进程管理
一 进程介绍
1.1 进程是什么???
程序:存放代码的文件=》静态
进程:程序的运行过程=》动态
详细的讲:
进程是操作系统核心概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。
我们启用多个进程是为了实现并发,什么是并发?
并发:就是多个任务看起来是同时运行的
要想实现多个人看起来是同时运行的,就必须提到操作系统的一个核心技术:多道技术
多道技术:
1.产生背景:针对单核,实现并发
ps:
现在的主机一般是多核,那么每个核都会利用多道技术
有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个
cpu中的任意一个,具体由操作系统调度算法决定。
2.空间上的复用:如内存中同时有多道程序
3.时间上的复用:复用一个cpu的时间片
强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样
才能保证下次切换回来时,能基于上次切走的位置继续运行
即使可以利用的cpu只有一个(早期的计算机确实如此),也能保证支持(伪)并发的能力。将一个单独的cpu变成多个虚拟的cpu(多道技术:时间多路复用和空间多路复用+硬件上支持隔离),没有进程的抽象,现代计算机将不复存在。与并发相对应
并行:多个任务是真正 意义上的同时运行,单核只能并发,只有多核才能实现并行
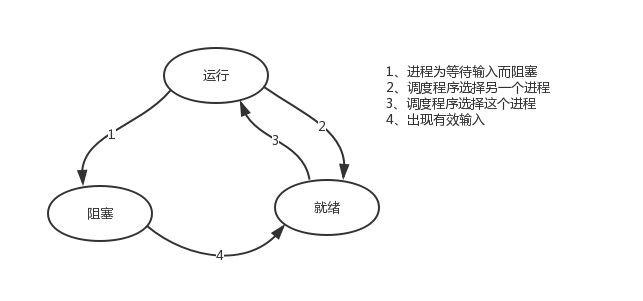
进程的状态总的可以分为三大类(后续会介绍详细分类)
1.2 父子进程
一个应用程序可能会启动多个进程,说具体点,应用程序是发送请求给操作系统来创建进程,因为进程是操作系统管理的逻辑概念
父进程:程序运行时产生的第一个进程
子进程:由父进程发起系统调用fork(),让操作系统创建出一个子进程
[root@localhost yum.repos.d]# yum install nginx -y
[root@localhost yum.repos.d]#
[root@localhost yum.repos.d]# systemctl start nginx
[root@localhost yum.repos.d]# ps aux |grep nginx
[root@rockylinux test]# ps -elf |grep nginx
1 S root 52670 1 0 80 0 - 2527 sigsus 23:04 ? 00:00:00 nginx: master process /usr/sbin/nginx
5 S nginx 52671 52670 0 80 0 - 3485 ep_pol 23:04 ? 00:00:00 nginx: worker process
5 S nginx 52672 52670 0 80 0 - 3485 ep_pol 23:04 ? 00:00:00 nginx: worker process
0 R root 52674 1556 0 80 0 - 55545 - 23:04 pts/0 00:00:00 grep --color=auto nginx1.3 进程详细状态(R、S、D、T、Z、X)
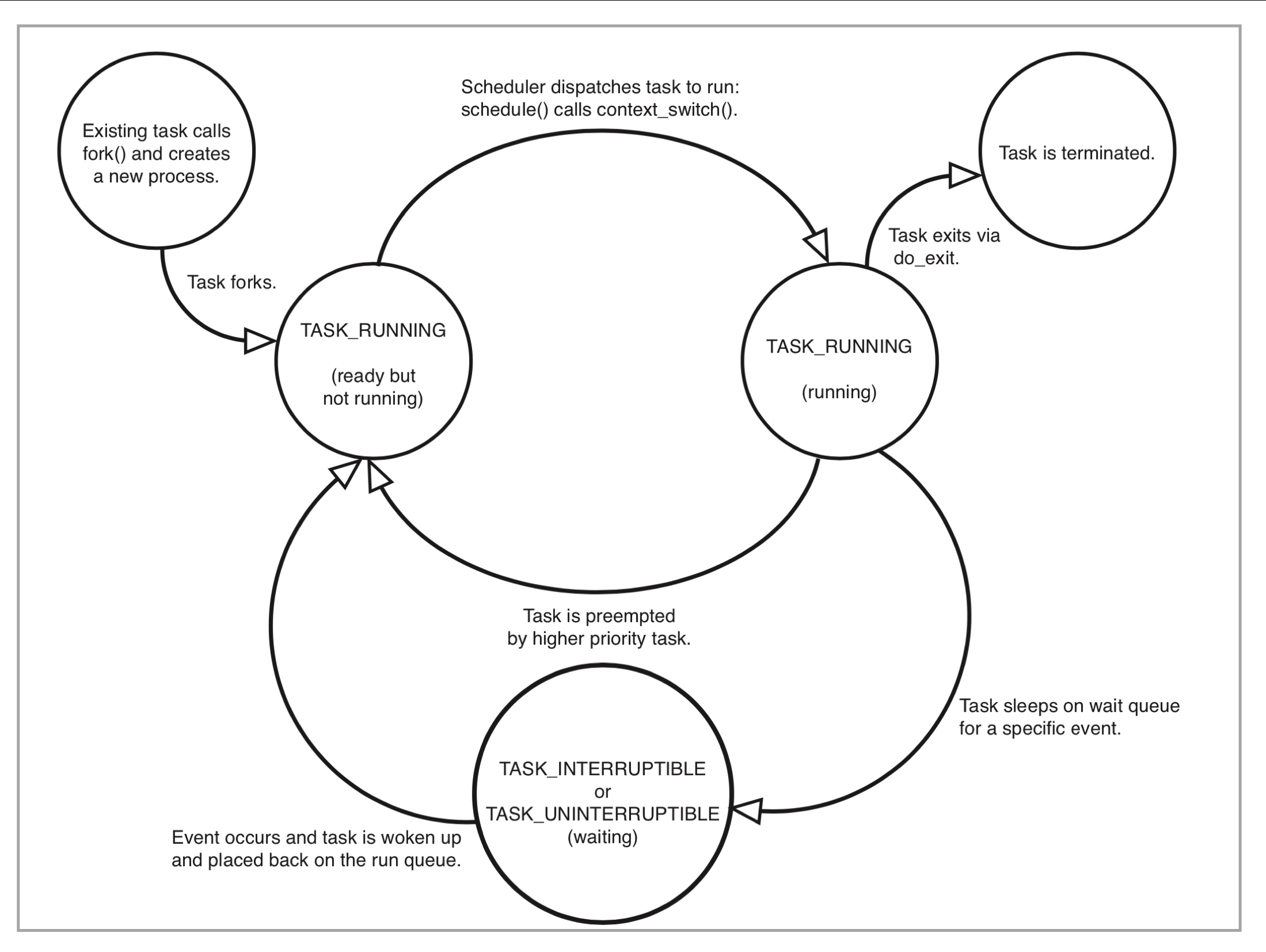
进程的状态分为两大类,活着的与死亡的,活着的包含两种,死了的也包含两种
- 一、活着的:(活着的=运行+就绪,统称TASK_RUNNING)
- 1.1 运行着的进程
- (1)、运行态,正占用着cpu资源正在运行着,状态为R
- (2)、就绪态,没有申请到cpu资源,处于运行队列中,一旦申请到cpu就可以立即投入运行,状态也为R
- 1.2 睡眠的进程
- (1)、可中断睡眠(TASK_INTERRUPTIBLE),状态为S,等待某个资源而进入的状态,比如等待本地或网络用户输入,也可以等待一个信号量(Semaphore),执行的IO操作可以得到硬件设备的响应
