机器学习
可能有很多同学想到高大上的人工智能、机器学习和深度学习,会在怀疑我是否能学会。在自我怀疑之前,我希望你能考虑一个问题,你了解机动车的构造原理吗?难道你不了解机动车的构造就不能开车了吗?我们的机器学习也是如此,你只要拿到一张“驾驶证”,你就能很好的应用它,并且能通过本文的学习,快速的为公司、为企业直接创造价值。

机器学习已经不知不觉的走入了我们的生活,我们可能无法干涉它的崛起,也可能无法创建如十大算法一样的算法。但现如今生活的方方面面都有着机器学习的身影,为什么我们不试着去认识它呢,让我们能在机器学习彻底降临之前做好驾驭它的准备呢?

1.1 学习目标
- 了解人工智能、机器学习和深度学习之间的区别
- 掌握机器学习中的监督学习和无监督学习问题
1.2 人工智能
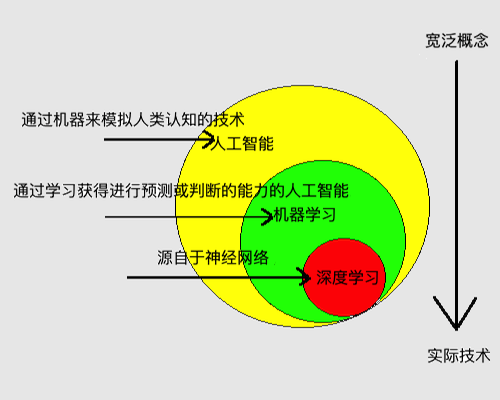
人工智能(artificial intelligence, AI):通过机器来模拟人类认知的技术。
人工智能被新闻媒体吹捧的让人遥不可及,但是细心的你可能会发现人工智能其实已经走入了我们的生活,并且已经步入以下几个领域。
- 人脸识别应用中,他根据输入的照片,判断照片中的人是谁
- 医疗诊断中,他根据输入的医疗影像,判断疾病的成因
- 语音识别中,他根据人说话的音频信号,判断说话的内容
- 电子商务网站中,他根据用户曾经的购买记录,预测用户感兴趣的商品,网站进而达到推荐商品的目的
- 自动驾驶应用中,他根据对当前汽车所处情况的分析,判断汽车接下来的速度和方向
- 金融应用中,他根据股票曾经的价格和其他交易信息,预测股票未来的价格走势
- 围棋对弈中,他根据当前的盘面形式,预测在哪个地方落子胜率最大(2016年3月的alphago大战李世石)
- 基因测序应用中,他根据对人的基因序列的分析,预测这个人未来患病的可能性
- 智能家居、智能玩具、网络安全……
最后,引用《终极算法》中的一段话:"我们可能无法阻挡人工智能发展的趋势,但是我们可以学会和他做朋友。"
1.3 机器学习
机器学习(machine learning):通过学习获得进行预测或判断的能力的人工智能。
机器学习是人工智能实现的一种方法(算法)。他主要是从已知数据中去学习数据中蕴含的规律或者判断规则,也可以理解成把无序的信息变得有序,然后他通过把这种规律应用到未来的新数据上,并对新数据做出判断或预测。
例如某个机器学习算法从全球70亿人类的数据集中学得了某种判断规则,这个判断规则可以通过输入Nick老师的身高180cm、体重70Kg,判断他是个帅哥。

