Docker网络的基本介绍
docker容器是一块具有隔离性的虚拟系统,容器内可以有自己独立的网络空间,
- 多个容器之间是如何实现通信的呢?
- 容器和宿主机之间又是如何实现的通信呢?
- 使用-p参数是怎么实现的端口映射?
带着这些问题,我们来学习一下docker的网络模型,最后我会通过抓包的方式,给大家演示一下数据包在容器和宿主机之间的转换过程。
前置知识
- ip netns 命令用来管理 network namespace。它可以创建命名的 network namespace,然后通过名字来引用 network namespace
- network namespace 在逻辑上是网络堆栈的一个副本,它有自己的路由、防火墙规则和网络设备。 默认情况下,子进程继承其父进程的 network namespace。也就是说,如果不显式创建新的 network namespace,所有进程都从 init 进程继承相同的默认 network namespace。
- 根据约定,命名的 network namespace 是可以打开的 /var/run/netns/ 目录下的一个对象。比如有一个名称为 net1 的 network namespace 对象,则可以由打开 /var/run/netns/net1 对象产生的文件描述符引用 network namespace net1。通过引用该文件描述符,可以修改进程的 network namespace。
网络模式
我们在使用docker run创建Docker容器时,可以用–net选项指定容器的网络模式,Docker有以下4种网络模式:
-
bridge模式,使用–net=bridge指定,默认设置
-
host模式,使用–net=host指定,容器内部网络空间共享宿主机的空间,效果类似直接在宿主机上启动一个进程,端口信息和宿主机共用
-
container模式,使用–net=container:NAME_or_ID指定
指定容器与特定容器共享网络命名空间
-
none模式,使用–net=none指定
网络模式为空,即仅保留网络命名空间,但是不做任何网络相关的配置(网卡、IP、路由等)
bridge模式
那我们之前在演示创建docker容器的时候其实是没有指定的网络模式的,如果不指定的话默认就会使用bridge模式,bridge本意是桥的意思,其实就是网桥模式。
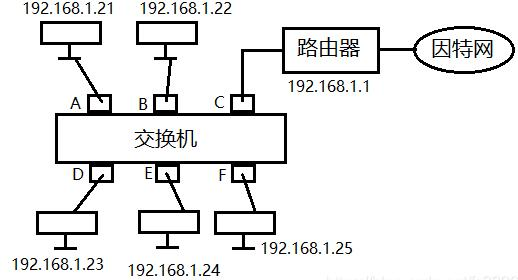
那我们怎么理解网桥,如果需要做类比的话,我们可以把网桥看成一个二层的交换机设备,我们来看下这张图:
交换机通信简图
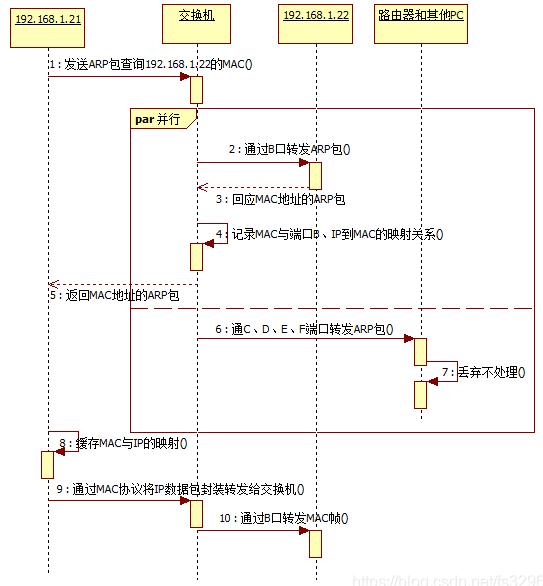
交换机网络通信流程:
网桥模式示意图
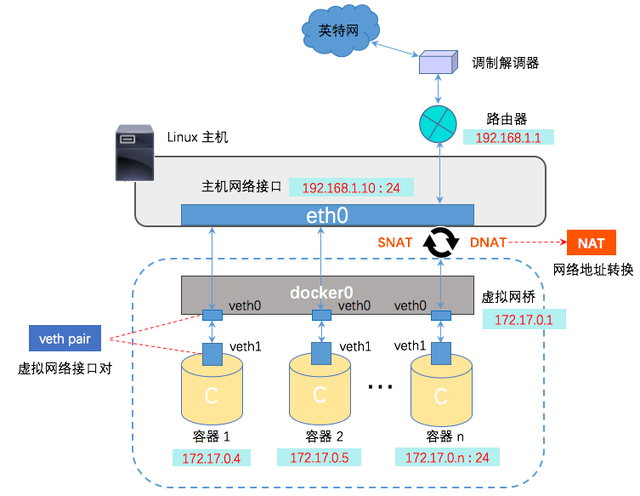
Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge)。它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址将数据包转发到网桥的不同端口上。 网桥在哪,查看网桥
$ yum install -y bridge-utils
$ brctl show
bridge name bridge id STP enabled interfaces
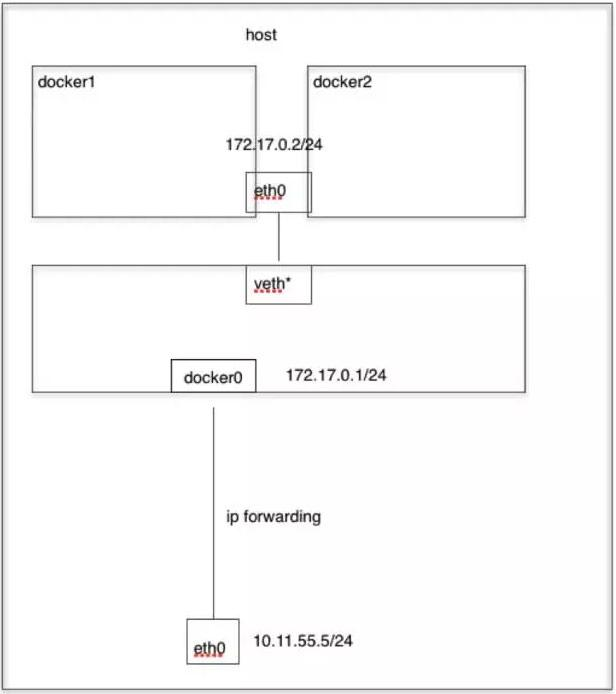
docker0 8000.0242b5fbe57b no veth3a496ed有了网桥之后,那我们看下docker在启动一个容器的时候做了哪些事情才能实现容器间的互联互通
Docker 创建一个容器的时候,会执行如下操作:
- 创建一对虚拟接口/网卡,也就是veth pair;
- veth pair的一端桥接 到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 vethxxxxxx;
- veth paid的另一端放到新启动的容器内部,并修改名字作为 eth0,这个网卡/接口只在容器的命名空间可见;
- 从网桥可用地址段中(也就是与该bridge对应的network)获取一个空闲地址分配给容器的 eth0
- 配置容器的默认路由
那整个过程其实是docker自动帮我们完成的,清理掉所有容器,来验证。
## 清掉所有容器
$ docker rm -f `docker ps -aq`
$ docker ps
$ brctl show # 查看网桥中的接口,目前没有
## 创建测试容器test1
$ docker run -d --name test1 nginx:alpine
$ brctl show # 查看网桥中的接口,已经把test1的veth端接入到网桥中
$ ip a |grep veth # 已在宿主机中可以查看到
$ docker exec -ti test1 sh
/ # ifconfig # 查看容器的eth0网卡及分配的容器ip
# 再来启动一个测试容器,测试容器间的通信
$ docker run -d --name test2 nginx:alpine
$ docker exec -ti test2 sh
/ # sed -i 's/dl-cdn.alpinelinux.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apk/repositories