- (2)、不可中断睡眠(TASK_UNINTERRUPTIBLE),状态为D,处于睡眠状态,但是此刻进程是不可中断的,意思是不响应异步信号,执行的IO操作得不到硬件设备的响应(可能是因为硬件繁忙,因此导致内存里的一些缓存数据无法及时刷入磁盘,所以肯定不允许你中断该睡眠状态,并且你会发现处于D状态的进程kill -9竟然也杀不死,就是为了保证数据安全)
- 1.1 运行着的进程
- 二、死亡的:即执行do_exit()结束进程
-(1)EXIT_DEAD:也就是进程真正结束退出那一瞬间的状态,通常我们看不到,因为很快就没了
-(2)EXIT_ZOMBIE,这个是进程进入EXIT_DEAD状态前的一个状态,该状态称之为僵尸进程,状态显示为Z,也就是说所有进程在死前都会进入僵尸进程的状态。
详的如下
# R- -可执行状态(运行状态)
表示该进程当前处于运行态 或者 可运行的就绪态(Running or Runnable)。这表示进程正在运行或在运行队列中等待CPU时间片
linux的两种睡眠状态S与D是一个重点知识,此处先赞做了解,后续我们将详细介绍
# 大写字母S- -可中断睡眠状态(sleeping)
表示该进程当前处于可中断的休眠状态(Interruptible Sleep),即等待某个事件的发生,可能是用户输入或者等待某种资源可用。
# 小写字母s:
表示该进程是会话(session)的领导/领进程。每一个会话都有一个会话领导进程。当一个会话被创建时,
会话的创建者就成为那个会话的领导进程,并且他在那个会话中的所有子进程都属于那个会话。
# <: 是表示该进程是高优先级的进程,它的 nice 值是负值。
# N:低优先级
# l(is multi-threaded): 即进程是多线程的,这是在由一个单一的进程管理多个执行线程的情况下出现的。
# +号:表示该进程属于前台进程组。
例如:S+:代表了进程是在前台进程组中,并且处于可中断的休眠状态。
# 举例
Ss
Ssl
S+:可中断睡眠、前台进程
S<sl: 可中断睡眠、高优先级、是会话的领导者、是多线程的
# D:不可中断睡眠(disk sleep)
进程在内核中某些不能被信号打断,例如对某些硬件设备进行操作时刻(等待磁盘Io,等待网络io等等)。进程处于D状态一般情况下很短暂,不应该被top或者ps看到。如果进程在top和ps看到长期处于D状态,那么可能进程在等待IO时出现了问题导致进程一直等待不到IO资源 此时如果要处理掉这个D进程,那么只能重启整个系统才会恢复。因为此时整个进程无法被kill 掉。
# T:暂停状态
表示该进程已被停止(Stopped)。
给进程发送一个SIGSTOP信号,进程就会响应信号进入T状态,
再通过发送SIGCONT信号让进程继续运行。
kill -SIGSTOP pid号
kill -SIGCONT pid号
当你在 vi 文本编辑器中输入 control-Z 时也会发送停止信号,让进程暂停。
# Z:僵死状态
僵死状态是一个比较特殊的状态。进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
#X- -死亡状态或退出状态(dead)
死亡状态是内核运⾏ kernel/exit.c ⾥的 do_exit() 函数返回的状态。这个状态只是⼀个返回状态,你不会在任务列表⾥看到这个状态小练习:暂停与恢复进程运行
# 1、准备一个程序:a.sh
#!/bin/bash
for i in `seq 1 1000000`;
do
sleep 1
echo $i >> /tmp/run.log
done
# 2、运行程序a.sh,启动一个进程
sh a.sh &
# 3、查看日志
tail -f /tmp/run.log
# 4、打开另外一个终端测试暂停与恢复,观察你的run.log有何反应
ps aux | grep a.sh
kill -SIGSTOP pid号
kill -SIGCONT pid号
二 查看进程
2.1 ps aux查看
ps aux是常用组合,查看进程用户、PID、占用CPU百分比、占用内存百分比、状态、执行的命令等。
-a #显示一个终端的所有进程
-u #选择有效的用户id或者是用户名
-x #显示没有控制终端的进程,同时显示各个命令的具体路径。示例