1.3.1 机器学习基本术语
# 机器学习基本术语图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 显示plt.show()的图片,如若不使用jupyter,请注释
%matplotlib inline
# 中文字体设置,找到与之对应的中文字体路径
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
# 样本
plt.text(1, 70, s='{身高(180),体重(70),年龄(19),五官(精致)',
fontproperties=font, fontsize=13, color='g')
plt.annotate(text='样本', xytext=(90, 70), xy=(78, 71), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='特征', xytext=(30, 90), xy=(10, 73), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='', xytext=(30, 90), xy=(30, 73), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='', xytext=(30, 90), xy=(50, 73), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='', xytext=(30, 90), xy=(70, 73), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.hlines(67, 0, 100, linestyle='--', color='gray')
# 特征
plt.text(1, 40, s='{身高(180),体重(70),年龄(19),五官(精致),帅}',
fontproperties=font, fontsize=10, color='g')
plt.annotate(text='样例(实例)', xytext=(90, 40), xy=(70, 41), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='特征', xytext=(30, 60), xy=(8, 43), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='', xytext=(30, 60), xy=(23, 43), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='', xytext=(30, 60), xy=(38, 43), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='', xytext=(30, 60), xy=(53, 43), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='标记', xytext=(67, 60), xy=(67, 43), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.hlines(37, 0, 100, linestyle='--', color='gray')
# 特征空间
plt.text(1, 30, s='$\{(x_1^{(1)},x_1^{(2)},\cdots,x_1^{(n)}),(x_2^{(1)},x_2^{(2)},\cdots,x_2^{(n)}),\cdots,(x_m^{(1)},x_m^{(2)},\cdots,x_m^{(n)})\}$',
fontproperties=font, fontsize=10, color='g')
plt.annotate(text='特征空间($m$个样本)', xytext=(90, 15), xy=(92, 30), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.annotate(text='特征向量($n$维特征)', xytext=(15, 15), xy=(15, 28), ha='center', arrowprops=dict(
arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
plt.xlim(0, 100)
plt.ylim(10, 100)
plt.title('机器学习基本术语图例', fontproperties=font, fontsize=20)
plt.show()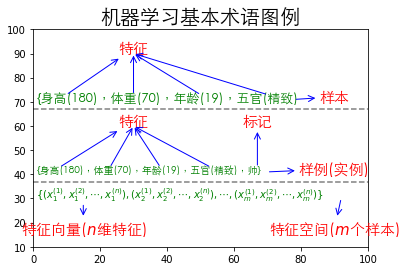
通过上图,我们可以习得以下机器学习的基本术语:
- 特征(feature):描述一件事物的特性,如一个人的身高、体重、年龄和五官。
- 样本(sample):由一个人的特征组成的数据,如${180,70,19,精致}$。
- 标记(label):描述一件事物的特性,如一个人帅或丑、一个人的财富数量。注:特征和标记没有明确的划分,由于问题的不同可能导致A问题的特征是B问题的标记,B问题的标记是A问题的特征。
- 样例(example):由一个人的特征和标记组成的数据,如${180,70,19,精致,帅}$。
- 特征空间(feature space):由${x^{(1)},x^{(2)},\cdots,x^{(n)}}$这n个特征张成的n维空间,如以身高张成的一维空间(线);以身高和体重张成的二维空间(面);以身高、体重和年龄张成的三维空间(体)。
- 特征向量(feature vector):特征空间内的某一个具体的向量,即特种空间中的某一个具体的点,

其中$x_m^{(n)}$表示第m个人的第n个特征。如身高、体重、年龄张成的三维空间中的某一个具体的点$(180,70,19)$。
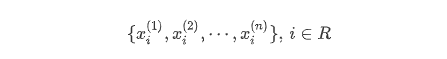
1.4 深度学习
深度学习(deep learning):通过组合低层属性特征形成更加抽象的高层属性特征。如学英语的时候,“Nick handsome”这12个英文单词是低层属性特征,而“Nick handsome”的语义则是抽象的高层属性特征。
插图:恶搞图03

