息
● 链接数,即有多少文件名指向这个inode。
● 属主的ID (UID)
● 属主的组 ID (GID)
● 文件的字节数
● 文件所使用的磁盘块的实际数目
● 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
● 指向数据块的指针 可以用stat命令,,查看某个文件的inode信息:
[root@localhost ~]# stat egon.txt
文件:"egon.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:803h/2051d Inode:16813492 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2022-12-16 16:25:29.664259627 +0800
最近更改:2022-12-16 16:25:29.664259627 +0800
最近改动:2022-12-16 16:25:29.664259627 +0800
创建时间:-
# 三种时间解释
atime : access time 访问文件内容的时间。对文件进行一次读操作,它的访问时间就会改变。例如像:cat、more等操作,但是像之前的stat还有ls命令对atime是不会有影响的。
mtime : modify time 修改文件内容的时间。文件的内容被最后一次修改的时间,我们经常用的ls -l命令显示出来的文件时间就是这个时间,当用vim对文件进行编辑之后保存,它的mtime就会相应的改变;比如:如:echo aa >> a.sh 或vim a.txt 修改内容
ctime : change time 指inode上一次文件属性变动的时间。当文件的状态被改变的时候,状态时间就会随之改变,例如当使用chmod、chown等改变文件属性的操作是会改变文件的ctime的。chmod +x a.txt例1:使用cat命令查看文件后,文件atime变更
[root@localhost ~]# touch egon.txt
[root@localhost ~]# stat egon.txt
文件:"egon.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:803h/2051d Inode:16813492 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2022-12-16 16:25:29.664259627 +0800
最近更改:2022-12-16 16:25:29.664259627 +0800
最近改动:2022-12-16 16:25:29.664259627 +0800
创建时间:-
[root@localhost ~]# cat egon.txt
[root@localhost ~]# stat egon.txt
文件:"egon.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:803h/2051d Inode:16813492 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2022-12-16 16:29:26.162262768 +0800
最近更改:2022-12-16 16:25:29.664259627 +0800
最近改动:2022-12-16 16:25:29.664259627 +0800
创建时间:-
[root@localhost ~]# 例2:使用vim命令写文件w后,文件atime、mtime、ctime都会变更。如果vim打开后只是查看没有写的话,只会变更atime。
略例3:
[root@localhost ~]# stat egon.txt
文件:"egon.txt"
大小:9 块:8 IO 块:4096 普通文件
设备:803h/2051d Inode:17696455 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2022-12-16 16:35:21.943267492 +0800
最近更改:2022-12-16 16:35:46.131267813 +0800
最近改动:2022-12-16 16:35:46.131267813 +0800
创建时间:-
[root@localhost ~]# chmod 000 egon.txt
[root@localhost ~]# stat egon.txt
文件:"egon.txt"
大小:9 块:8 IO 块:4096 普通文件
设备:803h/2051d Inode:17696455 硬链接:1
权限:(0000/----------) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2022-12-16 16:35:21.943267492 +0800
最近更改:2022-12-16 16:35:46.131267813 +0800
最近改动:2022-12-16 16:36:43.423268574 +0800
创建时间:-
[root@localhost ~]#
7.3.2 inode的大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df -i 命令。
查看每个inode节点的大小,可以用如下命令:
# 查看ext文件系统信息
sudo dumpe2fs -h /dev/hda | grep "Inode size"
# 查看xfs文件系统信息
xfs_info /dev/sda1
[root@localhost ~]# xfs_info /dev/sda1
# isize表示为inode大小;agcount为存储区群组(allocation group)的个数;
meta-data=/dev/sda1 isize=512 agcount=4, agsize=65536 blks
# sectsz指逻辑扇区(sector)的容量大小;
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
# bsize指block容量大小;
data = bsize=4096 blocks=262144, imaxpct=25
# sunit与swidth与stripe相关
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
# internal指登录区(log p)在文件系统内部,而不在外部
# bsize指占用区块大小,blocks为数量;
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
# realtiem p区域信息;extsz指extent size;
realtime =none extsz=4096 blocks=0, rtextents=0由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
7.3.3 inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:
- 首先,系统找到这个文件名对应的inode号码;
- 其次,通过inode号码,获取inode信息;
- 最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码,例如:
ls -i demo.txt7.3.4 目录项
Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名:
ls /etcls -i命令列出整个目录文件,即文件名和inode号码:
ls -i /etc如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l命令列出文件的详细信息。
ls -l /etc7.3.5 FAT文件系统
U盘使用的档案系统一般为FAT格式。FAT这种格式的档案系统并没有inode存在,所以FAT没有办法将这个档案的所有block在一开始就读取出来。每个block号码都记录在前一个block当中,他的读取方式有点像底下这样:
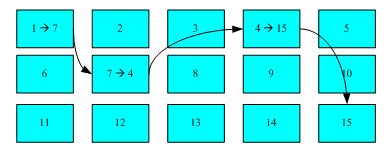
上图中我们假设档案的资料依序写入1->7->4->15号这四个block 号码中, 但这个档案系统没有办法一口气就知道四个block 的号码,他得要一个一个的将block 读出后,才会知道下一个block 在何处。如果同一个档案资料写入的block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的资料, 因此磁盘就会多转好几圈才能完整的读取到这个档案的内容!