[root@localhost ~]# ps aux |head -5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 128400 7104 ? Ss 8月12 0:05 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 8月12 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 8月12 0:00 [kworker/0:0H]
root 5 0.0 0.0 0 0 ? S 8月12 0:01 [kworker/u256:0]查看结果显示
USER: 运行进程的用户
PID: 进程ID
%CPU: CPU占用率
%MEM: 内存占用率,指的是实际内存RSS占用率
VSZ: 占用虚拟内存,单位:KB(killo Bytes)
VSZ是指已分配的线性空间大小,这个大小通常并不等于程序实际用到的内存大小,产生这个的可能性很多
比如内存映射,共享的动态库,或者向系统申请了更多的堆,都会扩展线性空间大小。
RSS: 占用实际内存,单位:KB(killo Bytes)
RSZ是Resident Set Size,常驻内存大小,即进程实际占用的物理内存大小
TTY: 进程运行的终端
STAT: 进程状态 man ps (/STATE)
R 运行
S 可中断睡眠 Sleep,即在睡眠的过程中可以接收信号唤醒=》执行的IO操作可以得到硬件设备的响应
D 不可中断睡眠,即在睡眠的过程中不可以接收信号唤醒=》执行的IO操作得不到硬件设备的响应
T 停止的进程
Z 僵尸进程
X 死掉的进程(几乎看不见,因为死了就立即回收了)
< 标注了<小于号代表优先级较高的进程
N N代表优先级较低的进程
s 该进程包含子进程,该进程自己是整个会话的领导者
+ +表示是前台的进程组
l 小写字母l,代表以线程的方式运行,即多线程
| 管道符号代表多进程
START: 进程的启动时间
TIME: 进程占用CPU的总时间
COMMAND: 进程文件,进程名
带[]号的代表内核态进程
不带[]号的代表用户态进程
补充Centos9中还有一个大写字母I的进程状态
大写字母"I"代表的进程状态是"Idle kernel thread",这意味着该进程是一个空闲的内核线程,不是用户模式下的空闲进程。这个状态通常只应用于内核线程,用户进程通常不会有这个状态。

Linux进程有两种睡眠状态
# 1、S (TASK_INTERRUPTIBLE)(可中断睡眠,在ps命令中显示“S”)
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
例如:处在这种睡眠状态的进程是可以通过给它发送signal来唤醒的,比如发HUP信号给nginx的master进程可以让nginx重新加载配置文件而不需要重新启动nginx进程;
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
# 2、D (TASK_UNINTERRUPTIBLE)(不可中断睡眠,在ps命令中显示“D”)
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!。
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec 通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:
[root@localhost ~]# cat test.c # 该代码只是帮你模拟出D状态的进程,本质在用户态还是sleep命令,所以你kill是可以干掉的。
void main() {
if (!vfork()) sleep(100);
}
注意如果是ubuntu系统则必须加上头文件声明才可以(ubuntu系统要求更严格),否则编译会报错
#include <sys/types.h>
#include <unistd.h>
void main() {
if (!vfork()) sleep(100);
