基本数据类型
一 数据类型的由来
数据是程序的核心,所有的程序都是围绕数据的操作展开的。
站在程序员的角度,程序中的数据是用来控制计算机硬件记录下并且表达出事物状态的,记录越方便、表达越清晰,程序员的开发将会越方便。
站在计算机底层硬件的角度去看待数据,数据当然全都是由bit位组成的。为了能够记录下多种状态,数据不是由单个bit位而是由一系列的bit位组成的,并且为了能够准确地读取,组成数据的bit位个数/长度固定,所以计算机一般操作的是固定大小的数,如整数、浮点数、比特数组、内存地址。进一步将这个固定大小的数组织在一起并加以命名,就可以记录下并且很好地表达出更多的状态(比如人的年龄、身高、姓名等),这就是编程语言中数据类型的由来。Go语言提供了丰富的数据类型,这些内置的数据类型,兼顾了硬件的特性和表达复杂数据结构的便捷性。
程序中 计算机内存中
程序员————>某种类型的数据———> 0101010101
// 例如:要求能够在计算机中记录下人的年龄、身高、姓名等状态,并且能够在程序中很好地表达出来这些状态,以方便程序员的开发。
程序员————> 人的年龄int ————> 0101010111...
程序员————> 人的身高float32 ————> 0101011101...
程序员————> 人的姓名string ————> 1111111111... go属于强类型语言,特定类型的数据会在编译时就确定好内存空间大,这样程序运行时效率就高了,不用费心重新申请内存
二 基本数据类型介绍
Go语言的基本数据类型主要分为三大类
- 1、数字类型
- 整型: int8、 int16、 int、 uint、 uintptr等
- 浮点型: float32、 float64
- 复数: complex64、 complex128
- 2、字符串类型:string,字符类型:byte、rune
- 3、布尔型:bool
三 数字类型之整型
3.1 有符号与无符号整型
Go语言中提供了不同类型的整型,主要分为有符号和无符号两大类
| 类型 | 描述 |
|---|---|
| uint8 | 无符号 8位整型 (0 到 255),对应go语言的byte类型 |
| uint16 | 无符号 16位整型 (0 到 65535) |
| uint32 | 无符号 32位整型 (0 到 4294967295) |
| uint64 | 无符号 64位整型 (0 到 18446744073709551615) |
| int8 | 有符号 8位整型 (-128 到 127) |
| int16 | 有符号 16位整型 (-32768 到 32767),对应C语言中的short类型 |
| int32 | 有符号 32位整型 (-2147483648 到 2147483647),对应go语言的rune类型 |
| int64 | 有符号 64位整型 (-9223372036854775808 到 9223372036854775807),对应C语言中的long类型 |
// 例:
var age uint8
age = 256 // 溢出,抛出异常:constant 256 overflows uint83.2 特殊整型
此外还有三个特殊的整型,其中int是所有整型里应用最广泛的,也是类型推导的默认类型。
| 类型 | 描述 |
|---|---|
| uint | 在32位平台下大小与unit32一样, 64位平台下大小与unit64一样 |
| int | 在32位平台下大小与int32一样, 64位平台下大小与int64一样 |
| uintptr | 无符号整型,没有指定具体的bit大小但是足以容纳指针,所以uintptr通常用于存放一个指针。uintptr类型只有在底层编程是才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方 |
注意事项
1、len()返回的是一个int类型,实际使用中,切片或 map 的元素数量等都可以用int来表示。
2、在涉及到二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和 uint。
3.3 数据类型转换
go语言是强类型语言,数据类型有明确的边界,比如,即便int在某一平台的大小为32位,int和int32依然不同的类型。在需要将int当作int32类型的地方编译器也不会帮我们自动做类型转换/隐式转换,需要我们自己做显式的类型转换操作/强制转换,反之亦然,
go语言提供了强制类型转换的语法:T(x),只允许兼容类型之间进行转换
对于每种类型T,如果转换允许的话,可以用强制类型转换操作T(x)将x转换为T类型(其中,T表示要转换的类型。x为表达式,包括变量、复杂算子和函数返回值等.)许多整形数之间的相互转换并不会改变数值;它们只是告诉编译器如何解释这个值,如下
// 例1:
var x int32
y := 666 // y将会被自动推导为int类型
// x = y // 编译错误,因为y是int类型,而x是int32类型,所以无法将y的值赋值给x
x = int32(y) // 使用强制类型转换可以解决上述错误,此处并没有改变y的值,只是告诉了编译器y的类型为int32,与x的类型保存一致,因此可以赋值
// 例如2:
var apples int32 = 1
var oranges int16 = 2
//var compote int = apples + oranges // 编译错误:算术和逻辑运算的二元操作中必须是相同的类型。
var compote = int(apples) + int(oranges) // 需要一个显式的转换将一个值从一种类型转化位另一种类型,虽然这偶尔会导致需要很长的表达式,但是它消除了所有和类型相关的问题,而且也使得程序容易理解。
fmt.Println(compote) // 3但是对于将一个大尺寸的整数类型转为一个小尺寸的整数类型(值溢出,应该尽量避免),或者是将一个浮点数转为整数,可能会改变数值或丢失精度,如下
f := 3.931 // f将会被自动推导为float64类型
i := int(f)
fmt.Println(f, i) // "3.931 3"
f = 1.99
fmt.Println(int(f)) // "1"另外,对于两个不同类型的整数型不能直接比较,但各种类型的整型变量都可以直接与字面常量进行比较,如下
var i int32
var j int64
i, j = 1, 2
if i == j { //编译错误
fmt.Println("i and j are equal.")