深度学习的概念源于人工神经网络的研究,它属于机器学习中的某一个方法,其中深度学习中的“深度”是指神经网络的层数。

1.5 机器学习分类
机器学习依据数据集数据格式的不同,可以划分成监督学习和无监督学习;依据算法模式的不同可以划分为监督学习、无监督学习、半监督学习和强化学习。
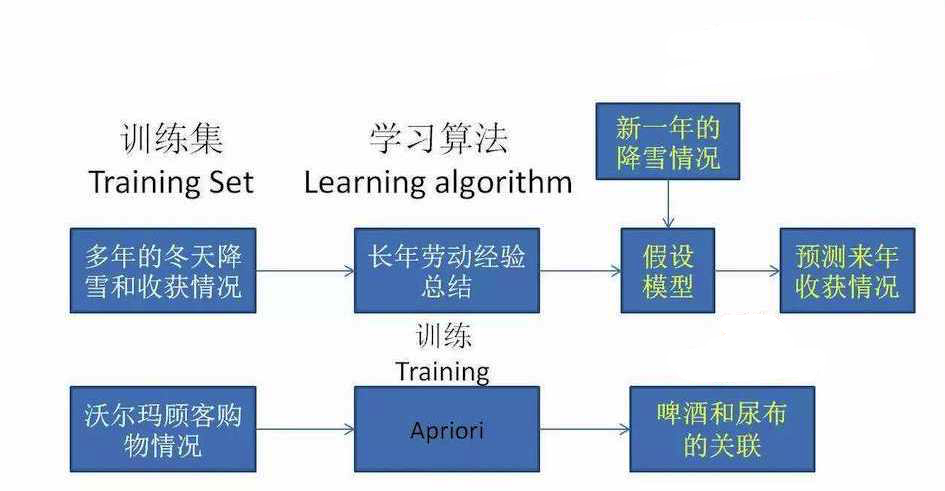
1.5.1 监督学习
监督学习(supervised learning):通过输入一组已知标记的样本,输出一个模型(model),然后通过这个模型预测未来新数据的预测值或预测类别。
监督学习的流程:
- 输入:一组已知类别的样本
- 输出:一个模型
- 预测未来新数据的预测值或预测类别
由于数据标记的类型不同,监督学习问题又分为回归问题和分类问题:
- 如果模型的输出为连续值,如股票价格$2.2,2.4,2.6,3…$类型的数据称为连续值,则该监督学习问题称作回归问题
- 如果模型的输出为离散值,如$阿猫,阿狗,…$或${0,1}$(输出不是$0$就是$1$),则该监督学习问题称作分类问题。
1.5.1.2 回归问题
| 序号 | 房子面积(m$^2$) | 房价(元) |
|---|---|---|
| 1 | 10 | 100 |
| 2 | 20 | 200 |
| 3 | 40 | 400 |
| 4 | 100 | 1000 |
| 5 | 200 | 2000 |
# 回归问题图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
x = np.linspace(0, 200, 10)
y = 10*x
plt.plot(x, y)
plt.xlabel('房子面积', fontproperties=font, fontsize=15)
plt.ylabel('房价', fontproperties=font, fontsize=15)
plt.title('回归问题图例', fontproperties=font, fontsize=20)
plt.show()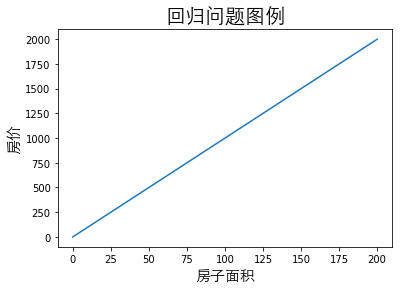
通过上表给出的数据集(一组已知标记的样本)举例,通过数据集中的数据,我们可以假设房子面积和房价之间存在某种关系(模型)为
$$
房价=10房子面积
$$
假设你在得到房子面积和房价之间的关系后,得到了上海二环某一所房子$H_1$的面积为$1000m^2$的消息(未来新数据),这个时候你就可以通过$H_1$的房子面积和房价之间的关系得到这所房子的价格为
$$
H_1的房价=10H_1的房子面积=10*1000=10000(元)\quad\text{预测值}
$$
在这个回归问题中:
- 房子面积称为特征(feature)
- 房价称为标记(label)

1.5.1.3 分类问题
| 序号 | 房子面积(m$^2$) | 房子所在区域 |
|---|---|---|
| 1 | 10 | A区 |
| 2 | 20 | A区 |
| 3 | 40 | A区 |
| 4 | 100 | B区 |
| 5 | 200 | B区 |
# 分类问题图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
a_area = [10, 20, 40]
a_y = [0, 0, 0]
b_area = [100, 200]
b_y = [0, 0]
plt.scatter(a_area, a_y, label='A', color='r')
plt.scatter(b_area, b_y, label='B', color='g')
plt.vlines(50, ymin=-0.015, ymax=0.015, color='gray', linestyles='--')
plt.xlabel('房子面积', fontproperties=font, fontsize=15)
plt.title('分类问题图例', fontproperties=font, fontsize=20)
plt.legend()
plt.show()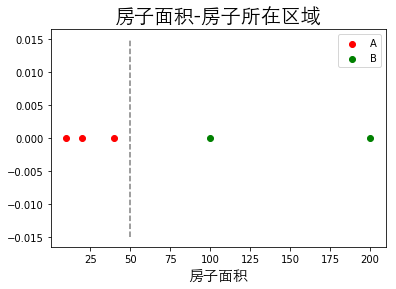
同样通过上表给出的数据集举例,通过数据集的数据,我们可以假设房子面积和房子所在区域存在某种关系为

其中$P(A区|房子面积<50m^2)$为条件概率,即当满足$房子面积<50m^2$条件时房子所在区域为$A区$的概率;$P(B区|房子面积>50m^2)$也为条件概率,当满足$房子面积>50m^2$条件时房子所在区域为$B$区的概率。
假设你在得到房子面积和房子所在区域的关系后,得到了上海二环内两所房子$H_1$和$H_2$面积分别为$30m^2$和$1000m^2$的消息,这个时候你就可以通过房子面积和房子所在区域之间的关系得到这两所房子所在的区域