}
[root@localhost ~]# gcc -o test test.c
[root@localhost ~]# ./test
[root@localhost ~]# ps -aux | grep test
root 19454 0.0 0.0 4212 352 pts/6 D+ 10:02 0:00 ./test
root 19455 0.0 0.0 4212 352 pts/6 S+ 10:02 0:00 ./test
# 进程为什么会被置于uninterruptible sleep状态呢?
进程为什么会被置于D状态呢?处于uninterruptible sleep状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就很会不幸地被ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如NFS挂载的远程文件系统已经不可访问了。
正是因为得不到IO的响应,进程才进入了uninterruptible sleep状态,所以要想使进程从uninterruptible sleep状态恢复,就得使进程等待的IO恢复,比如如果是因为从远程挂载的NFS卷不可访问导致进程进入uninterruptible sleep状态的,那么可以通过恢复该NFS卷的连接来使进程的IO请求得到满足。
# 强调
D与Z状态的进程都无法用kill -9杀死
# D状态,往往是由于 I/O 资源得不到满足,而引发等待
在内核源码 fs/proc/array.c 里,其文字定义为“ "D (disk sleep)", /* 2 */ ”(由此可知 D 原是Disk的打头字母),对应着 include/linux/sched.h 里的“ #define TASK_UNINTERRUPTIBLE 2 ”。举个例子,当 NFS 服务端关闭之时,若未事先 umount 相关目录,在 NFS 客户端执行 df 就会挂住整个登录会话,按 Ctrl+C 、Ctrl+Z 都无济于事。断开连接再登录,执行 ps axf 则看到刚才的 df 进程状态位已变成了 D ,kill -9 无法杀灭。正确的处理方式,是马上恢复 NFS 服务端,再度提供服务,刚才挂起的 df 进程发现了其苦苦等待的资源,便完成任务,自动消亡。若 NFS 服务端无法恢复服务,在 reboot 之前也应将 /etc/mtab 里的相关 NFS mount 项删除,以免 reboot 过程例行调用 netfs stop 时再次发生等待资源,导致系统重启过程挂起。
Nginx举例一则,只是举个例子大概看看就行
第二客户端机器我们将运行另一个副本的wrk,但是这个脚本我们使用50的并发连接来请求相同的文件。因为这个文件被经常访问的,它将保持在内存中。在正常情况下,NGINX很快的处理这些请求,但是工作线程如果被其他的请求阻塞性能将会下降。所以我们暂且叫它“加载恒定负载”。
性能将由服务器上ifstat监测的吞吐率(throughput)和从第二台客户端获取的wrk结果来度量。
现在,没有线程池的第一次运行不会给我们带来非常令人兴奋的结果
top - 10:40:47 up 11 days, 1:32, 1 user, load average: 49.61, 45.77 62.89
Tasks: 375 total, 2 running, 373 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 67.7 id, 31.9 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 49453440 total, 49149308 used, 304132 free, 98780 buffers
KiB Swap: 10474236 total, 20124 used, 10454112 free, 46903412 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4639 vbart 20 0 47180 28152 496 D 0.7 0.1 0:00.17 nginx
4632 vbart 20 0 47180 28196 536 D 0.3 0.1 0:00.11 nginx
4633 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.11 nginx
4635 vbart 20 0 47180 28136 480 D 0.3 0.1 0:00.12 nginx
4636 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.14 nginx
4637 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.10 nginx
4638 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4640 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4641 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4642 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.11 nginx
4643 vbart 20 0 47180 28276 536 D 0.3 0.1 0:00.29 nginx
4644 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.11 nginx
4645 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.17 nginx
4646 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4647 vbart 20 0 47180 28208 532 D 0.3 0.1 0:00.17 nginx
4631 vbart 20 0 47180 756 252 S 0.0 0.1 0:00.00 nginx
4634 vbart 20 0 47180 28208 536 D 0.0 0.1 0:00.11 nginx<
4648 vbart 20 0 25232 1956 1160 R 0.0 0.0 0:00.08 top
25921 vbart 20 0 121956 2232 1056 S 0.0 0.0 0:01.97 sshd
25923 vbart 20 0 40304 4160 2208 S 0.0 0.0 0:00.53 zsh
在这种情况下,吞吐率受限于磁盘子系统,而CPU在大部分时间里是空转状态的。从wrk获得的结果来看也非常低:
Running 1m test @ http://192.0.2.1:8000/1/1/1
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.42s 5.31s 24.41s 74.73%
Req/Sec 0.15 0.36 1.00 84.62%
488 requests in 1.01m, 2.01GB read
Requests/sec: 8.08
Transfer/sec: 34.07MB
请记住,文件是从内存送达的!第一个客户端的200个连接创建的随机负载,使服务器端的全部的工作进程忙于从磁盘读取文件,因此产生了过大的延迟,并且无法在合适的时间内处理我们的请求。示例1
# 1、在窗口1执行命令
[root@egon ~]# vim egon.txt
# 2、在窗口2查看vim的运行状态为:S+
[root@egon ~]# ps aux |grep [v]im # 加中括号会筛出你想要的,grep命令本身产生的进程不展示
root 103231 1.5 0.2 149828 5460 pts/2 S+ 17:48 0:00 vim egon.txt