常常会听到所谓的『碎片整理』吧? 需要碎片整理的原因就是档案写入的block太过于离散了,此时档案读取的效能将会变的很差所致。 这个时候可以透过碎片整理将同一个档案所属的blocks汇整在一起,这样资料的读取会比较容易啊! 想当然尔,FAT的档案系统需要三不五时的碎片整理一下,那么Ext2是否需要磁盘重整呢?
由于Ext2 是索引式档案系统,基本上不太需要常常进行碎片整理的。但是如果档案系统使用太久, 常常删除/编辑/新增档案时,那么还是可能会造成档案资料太过于离散的问题,此时或许会需要进行重整一下的。
7.4 Inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
- 有时,文件特别特别的大,或者磁盘IO繁忙,你直接用rm -rf删除的话会非常慢,进而影响其他进程的正常运行。如何处理呢?思路就在于inode块上,inode中存着文件的元数据(例如,文件大小、所有者ID、组ID、文件权限、时间戳等)
此时我们可以考虑使用truncate命令来替换rm命令 truncate -s 0 /path/to/your/large/file
truncate命令工作时,会直接修改inode中记录的文件大小,将其设置为0,而并不会去触及到文件内容所在的数据块。所以磁盘IO消耗极小,速度极快。
设为0之后,你再用rm命令把这这个空文件删掉就行
2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
```python
[root@localhost ~]# ls -i egon.txt
17696455 egon.txt
[root@localhost ~]# vim egon.txt # vim编辑器写文件,会改变inode号
[root@localhost ~]# ls -i egon.txt
17696461 egon.txt
[root@localhost ~]#
[root@localhost ~]# mv egon.txt EGON.txt # 重命名文件不会影响inode号
[root@localhost ~]# ls -i EGON.txt
17696461 EGON.txt
[root@localhost ~]# 问:为什么每次修改完服务器配置文件后,都需要重新加载一下配置文件?
答:因为vim每次修改完后,Inode号都会变,系统还是读取的原来inode号的配置文件,每次修改完服务器的配置文件,都要重启服务,重新读一下配置文件。
7.5 硬链接和软链接
Linux链接分两种
-
1、一种被称为硬链接(Hard Link)
【硬连接】:硬连接指通过索引节点号来进行连接。inode是可以对应多个文件名的 # 扩展阅读 inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。 这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录),这里的2是父目录对其的“硬链接”和当前目录下的".硬链接“。
-
2、另一种被称为软链接,即符号链接(Symbolic Link)
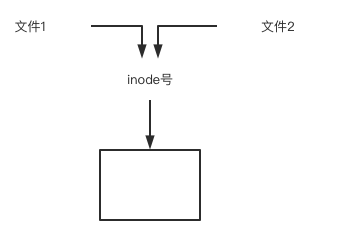
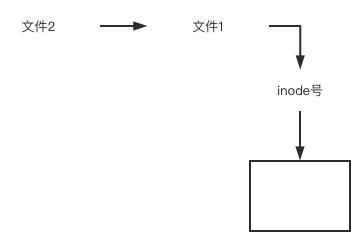
软链接文件有类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。 如下图所示 文件2和文件1的inode号码虽然不一样,但是文件2的内容是文件1的路径。读取文件2时,系统会自动将访问者导向文件1。因此,无论打开哪一个文件,最终读取的都是文件1。这时,文件2就称为文件1的"软链接"(soft link)或者"符号链接(symbolic link)。 这意味着,文件2依赖于文件1而存在,如果删除了文件1,打开文件2就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件2指向文件1的路径,而不是文件1的inode号码,文件1的inode"链接数"不会因此发生变化。
硬链接知识点提炼
0.对硬链文件内容进行修改,会影响到所有文件名;
1.硬链接文件与源文件具有相同inode的不同文件名:一个文件只能有一个inode号,但多个文件的inode号可以相同
2.删除硬链接或者原文件之一,不影响另一个文件名的访问,除非所有的都删除掉,所以硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。
3.删除所有硬链接,数据会在被磁盘检查或者新数据写入时候删除回收。
4.通过ln [原文件] [目标文件]设置硬链接
5.通过rm –f 删除硬链接
6.目录不可创建硬链接,并且硬链接无法跨区
# 示例
[root@localhost ~]# touch small_egon.txt
[root@localhost ~]# ln small_egon.txt big_egon.txt
[root@localhost ~]# ls -i small_egon.txt
17696460 small_egon.txt
[root@localhost ~]# ls -i big_egon.txt
17696460 big_egon.txt
[root@localhost ~]# ll small_egon.txt # 两个硬链接文件的硬链接数均为2
-rw-r--r-- 2 root root 0 12月 16 17:05 small_egon.txt
[root@localhost ~]# ll big_egon.txt # 两个硬链接文件的硬链接数均为2