在这个分类问题中:
- 房子面积称为特征
- 房子所在区域称为标记

1.5.2 无监督学习
无监督学习(unsupervised learning):通过输入一组未知标记的样本,可以通过聚类(clustering)的方法,将数据分成多个簇(cluster)。
无监督学习的流程:
- 输入:一组未知类别的样本
- 输出:分成多个簇的一组样本
1.5.2.1 聚类
聚类(clustering):将数据集分成由类似的数据组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据的集合,同一个簇中的数据彼此相似,不同簇中的对象相异。
需要注意的是,组成多个簇的概念是由某种非人为定义的潜在概念自动生成的,而我们在监督学习中的分类都有明确的定义,即按照房子面积和房价的关系、房子面积和房子所在区域的关系。
| 序号 | 房子面积(m$^2$) |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 40 |
| 4 | 100 |
| 5 | 200 |
通过上表给出的数据集举例,通过聚类可能把数据集中的5个数据分成两个簇,即房子面积大于50的分为一个簇,房子面积小于50的为另一个簇,而这种通过面积分类并不是我们事先设定的,而是由聚类算法自己实现的。也就是说通过聚类把上表的数据集分为两簇,但是我们需要在把数据集分成两个簇后再去决定用什么概念定义这两个簇的划分。

1.5.3 半监督学习
半监督学习(semi-supervised learning):监督学习与无监督学习相结合的一种学习方法。
监督学习和无监督学习的区别主要在于数据集中的数据是否具有标记,当某个问题中的数据集中的数据具有标记时,我们称之为监督学习;反之,我们称之为无监督学习。
目前,由于无监督学习算法的不稳定性,它一般作为中间算法,工业上使用较多的是监督学习算法。但是目前工业上累积较多的是不带标记的数据,因此无监督学习在未来将是一个技术突破的重点目标。为了处理这批不带标记的数据,也有科学家提出了半监督学习,它可以简单的理解为监督学习和无监督学习的综合运用,它即使用带有标记的数据也使用不带有标记的数据。
1.5.4 强化学习
强化学习(reinforcement learning):学习系统从环境到行为映射的学习,目标是使智能体获得最大的奖励,即强化信号最大。
强化学习类似于无监督学习,但是又不同于无监督学习,强化学习针对的是无标记的数据,但是在强化学习算法对无标记的数据进行处理的同时会给出一个特定的目标,如果算法的处理结果偏离目标,则会给出惩罚;反之,给出奖励,而该算法的目标就是为了获得最大奖励。强化学习一般用于无人驾驶。
1.6 Python语言的优势
我们可以通过Python、R、C、Java、MATLAB、Octave等工具实现机器学习算法。本文接下来将通过Python实现,因此在这里简单说说Python的优势:语法清晰简单、易于操作文本文件、优秀的开源社区提供了大量的开源软件库,如scikit-learn、tensorflow等。
本文基于Python3.6+版本,不建议使用Python2.7版本。可以从https://www.python.org/downloads/下载Python。
Anaconda作为Python的科学计算软件包同样非常适合机器学习。可以从https://www.anaconda.com/download/下载Anaconda。
本文使用的机器学习软件库:
- numpy 1.15.2
- scipy 1.1.0
- scikit-learn 0.20.0
- matplotlib 3.0.2
- xlrd 1.2.0
- pandas 0.23.4
- tensorflow 1.1.0
# 终端输入,安装numpy,其他第三库同理
!pip install numpy==1.15.2Requirement already satisfied: numpy==1.15.2 in /Applications/anaconda3/lib/python3.6/site-packages (1.15.2)import numpy
# 打印sklearn的版本
numpy.__version__'1.15.2'1.7 小结
机器学习可以浅显的认为对数据做处理,分析数据得到某种预测或者判断的能力。也就是说,只要有数据产生的地方,就会有机器学习的用武之地。在这个传感器发达的时代,各行各业都积累着大量的数据,因此机器学习其实不仅仅是计算机专业的人需要习得的,就比如最早的专家系统,需要的是某个领域的专家和计算机科学家两者共同努力才能完成一个专家系统。在未来,相信机器学习将会变得和英语一样普及,它将会变得大众化。
本章主要带大家介绍了人工智能、机器学习和深度学习的区别,并通过人体特征带大家了解了机器学习中常用的术语。之后,使用房价/房子所在区域的例子带大家认识了机器学习的目前最流行的四大分类算法,分别是监督学习、无监督学习、半监督学习和强化学习。本章最后也和大家介绍了我们未来需要使用的Python第三方库。
欢迎来到机器学习的世界。
