一 介绍
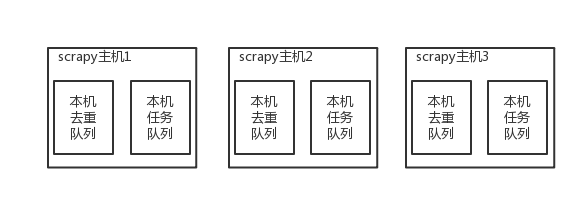
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址)
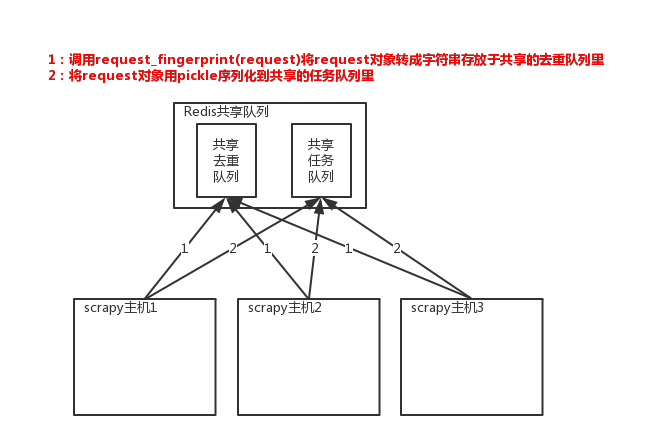
所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
1、共享队列
2、重写Scheduler,让其无论是去重还是任务都去访问共享队列
3、为Scheduler定制去重规则(利用redis的集合类型)
以上三点便是scrapy-redis组件的核心功能
安装:
pip3 install scrapy-redis
源码:
D:\python3.6\Lib\site-packages\scrapy_redis