数据操作
本章学习内容:
- 数据导入、存储
- 数据处理
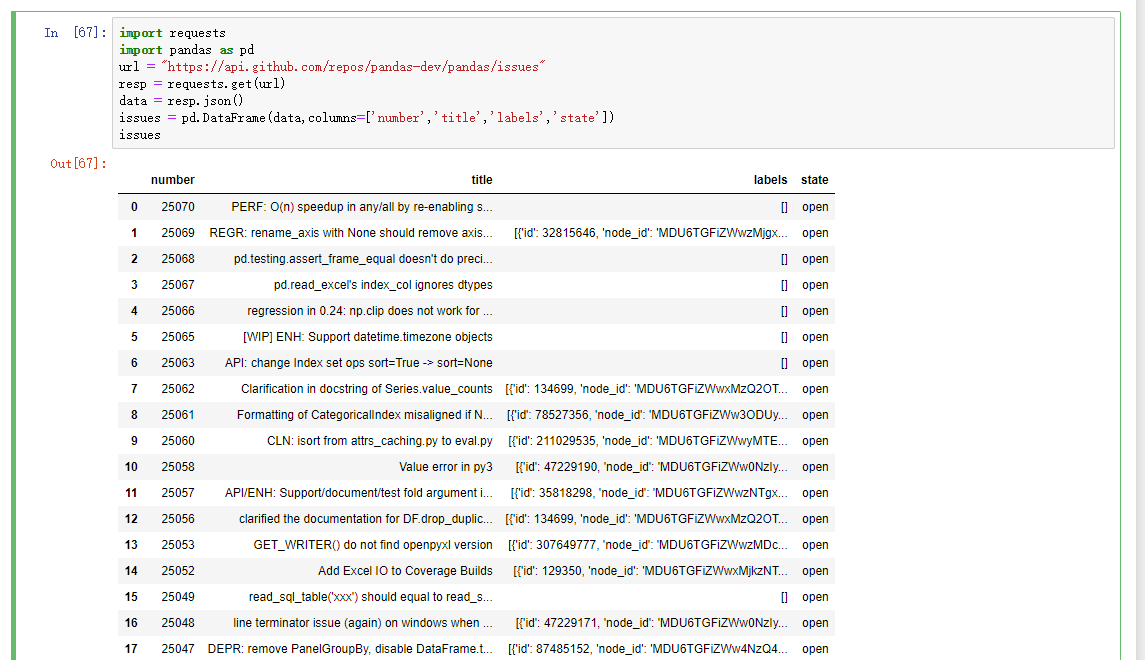
数据操作最重要的一步也是第一步就是收集数据,而收集数据的方式有很多种,第一种就是我们已经将数据下载到了本地,在本地通过文件进行访问,第二种就是需要到网站的API处获取数据或者网页上爬取数据,还有一种可能就是你的公司里面有自己的数据库,直接访问数据库里面的数据进行分析。需要注意的是我们不仅需要将数据收集起来还要将不同格式的数据进行整理,最后再做相应的操作。

1、数据导入、存储
访问数据是数据分析的所必须的第一步,只有访问到数据才可以对数据进行分析。
1.1、文本格式
常用pandas解析函数:
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。以下
| 函数 | 描述 | |
|---|---|---|
| read_csv | 从文件、url或者文件型对象读取分割好的数据,逗号是默认分隔符 | |
| read_table | 从文件、url或者文件型对象读取分割好的数据,制表符(‘\t’)是默认分隔符 | |
| read_fwf | 读取定宽格式数据(无分隔符) | |
| read_clipboard | 读取剪贴板中的数据,可以看做read_table的剪贴板。再将网页转换为表格 | |
| read_excel | 从Excel的XLS或者XLSX文件中读取表格数据 | |
| read_hdf | 读取pandas写的HDF5文件 | |
| read_html | 从HTML文件中读取所有表格数据 | |
| read_json | 从json字符串中读取数据 | |
| read_pickle | 从Python pickle格式中存储的任意对象 | |
| read_msgpack | 二进制格式编码的pandas数据 | |
| read_sas | 读取存储于sas系统自定义存储格式的SAS数据集 | |
| read_stata | 读取Stata文件格式的数据集 | |
| read_feather | 读取Feather二进制文件格式 | |
| read_sql | 将SQL查询的结果(SQLAlchemy)读取为pandas的DataFrame |

我们可以通过上表对这些解析函数有一个简单了解,其中read_csv和read_table是以后用得最多的两个方法,接下来我们主要就这两个方法测试。
(1)、read_csv
csv文件就是一个以逗号分隔字段的纯文本文件,用于测试的文件是本身是一个Excel文件,需要修改一下扩展名,但是简单的修改后缀名不行,还需要将字符编码改变为utf-8,因为默认的是ASCII,否则是会报错的。然后就可以通过read_csv将它读入到一个DataFrame:
import pandas as pd
df = pd.read_csv("E:/Test/test3.csv")
df
name age sex
0 佩奇 18 女
1 乔治 19 男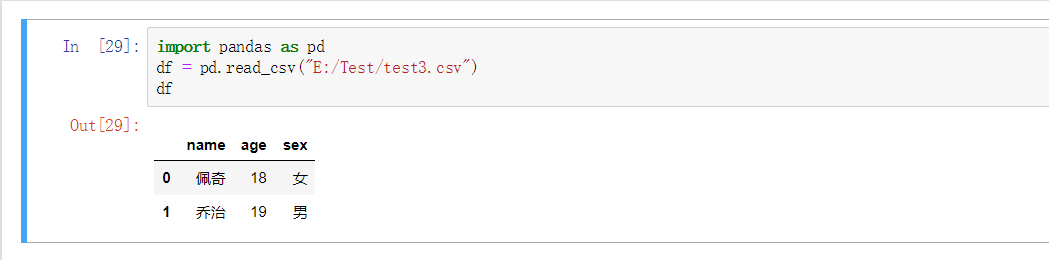
注意:
到这里可能就会有些人有疑问了,为什么我的文件路径不对啊,那是因为在我们这个方法当中的路径当它往左斜的时候需要用双斜杠,否则就要使用右斜杠
(2)、read_table
还可以使用read_table,并且指定分隔符
import pandas as pd
df = pd.read_csv("E:/Test/test3.csv")
df
name age sex
0 佩奇 18 女
1 乔治 19 男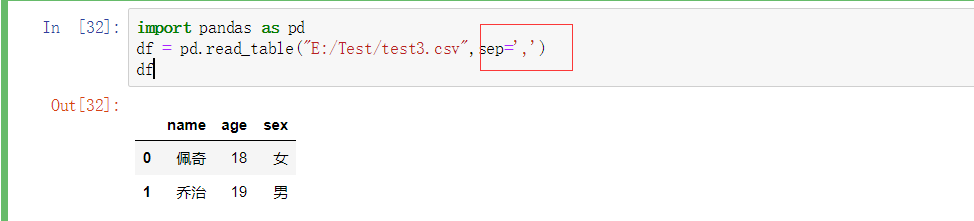
如果不指定分隔符,它的数据之间会有逗号。
以上只是简单的读取操作,
指定列名
pandas可以帮助我们自动分配列名,也可以自己指定列名
默认列名
import pandas as pd
df = pd.read_csv("E:/Test/test.csv",header=None)
df
0 1 2 3 4 5
0 a b c d e f
1 g h i j k l
2 m n o p q r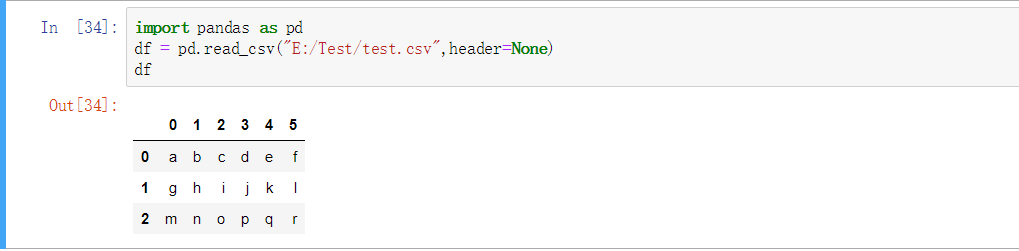
指定列名
import pandas as pd
df = pd.read_csv("E:/Test/test.csv",names=['数','据','分','析','真','好','玩'])
df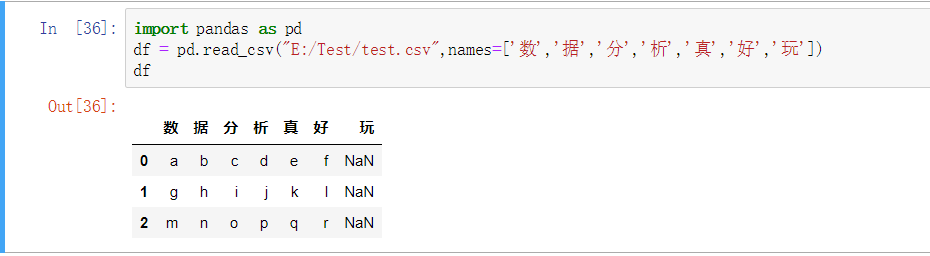
具体还有那些参数,通过表格展示一下,这些参数是read_csv和read_table共有的
| 参数 | 描述 | |
|---|---|---|
| path | 表明文件系统位置的字符串、URL或者文件型对象 | |
| sep或delimiter | 用于分隔每行字段的字符序列或正则表达式 | |
| header | 用作列名的行号,默认是0(第一行),如果没有为None | |
| names | 结果的列名列表,和header=None一起用 | |
| skiprows | 从文件开头起,需要跳过的行数或者行号列表 | |
| na_values | 用NA替换的值序列(可以用来处理缺失值) | |
| data_parser | 用于解析日期的函数 | |
| nrows | 从文件开头处读取的行数 | |
| chunksize | 用于设置迭代的块大小 | |
| encoding | 设置文本编码 |
分块读取文件