# 3、在窗口1执行:ctrl+z,将进程放置到后台
[root@egon ~]# vim egon.txt
[4]+ 已停止 vim egon.txt
# 4、在窗口2查看vim的运行状态为:T
[root@egon ~]# ps aux |grep [v]im
root 103231 0.3 0.2 149828 5460 pts/2 T 17:48 0:00 vim egon.txt示例2:查看S+、R+、D+
# 1、在窗口1执行命令
[root@egon ~]# tar cvzf egon.tar.gz /etc/ /usr/ /var/ /usr/
# 2、在窗口2查看tar的状态:S+、R+、D+
[root@egon ~]# while true;do ps aux |grep [t]ar;sleep 0.3;clear;done查看进程树
[root@egon ~]# rpm -qf `which pstree`
psmisc-22.20-16.el7.x86_64
[root@egon ~]# pstree
[root@egon ~]# pstree 104239
bash───bash───bash───bash───pstree查看ppid
[root@egon ~]# ps -elf | head -10
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11月01 ? 00:00:07 /usr/lib/systemd/systemd --system --deserialize 20
root 2 0 0 11月01 ? 00:00:00 [kthreadd]
root 4 2 0 11月01 ? 00:00:00 [kworker/0:0H]
root 6 2 0 11月01 ? 00:00:06 [ksoftirqd/0]
root 7 2 0 11月01 ? 00:00:00 [migration/0]
root 8 2 0 11月01 ? 00:00:00 [rcu_bh]
root 9 2 0 11月01 ? 00:00:03 [rcu_sched]
root 10 2 0 11月01 ? 00:00:00 [lru-add-drain]
root 11 2 0 11月01 ? 00:00:01 [watchdog/0]2.2 top命令动态查看
(1) 基本用法
[root@localhost ~]# top
[root@localhost ~]# top -d 1 # 1秒刷新一次
[root@localhost ~]# top -d 1 -p 进程的pid
[root@localhost ~]# top -d 1 -p `pgrep nginx | head -1`
[root@localhost ~]# top -d 1 -p `pgrep sshd | head -1`,33 # 查看sshd以及pid为33的进程
[root@localhost ~]# top -d 1 -u nginx # 查看指定用户进程
[root@localhost ~]# top -b -n 2 > top.txt # 将2次top信息写入到文件(2) 显示信息解释
第一部分:系统整体统计信息
up左边的代表当前的时间
up右边代表运行了多长时间
load average: 0.86, 0.56, 0.78 CPU 1分钟,5分钟,15分钟平均负载
平均负载解释如下:
'''
===========> 关于cpu的使用情况有两个参考指标
1、关于cpu使用率
某个用户进程对cpu的利用率 = 用户进程占用的cpu时间(包括用户态us+内核态sy) / cpu经历的这段总时间
进程对cpu的利用率为100%代表使用1颗cpu
进程对cpu的利用率为200%代表使用2颗cpu
如果宿主机只有4颗cpu,那么某个进程对cpu的利用率最多400%
总结:cpu使用率反应的是cpu的利用情况
2、关于load average
在某段时间内平均活跃的进程数(包含系统处于可运行状态以及不可中断状态的平均进程数)
如果宿主机有4颗cpu,那么平均负载是可以超过4的
总结:负载负载反应的cpu的工作量
为何不可中断睡眠也属于活跃的进程
一个进程内要做的事可以分为两大类
1、计算任务---》cpu负责运行
2、io任务-----》磁盘、网卡负责处理
只要该进程正在被处理着,那它就属于活跃的进程
cpu在执行该进程的计算机任务,肯定属于活跃
磁盘在处理该进程的io任务,那肯定也属于活跃
总之有事做就属于活跃
而S状态,在等待用户输入内容,而此时用户什么也没有输,即io操作啥事也没做,计算任务也肯定没有
整个进程就是不活跃的
如果你的物理机有1颗cpu,那么满负载为1,代表可以同时运行1个进程,超过1就代表超载,小于1就代表空闲
如果你的物理机有4颗cpu,那么满负载为4,代表可以同时运行4个进程,超过4则代表超载,小于4就代表空闲
以1颗cpu为例,如果处理器上有一个R的进程,同时在系统的进程可运行队列里有9个进程,那么1分钟的load average=1+9
如果宿主机有4颗cpu,那么平均负责是可以超过4的
3、结论
有可能会出现工作量很大,但是利用率很低,比如每个员工手里都有很多活要做,但实际上你问问每个活的进度是啥大家都告诉这些活都在进行着,但是都处于
等待的状态,你作为老板你瞬间怒了,你傻啊,等待的过程你不会干别的事啊,员工也很冤枉,说不行啊老板,我这个io是不可中断的io,不能被中断
必须等着对方送过来数据才行,你别看我很闲,但是这件事确实是正在进行的事情
===========>平均负载多少合理?
假设现在在4,2,1核的CPU上,如果平均负载为2时,意味着什么呢?
------------------------------------------------
核心数 平均负载 含义
4 2 有一半(50%)的CPU时间是空闲状态
2 2 CPU的时间刚好完全被占用
1 2 至少一半的进程是抢不到CPU的时间的
-------------------------------------------------
===========>平均负载的三个数值我们该关注哪一个?
三个值相当于三个样本,我们应该统筹地看
1、如果1分钟,5分钟,15分钟的负载数值都相差不大,代表系统的负载从过去到现在都近乎一样
2、如果1分钟的值,远小于15分钟的值,那么证明系统的平均负载逐渐降低,即我们的系统刚刚经历过大风浪,但目前已逐渐趋于平均。至于15分钟区间内,系统负载上升的原因,还需要我们认真查明
3、如果15分钟的值,远小于1分钟的值,那么证明系统的平均负载逐渐升高,有可能是临时的也有可能持续上升,需要观察
4、一旦1分钟的平均负载接近或超过了CPU的个数,就意味着,系统正在发生过载的问题,这时候就得分析问题了, 并且要想办法优化。
==========>平均负载实验:4个CPU跑满
[root@egon ~]# cat /proc/cpuinfo | grep processor
processor : 0
processor : 1
processor : 2
processor : 3
打开窗口1:执行top命令,然后按1,观察四个核的id几乎为100%,然后在窗口2执行命令观察负载情况
[root@egon ~]# top
[root@egon ~]# 按1
打开窗口2:依次执行下述命令,然后在窗口来观察变化
[root@egon ~]# while true;do ((1+1));done &
[root@egon ~]# while true;do ((1+1));done &
[root@egon ~]# while true;do ((1+1));done &
[root@egon ~]# while true;do ((1+1));done &
用ps aux | grep bash会看到一系列R的bash进程,然后一个个杀掉,观察cpu的负载逐步恢复平静
思考:如果把测试命令换成下述命令,一直连续执行n次,cpu负载都不会很高,为什么??