/ # apk add curl
/ # curl 172.17.0.8:80
## 为啥可以通信?
/ # route -n #
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
# eth0 网卡是这个容器里的默认路由设备;所有对 172.17.0.0/16 网段的请求,也会被交给 eth0 来处理(第二条 172.17.0.0 路由规则),这条路由规则的网关(Gateway)是 0.0.0.0,这就意味着这是一条直连规则,即:凡是匹配到这条规则的 IP 包,应该经过本机的 eth0 网卡,通过二层网络(数据链路层)直接发往目的主机。
# 而要通过二层网络到达 test1 容器,就需要有 172.17.0.8 这个 IP 地址对应的 MAC 地址。所以test2容器的网络协议栈,就需要通过 eth0 网卡发送一个 ARP 广播,来通过 IP 地址查找对应的 MAC 地址。
#这个 eth0 网卡,是一个 Veth Pair,它的一端在这个 test2 容器的 Network Namespace 里,而另一端则位于宿主机上(Host Namespace),并且被“插”在了宿主机的 docker0 网桥上。网桥设备的一个特点是插在桥上的网卡都会被当成桥上的一个端口来处理,而端口的唯一作用就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥设备处理。
# 因此ARP的广播请求也会由docker0来负责转发,这样网桥就维护了一份端口与mac的信息表,因此针对test2的eth0拿到mac地址后发出的各类请求,同样走到docker0网桥中由网桥负责转发到对应的容器中。
# 网桥会维护一份mac映射表,我们可以大概通过命令来看一下,
$ brctl showmacs docker0
## 这些mac地址是主机端的veth网卡对应的mac,可以查看一下
$ ip a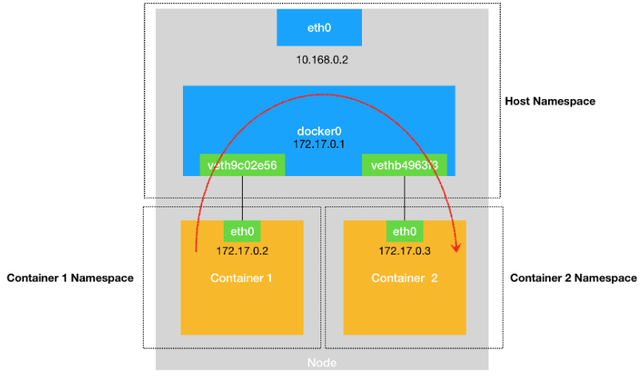
我们如何知道网桥上的这些虚拟网卡与容器端是如何对应?
通过ifindex,网卡索引号
## 查看test1容器的网卡索引
$ docker exec -ti test1 cat /sys/class/net/eth0/ifindex
## 主机中找到虚拟网卡后面这个@ifxx的值,如果是同一个值,说明这个虚拟网卡和这个容器的eth0网卡是配对的。
$ ip a |grep @if整理脚本,快速查看对应:
for container in $(docker ps -q); do
iflink=`docker exec -it $container sh -c 'cat /sys/class/net/eth0/iflink'`
iflink=`echo $iflink|tr -d '\r'`
veth=`grep -l $iflink /sys/class/net/veth*/ifindex`
veth=`echo $veth|sed -e 's;^.*net/\(.*\)/ifindex$;\1;'`
echo $container:$veth
done上面我们讲解了容器之间的通信,那么容器与宿主机的通信是如何做的?
添加端口映射:
## 启动容器的时候通过-p参数添加宿主机端口与容器内部服务端口的映射
$ docker run --name test -d -p 8088:80 nginx:alpine
$ curl localhost:8088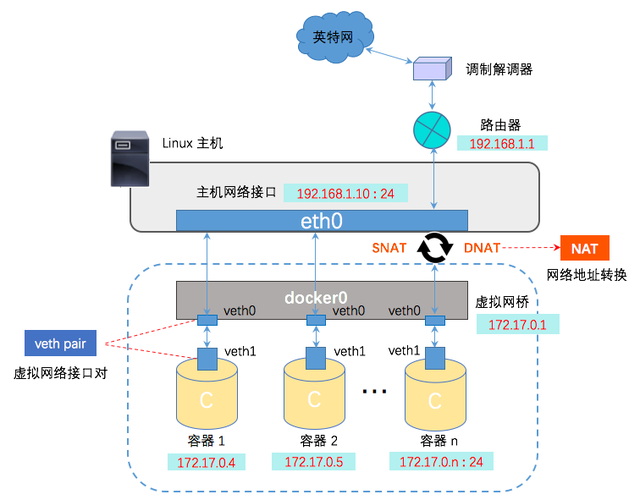
端口映射如何实现的?先来回顾iptables链表图
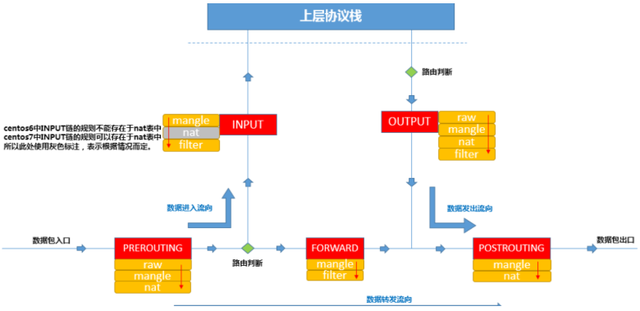
访问本机的8088端口,数据包会从流入方向进入本机,因此涉及到PREROUTING和INPUT链,我们是通过做宿主机与容器之间加的端口映射,所以肯定会涉及到端口转换,那哪个表是负责存储端口转换信息的呢,就是nat表,负责维护网络地址转换信息的。因此我们来查看一下PREROUTING链的nat表:
$ iptables -t nat -nvL PREROUTING