-rw-r--r-- 2 root root 0 12月 16 17:05 big_egon.txt软链接知识提炼
#0. 对软链的源文件或目标文件内容进行修改,会影响到所有文件名;
#1. 软链接文件与源文件具有不同的inode号
#2. 删除软连接文件的源文件,软链接文件将无法使用,软链接作用
- 1.软件升级
- 2.企业代码发布
- 3.不方便目录移动
#3. 删除源文件后,软连接文件无效,应该也一起删除掉,以便回收
#4. 执行ln –s [原文件] [目标文件]创建软链接
#5. rm –f 删除软链接
#6、可以对目录创建软链接,并且软连接可以跨分区
[root@localhost ~]# touch 1.txt
[root@localhost ~]# ln -s 1.txt 2.txt
[root@localhost ~]# ls -i 1.txt
17696462 1.txt
[root@localhost ~]# ls -i 2.txt
17696463 2.txt
[root@localhost ~]#
[root@localhost ~]# ll 1.txt # 两个软链接文件的硬链接数均为1
-rw-r--r-- 1 root root 0 12月 16 17:26 1.txt
[root@localhost ~]# ll 2.txt # 两个软链接文件的硬链接数均为1
lrwxrwxrwx 1 root root 5 12月 16 17:26 2.txt -> 1.txt
[root@localhost ~]#
[root@localhost ~]# rm -rf 1.txt # 删掉1.txt,会发现2.txt不可用
[root@localhost ~]# ll 2.txt
lrwxrwxrwx 1 root root 5 12月 16 17:26 2.txt -> 1.txt
[root@localhost ~]#
[root@localhost ~]# mkdir /dir1
[root@localhost ~]# ln /dir1 /dir2
ln: "/dir1": 不允许将硬链接指向目录
[root@localhost ~]#
[root@localhost ~]# ln -s /dir1/ /dir2
[root@localhost ~]# 7.6 实战应用
磁盘有空间但创建不了文件
实战场景:在一台配置较低的Linux服务器(内存、硬盘比较小)的/data分区内创建文件时,系统提示磁盘空间不足,用df -h命令查看了一下磁盘使用情况,发现/data分区只使用了80%,还有1.9G的剩余空间,但是无法创建新的文件。当时使用的是root用户。服务器没有被黑。
[root@xxx ~]# df -h
文件系统 容量已用 可用 已用% 挂载点
/dev/sda310G 8.0G 1.9G 80%/常识: 只要权限够,磁盘上有空间一定可以创建文件。 这个是错的。
排查:
[root@xxx ~]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/sda3 5242880 52428800 100%/后来用df -i查看了一下/data所在的分区的索引节点(inode),发现已经用满(IUsed=100%),导致系统无法创建新目录和文件。
查找原因:
/data/cache目录中存在数量非常多的小字节缓存文件,占用的Block不多,但是占用了大量的inode。
解决方案1:删除/data/cache目录中的部分文件,释放出/data分区的一部分inode。
解决方案2 : 在/data备份好一些文件,然后删除这些文件,释放一些inode,然后创建一个文件夹/data/cache2。在cache2下挂载一个新分区: sda4 ,下次写数据需要写到新分区cache2目录下。
[root@egon ~]# mkfs.xfs /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=1310720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@egon ~]#
[root@egon ~]# mkdir /data/cache2
[root@egon ~]# mount /dev/sdb /data/cache2/inode分区完后,不可以增加inode数量,改变inode大小
其他场景
1.大量的小文件问题:可能会使inode耗尽,使得文件文法创建。(磁盘利用率低)—>对于小文件比较多的场景,将block划分小一点。
2.大文件问题:一个文件占用多个block,使得文件读写速率慢。—->将block划分大一点。
3.ext文件系统——xfs文件系统
企业面试题:请描述Linux中软链接和硬链接的区别
1.从定义:linux系统中,链接有两种,一种被称为软链接,类似于快捷方式,存放指向原文件inode的信息,与原文件inode不同。一种是硬链接,与原文件有相同的inode,可以指向数据block。
2.从创建方式:硬链接命令 ln [原文件] [目标文件],软链接命令ln –s [原文件] [目标文件]
3.从创建对象:ln命令不能对目录创建硬链接,但是可以对目录创建软链接。因为软链接可以跨越文件系统,硬链接则不能。对目录和为客户创建的文件软链接经常用到。
4.删除软链接文件,对硬链接和原文件无影响。
5.删除文件硬链接,对原文件及软链接文件无影响
6.删除原文件,对硬链接读取数据无影响,软链接则失效。会出现红底白字状。
7.同时删除原文件和硬链接,原文件才会被真正删除
8.很多硬件设备中的快照原理,类似于硬链接原理