[root@egon ~]# while true;do ((1+1));sleep 0.1;done &
[root@egon ~]# while true;do ((1+1));sleep 0.1;done &
[root@egon ~]# while true;do ((1+1));sleep 0.1;done &
。。。执行好多次
补充1:也可以使用stress工具来取代上述的while命令
stress是Linux系统压力测试工具,可用作异常进程模拟平均负载升高的场景,需要安装yum install stress -y
[root@egon ~]# stress --cpu 4 --timeout 3000 # 3000代表持续执行3000秒
补充2:安装yum install sysstat -y会得到下述两个命令
mpstat 是多核CPU性能分析工具,用来实时检查每个CPU的性能指标,以及所有CPU的平均指标。
[root@egon ~]# mpstat -P ALL 3 # 3s输出一组所有指标
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,IO,以及上下文切换等性能指标。
[root@egon ~]# pidstat -u 1 5 # 1秒一次,总共输出5次
'''(3)第三行显示信息解释:
us User,用户态进程占用cpu时间的百分比,不包括低优先级进程的用户态时间(值1-19)
sys System,内核态进程占用cpu时间的百分比
ni Nice,nice值为1-19的进程,用户态占cpu时间的百分比
id Idle,系统空闲cpu的百分比
wa Iowait,系统等待I/O的cpu时间占比,该时间不计入进程的CPU时间
hi Hardware irq,处理硬件中断所占用CPU的时间,该时间同样不计入进程的CPU时间
si Softtirq,处理软件中断的时间,该时间不计入进程的CPU时间
st Steal,表示同一宿主机上的其他虚拟机抢走的CPU时间
nice 是 Linux 和 Unix 系统中的一个命令,它可以用来调整进程的优先级。
在 Unix-like 系统中,每一个进行CPU调度的任务(包含进程、线程)都有一个对应的 nice 值,这个值决定了其在获得 CPU 时间方面的优先级。nice 值的范围在 -20 到 19,其中 -20 表示最高优先级,而 19 刨示最低优先级。默认情况下,新创建的进程 nice 值是 0。
所以我们以0这个nice值为分水岭,1-19都属于比普通进程优先级要低的进程,这类低优先级的进程对cpu的使用率会计入top统计的ni状态中
-20~-1都属于比较高优先级的,会计入top统计的us状态中
nice值又称之为好心值,值越大越好心,那么优先级就会越低,这就有点接近生活了
如果你对一个进程设置了 nice 值,那么它的 CPU 调度优先级将会根据这个 nice 值来进行调整:
如果你将 nice 值设置得较低(例如-20),那么这个进程将会有更高的优先级,当 CPU 进行任务调度的时候,这个进程更有可能被选中执行。
反之,如果你将 nice 值设置得较高(例如+19),那么这个进程的优先级将会降低,它被 CPU 选中执行的机会就更小了。
需要注意的是,只有拥有适当权限(例如 root 用户)才能够将进程的 nice 值设置为负数。这是为了防止普通用户通过增大某个进程的优先级,不公平地占用过多的 CPU 资源。
linux中断:https://www.cnblogs.com/linhaifeng/articles/13916102.html下图中箭头Timeline代表一条时间轴,以此为分割,上半部分代表Linux用户态(User space),下半部分代表内核态(Kernel space)。
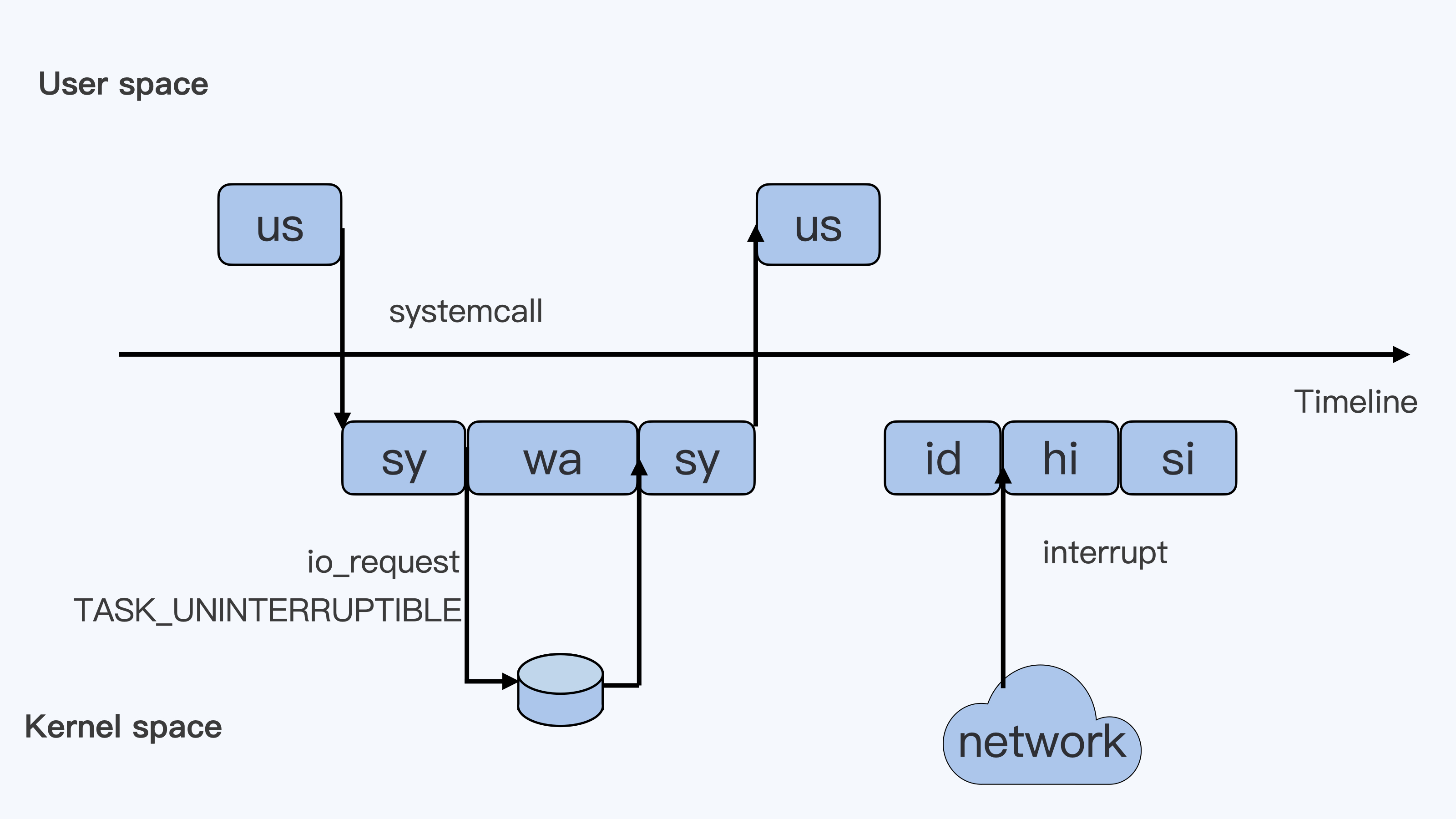
为了便于理解,假设只有一个cpu,按照从上到下从左到右的顺序以此解析每个框的含义
- 第一个框us:一个用户程序开始运行,那么就对应于着第一个“us”框,代表linux用户态的Cpu Usage。普通的用户程序代码中,只要不是调用系统调用(System Call),这些代码的指令消耗的CPU就都属于“us”。
- 第二个框sys:当这个用户程序代码调用了系统调用,比如read()去读取一个文件,这时候这个用户的进程就会从用户态切换到内核态。内核态read()系统调用在读到真正disk上的文件前,就会进行一些文件系统层的操作,那么这些代码指令的消耗就属于“sy”,代表内核cpu使用
- 第三个框wa:接下来,这个read()系统调用会向linux的Block Layer发出一个I/O Request,触发一个真正的磁盘读取操作,此时,这个进程一般会被置为不可中断睡眠状态TASK_UNINTERUPTIBLE。而linux会把这段时间标识成“wa”,
- 第四个框sys:紧接着,当磁盘返回数据时,进程在内核态拿到数据,这里仍旧是内核态CPU使用中的“sy”
- 第五个框us:然后进程再从内核态切回用户态,在用户态得到文件数据,这里进程又回到用户态CPU使用,即“us”
- 第六个框id:好,在这里我们假设一下,这个用户进程在读取数据之后,没事可做就休眠了,并且假设此时在这个CPU上也没有其他需要运行的进程了,那么系统就会进入“id”这个步骤,代表系统处于空闲状态
- 第七个框hi:如果此时这台机器收到一个网络包,网卡就会发出一个中断(interrupt),该中断为硬中断,cpu必须响应,cpu响应后进入中断服务程序,此时cpu就会进入“hi”,代表cpu处理硬中断的开销。