Chain PREROUTING (policy ACCEPT 159 packets, 20790 bytes)
pkts bytes target prot opt in out source destination
3 156 DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL规则利用了iptables的addrtype拓展,匹配网络类型为本地的包,如何确定哪些是匹配本地,
$ ip route show table local type local
127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
172.17.0.1 dev docker0 proto kernel scope host src 172.17.0.1
172.21.51.143 dev eth0 proto kernel scope host src 172.21.51.143也就是说目标地址类型匹配到这些的,会转发到我们的TARGET中,TARGET是动作,意味着对符合要求的数据包执行什么样的操作,最常见的为ACCEPT或者DROP,此处的TARGET为DOCKER,很明显DOCKER不是标准的动作,那DOCKER是什么呢?我们通常会定义自定义的链,这样把某类对应的规则放在自定义链中,然后把自定义的链绑定到标准的链路中,因此此处DOCKER 是自定义的链。那我们现在就来看一下DOCKER这个自定义链上的规则。
$ iptables -t nat -nvL DOCKER
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- docker0 * 0.0.0.0/0 0.0.0.0/0
0 0 DNAT tcp -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8088 to:172.17.0.2:80此条规则就是对主机收到的目的端口为8088的tcp流量进行DNAT转换,将流量发往172.17.0.2:80,172.17.0.2地址是不是就是我们上面创建的Docker容器的ip地址,流量走到网桥上了,后面就走网桥的转发就ok了。 所以,外界只需访问172.21.51.143:8088就可以访问到容器中的服务了。
数据包在出口方向走POSTROUTING链,我们查看一下规则:
$ iptables -t nat -nvL POSTROUTING
Chain POSTROUTING (policy ACCEPT 1099 packets, 67268 bytes)
pkts bytes target prot opt in out source destination
86 5438 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0
0 0 MASQUERADE tcp -- * * 172.17.0.4 172.17.0.4 tcp dpt:80大家注意MASQUERADE这个动作是什么意思,其实是一种更灵活的SNAT,把源地址转换成主机的出口ip地址,那解释一下这条规则的意思:
这条规则会将源地址为172.17.0.0/16的包(也就是从Docker容器产生的包),并且不是从docker0网卡发出的,进行源地址转换,转换成主机网卡的地址。大概的过程就是ACK的包在容器里面发出来,会路由到网桥docker0,网桥根据宿主机的路由规则会转给宿主机网卡eth0,这时候包就从docker0网卡转到eth0网卡了,并从eth0网卡发出去,这时候这条规则就会生效了,把源地址换成了eth0的ip地址。
注意一下,刚才这个过程涉及到了网卡间包的传递,那一定要打开主机的ip_forward转发服务,要不然包转不了,服务肯定访问不到。
抓包演示
我们先想一下,我们要抓哪个网卡的包
-
首先访问宿主机的8088端口,我们抓一下宿主机的eth0
$ tcpdump -i eth0 port 8088 -w host.cap -
然后最终包会流入容器内,那我们抓一下容器内的eth0网卡