- 第八个框si:由于我们的中断服务需要关闭中断,所以这个硬中断的时间不能太长。但发生中断之后的工作是必须要完成的,如果这些工作比较耗时怎么办?linux中有一个软中断的概念(softirq),它可以完成这些耗时比较长的工作。从网卡收到的数据包的大部分工作,都是通过软中断来最终处理的。
- 强调:无论是hi还是si,占用的cpu时间,都不会计入进程的cpu时间,因为本来中断程序就是单独的程序,它们在处理时本就不属于任何一个进程。
- 此外还有两个类型的cpu:一个是“ni”,另外一个是“st”
“ni”是nice的缩写,这里表示如果进程的nice值是正值(1-19),代表优先级比较低的进程运行时所占用的cpu
“st”是steal的缩写,是虚拟机里用的cpu使用类型,表示有多少时间是被同一个宿主机上的其他虚拟机抢走的
好奇宝宝发问:top命令是如何统计上述cpu状态的???
进程从启动那一刻开始linux操作系统就会累积该进程对cpu的资源的占用时间,没错是累加的。
举例:开机后时间在一分一秒地走,此时我们发现当前时间为18:00,某进程占用cpu的时间的累积总量为10s,然后时间来到了19:00,我们发现该进程对cpu的占用时间累积到了100s,那么在cpu经历的这一个小时内,该进程对cpu的占用时间为100s-10s
具体来说负责记录下进程对cpu资源累积占用的是linux系统中proc文件系统
top命令就是通过查看proc文件系统中每个进程对应stat文件中的2个数值来完成统计的
具体如何统计与计算的,感兴趣可以看:https://egonlin.com/?p=7388 第2.1小节,在docker容器深入部分我们也会详细介绍这一点
(4)其余显示信息:关于进程
top 命令 VSZ,RSS,TTY,STAT, VIRT,RES,SHR,DATA的含义
====================================================
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out(当某进程向OS请求内存发现不足时,OS会把内存中暂时不用的数据交换出去,放在SWAP分区中,这个过程称为SWAP OUT。当某进程又需要这些数据且OS发现还有空闲物理内存时,又会把SWAP分区中的数据交换回物理内存中,这个过程称为SWAP IN)
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来,因为内存充裕了,大家就没必要合租内存了
DATA
1、数据占用的内存。如果top没有显示,按f键、然后用空格选中DATA项目、然后按q则可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
# 三 top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下(了解):
命令
M 按内存的使用排序
P 按CPU使用排序
N 以PID的大小排序
R 对排序进行反转
f 自定义显示字段
1 显示所有CPU的负载
s 改变画面更新频率
h|?帮助
< 向前
> 向后
z 彩色(5) 调整进程的优先级(了解):
1、r 调整进程的优先级(Nice Level)
优先级的数值为-20~19,其中数值越小优先级越高,数值越大优先级越低,-20的优先级最高,19的优先级最低。
需要注意的是普通用户只能在0~19之间调整应用程序的优先权值,只有超级用户有权调整更高的优先权值(从-20~19)。
2、k 给进程发送信号 1,2(^C),9,15,18,19(^Z)(6) 更多内部命令(了解)
l – 关闭或开启第一部分第一行 top 信息的表示
t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
N – 以 PID 的大小的顺序排列表示进程列表
P – 以 CPU 占用率大小的顺序排列进程列表
M – 以内存占用率大小的顺序排列进程列表
h – 显示帮助
n – 设置在进程列表所显示进程的数量
q – 退出 top
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。(7) 拓展阅读swap分区:https://www.cnblogs.com/linhaifeng/articles/13915855.html
三 特殊进程
3.1 僵尸进程与孤儿进程
引子
冤魂 Z 是杀不死的,是因为它已经死了,否则怎么叫 Zombie(僵尸)呢?冤魂不散,自然是生前有结未解之故。在UNIX/Linux中,每个进程都有一个父进程,进程号叫PID(Process ID),相应地,父进程号就叫PPID(Parent PID)。当进程死亡时,它会自动关闭已打开的文件,舍弃已占用的内存、交换空间等等系统资源,然后向其父进程返回一个退出状态值,报告死讯。如果程序有 bug,就会在这最后一步出问题。儿子说我死了,老子却没听见,没有及时收棺入殓,儿子便成了僵尸......僵尸进程
#1、什么是僵尸进程
操作系统负责管理进程
我们的应用程序若想开启子进程,都是在向操作系统发送系统调用
当一个子进程开启起来以后,它的运行与父进程是异步的,彼此互不影响,谁先死都不一定
linux操作系统的设计规定:父进程应该具备随时获取子进程状态的能力
如果子进程先于父进程运行完毕,此时若linux操作系统立刻把该子进程的所有资源全部释放掉,那么父进程来查看子进程状态时,会突然发现自己刚刚生了一个儿子,但是儿子没了!!!
这就违背了linux操作系统的设计规定
所以,linux系统出于好心,若子进程先于父进程运行完毕/死掉,那么linux系统在清理子进程的时候,会将子进程占用的重型资源都释放掉(比如占用的内存空间、cpu资源、打开的文件等),但是会保留一部分子进程的关键状态信息,比如进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等,此时子进程就相当于死了但是没死干净,因而得名"僵尸进程",其实僵尸进程是linux操作系统出于好心,为父进程准备的一些子进程的状态数据,专门供父进程查阅,也就是说"僵尸进程"是linux系统的一种数据结构,所有的子进程结束后都会进入僵尸进程的状态
# 2、那么问题来了,僵尸进程残存的那些数据不需要回收吗???
当然需要回收了,但是僵尸进程毕竟是linux系统出于好心,为父进程准备的数据,至于回收操作,应该是父进程觉得自己无需查看僵尸进程的数据了,父进程觉得留着僵尸进程的数据也没啥用了,然后由父进程发起一个系统调用wait / waitpid来通知linux操作系统说:哥们,谢谢你为我保存着这些僵尸的子进程状态,我现在用不上他了,你可以把他们回收掉了。然后操作系统再清理掉僵尸进程的残余状态,你看,两者配合的非常默契,但是,怕就怕在。。。
# 3、分三种情况讨论
1、linux系统自带的一些优秀的开源软件,这些软件在开启子进程时,父进程内部都会及时调用wait/waitpid来通知操作系统回收僵尸进程,所以,我们通常看不到优秀的开源软件堆积僵尸进程,因为很及时就回收了,与linux系统配合的很默契
2、一些水平良好的程序员开发的应用程序,这些程序员技术功底深厚,知道父进程要对子进程负责,会在父进程内考虑调用wait/waitpid来通知操作系统回收僵尸进程,但是发起系统调用wait/waitpid的时间可能慢了些,于是我们可以在linux系统中通过命令查看到僵尸进程状态
[root@egon ~]# ps aux | grep [Z]+
3、一些垃圾程序员,技术非常垃圾,只知道开子进程,父进程也不结束,就在那傻不拉几地一直开子进程,也压根不知道啥叫僵尸进程,至于wait/waitpid的系统调用更是没听说过,这个时候,就真的垃圾了,操作系统中会堆积很多僵尸进程,此时我们的计算机会进入一个奇怪的现象,就是内存充足、硬盘充足、cpu空闲,但是,启动新的软件就是无法启动起来,为啥,因为操作系统负责管理进程,每启动一个进程就会分配一个pid号,而pid号是有限的,正常情况下pid也用不完,但怕就怕堆积一堆僵尸进程,他吃不了多少内存,但能吃一堆pid
# 4、如果清理僵尸进程
针对情况3,只有一种解决方案,就是杀死父进程,那么僵尸的子进程会被linux系统中pid为1的顶级进程(init或systemd)接管,顶级进程会定期发起系统调用wait/waitpid来通知操作系统清理僵尸
针对情况2,可以发送信号给父进程,通知它快点发起系统调用wait/waitpid来清理僵尸的儿子
kill -CHLD 父进程PID
# 5、结语
僵尸进程是linux系统出于好心设计的一种数据结构,一个子进程死掉后,相当于操作系统出于好心帮它的爸爸保存它的遗体,之说以会在某种场景下有害,是因为它的爸爸不靠谱,儿子死了,也不及时收尸(发起系统调用让操作系统收尸)
说白了,僵尸进程本身无害,有害的是那些水平不足的程序员,他们总是喜欢写bug,好吧,如果你想看看垃圾程序员是如何写bug来堆积僵尸进程的,你可以看一下这篇博客https://www.cnblogs.com/linhaifeng/articles/13567273.html系统调用wait()与waitpid()
wait() 系统调用是一个阻塞的调用,也就是说,如果没有子进程是僵尸进程的话,这个调用就一直不会返回,那么整个进程就会被阻塞住,而不能去做别的事了。
Linux 还提供了一个类似的系统调用waitpid(),这个调用的参数更多。其中就有一个参数 WNOHANG,它的含义就是,如果在调用的时候没有僵尸进程,那么函数就马上返回了,而不会像 wait() 调用那样一直等待在那里。
僵尸进程示例代码