# 容器内安装一下tcpdump $ sed -i 's/dl-cdn.alpinelinux.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apk/repositories $ apk add tcpdump $ tcpdump -i eth0 port 80 -w container.cap到另一台机器访问一下,
$ curl 172.21.51.143:8088/停止抓包,拷贝容器内的包到宿主机
$ docker cp test:/root/container.cap /root/把抓到的内容拷贝到本地,使用wireshark进行分析。
$ scp root@172.21.51.143:/root/*.cap /d/packages(wireshark合并包进行分析)
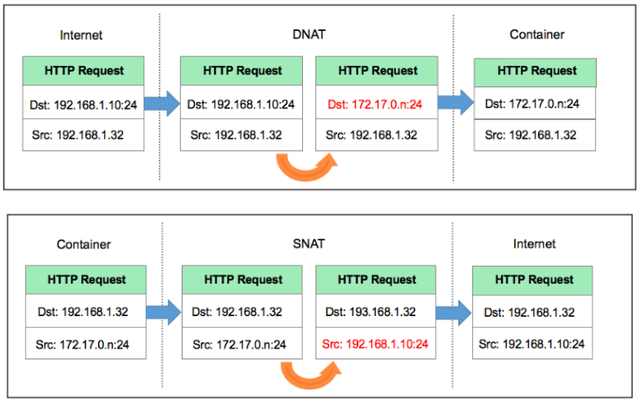
进到容器内的包做DNAT,出去的包做SNAT,这样对外面来讲,根本就不知道机器内部是谁提供服务,其实这就和一个内网多个机器公用一个外网IP地址上网的效果是一样的,那这也属于NAT功能的一个常见的应用场景。
Host模式
容器内部不会创建网络空间,共享宿主机的网络空间。比如直接通过host模式创建mysql容器:
$ docker run --net host -d --name mysql -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7容器启动后,会默认监听3306端口,由于网络模式是host,因为可以直接通过宿主机的3306端口进行访问服务,效果等同于在宿主机中直接启动mysqld的进程。
Conatiner模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
## 启动测试容器,共享mysql的网络空间
$ docker run -ti --rm --net=container:mysql busybox sh
/ # ip a
/ # netstat -tlp|grep 3306
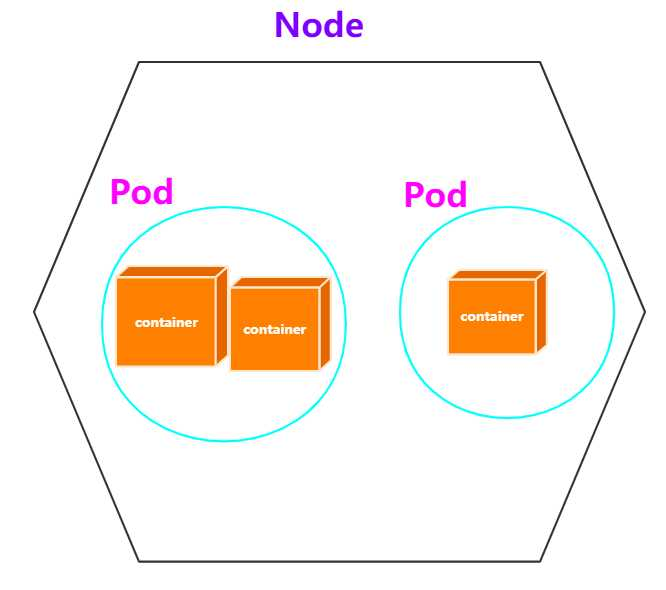
/ # telnet localhost 3306在一些特殊的场景中非常有用,例如,kubernetes的pod,kubernetes为pod创建一个基础设施容器,同一pod下的其他容器都以container模式共享这个基础设施容器的网络命名空间,相互之间以localhost访问,构成一个统一的整体。
None模式
只会创建对应的网络空间,不会配置网络堆栈(网卡、路由等)。
# 创建none的容器
$ docker run -it --name=network-none --net=none nginx:alpine sh
# ifconfig在宿主机中操作:
# 创建虚拟网卡对
$ ip link add A type veth peer name B
# A端插入到docker0网桥
$ brctl addif docker0 A
$ ip link set A up
# B端插入到network-none容器中,需要借助ip netns,因此需要显示的创建命名network namespace
$ PID=$(docker inspect -f '{{.State.Pid}}' network-none)
$ mkdir -p /var/run/netns
$ ln -s /proc/$PID/ns/net /var/run/netns/$PID
# B端放到容器的命名空间
$ ip link set B netns $PID
$ ip netns exec $PID ip link set dev B name eth0 # 修改设备名称为eth0,和docker默认行为一致
$ ip netns exec $PID ip link set eth0 up
# 设置ip
$ ip netns exec $PID ip addr add 172.17.0.100/16 dev eth0
# 添加默认路由,指定给docker0网桥
$ ip netns exec $PID ip route add default via 172.17.0.1
# 测试容器间通信