}
if i == 1 || j == 2 { //编译通过
fmt.Println("i and j are equal.")
}3.4 数字字面量语法(Number literals syntax)
Go1.13版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:
// 无前缀代表十进制
v:=10
// 以0b为前缀的二进制
v := 0b00101101
// 以0o为前缀的八进制
v := 0o711
// 以0x为前缀的十六进制
v := 0xap-2,代表十六进制的 a 除以 2²,也就是十进制的10/4得 2.5。
// 而且还允许我们用 _ 来分隔数字
v := 123_456 等于 123456。我们可以借助fmt函数来将一个整数以不同进制形式展示。
x:=57
//x:=0b111001
//x:=0o71
//x:=0x39
// 输出(不带前缀)
fmt.Printf("%d\n",x) // 57
fmt.Printf("%b\n",x) // 111001
fmt.Printf("%o\n",x) // 71
fmt.Printf("%x\n",x) // 39
// 输出(带前缀)
fmt.Printf("%#d\n",x) // 57
fmt.Printf("%#b\n",x) // 0b111001
fmt.Printf("%#o\n",x) // 071
fmt.Printf("%#x\n",x) // 0x39
// [1]代表取得是第一个操作数,[2]代表取得是第二个操作数
x:=57
y:=33
fmt.Printf("%[1]d %[1]b %[1]o %[1]x,%[2]d %[2]b %[2]o %[2]x ",x,y)四 数字类型之浮点型
Go语言提供了两种精度的浮点数,单精度float32和双精度float64。它们的算术规范由IEEE754浮点数国际标准定义,该浮点数规范被所有现代的CPU支持。
| 类型 | 范围 |
|---|---|
| float32 | 最小近似值1.4e-45 最大近似值大约是3.4e38,具体可以通过math.MaxFloat32查看 |
| float64 | 最小近似值4.9e-324 最大近似值大约是1.8e308,具体可以通过math.MaxFloat64查看 |
通常应该优先使用float64,因float64的精度以及表示的正整数范围都要比float32大,并且类型推导的浮点型默认就是float64
// 例1
z:=3.1415926
fmt.Printf("%T\n", z) // float64
fmt.Printf("%8.3f\n", z) // 总宽度为8,保留3位小数(四舍五入),不够在左侧填充空格
// 例2
var x float32 = 12
y:=12.0 // y被推导出的类型是float64,而不管赋给它的数字是否是用32位长度表示的,注意如果不加小数点,y会被推导为整型而不是浮点型
fmt.Printf("%[1]T %.2[1]f\n",x) // float32 12.00
fmt.Printf("%[1]T %.2[1]f\n",y) // float64 12.00因此,对于以上的例子,下面的赋值将导致编译错误:
y = x必须强制类型转换
y = float64(x)浮点数比较
因为浮点数不是一种精确的表达方式,所以像整型那样直接用==来判断两个浮点数是否相等
是不可行的,这可能会导致不稳定的结果,例如
package main
import (
"fmt"
)
func main() {
x := 0.1
y := 0.2
res := x + y
fmt.Println(res) // 0.30000000000000004
fmt.Println(res == 0.3) // false
}浮点数的精度问题与解决方案详见《附录:浮点数的精度问题》
了解:浮点数里有个叫非数的东西
fmt.Println(math.NaN()) // NaN
var z float32
fmt.Println(z) // 0
fmt.Println(z/z) // NaN
x:=z/z
fmt.Println(x < x) // false
fmt.Println(x > x) // false
fmt.Println(x == x) // false
fmt.Println(x != x) // true五 数字类型之复数
Go语言提供了两种精度的复数类型:complex64和complex128,复数实际上由两个实数(在计算机中用浮点数表示,complex64对应的是float32,complex128对应的是float64)构成,一个表示实部(real),一个表示虚部(imag)。内置的complex函数用于构建复数,内建的real和imag函数分别返回复数的实部和虚部:
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"如果一个浮点数面值或一个十进制整数面值后面跟着一个i,例如3.141592i或2i,它将构成一个复数的虚部,复数的实部是0:
fmt.Println(1i * 1i) // i^2 = -1 ,实部为-1,虚部为0,结果记为复数形式(-1+0i)
在常量算术规则下,一个复数常量可以加到另一个普通数值常量(整数或浮点数、实部或虚部),我们可以用自然的方式书写复数,就像1+2i或与之等价的写法2i+1。上面x和y的声明语句还可以简化:
x := 1 + 2i
y := 3 + 4i复数也可以用==和!=进行相等比较。只有两个复数的实部和虚部都相等的时候它们才是相等的(译注:浮点数的相等比较是危险的,需要特别小心处理精度问题)。
math/cmplx包提供了复数处理的许多函数,例如求复数的平方根函数和求幂函数,更多关于复数的函数,请查阅math/cmplx标准库的文档。
fmt.Println(cmplx.Sqrt(-1)) // "(0+1i)"六 字符串
在 C/C++语言中,并不存在原生的字符串类型,它们通常使用字符数组来表示出字符串的概念,并以字符指针来传递。而在Go语言中,字符串也是一种基本类型,就像其他数据类型(int、bool、float32、float64等)一样。
Go语言中,字符串底层是一个由字节(byte)组成的数组,再次强调:底层数组内存放的是字节byte。
字符串的值需要用双引号包含,双引号内通常是字符串字面量,即人类从字面上就可以读懂的文本字符,比如
var msg string = "hello, 世界" // go会将字面量的文本字符编码成utf-8格式的字节byte然后存入底层数组,一个英文字符占一个byte,一个中文字符占3个byte 但其实双引号内可以是任意内容,无论存什么内容,在打印字符串时会从底层数组取出byte然后按照utf-8格式解码成字符
// 0、先储备一个知识点
一个字节=8个bit位
对应十进制最大为255
对应的十六进制最大为0xff
对应的八进制最大为\377(go中\开头代表八进制,不要写成\o377)
// 1、双引号内是八进制数构成的字符串
s1:="\110\151" // 底层数组存放的第一个字节是\110,第二个字节是\151
fmt.Println(s1) // Hi
fmt.Println(len(s1)) // 2个字节
// 2、双引号内是十六进制数构成的字节
s2:="\xe5\xb3\xb0\xe5\x93\xa5" // 底层数组存放的第一个字节是\xe5,第二个字节是\xb3,依次类推...
fmt.Println(s2) // 峰哥
fmt.Println(len(s2)) // 6个字节
// 3、双引号内:\u指的是遵循UCS-2标准的unicode,\U指的是遵循UCS-4标签的unicode
s3:="\u771f\U00005e05" // \u771f解码成utf-8编码后对应三个字节,依次存入底层数据,\U...一样
fmt.Println(s3) // 真帅
fmt.Println(len(s3)) // 6个字节
// 4、双引号内是字符串面值
s4:="en说的对" // go会将字符串面值编码成utf-8格式,然后将得到的byte依次存入底层数组
fmt.Println(s4) // en说的对
fmt.Println(len(s4)) // 11个字节
// 双引号内完全可以同时容纳上1、2、3、4所述的内容,甚至顺序都无所谓,因为字符串就是一个字节序列的数组,至于数组内存的是什么字节byte是无所谓的,但问题出就出在,当我们打印字符串的时候,go会将字符串底层数组中的byte取出来,然后按照utf-8个的格式解码成字符,如果byte非法,那么解码出的字符是一个黑色六角或钻石形状,里面包含一个白色的问号(?)
s5:="\372\xee\xe5\xb3\xb0\xe5\x93\xa5" // 前2个字节都是非法的,后6个合法
fmt.Println(s5) // ��峰哥
fmt.Println(len(s5)) // 8个字节ps:有一些字符串面值的字符比较特殊,我们用的输入法工具很难输入,有一些甚至是不可见的字符,此时可以在Go语言的字符串面值中,通过使用转义字符加上Unicode码点的方式来输入特殊的字符(如上例1、2、3、4所示)。unicode遵循两种标准UCS-2和UCS-4,UCS-2用两个字节编码(\u对应UCS-2),UCS-4用4个字节编码(\U对应UCS-4)。\uhhhh对应16bit的码点值,\Uhhhhhhhh对应32bit的码点值,其中h是一个十六进制数字;一般常用的是16bit的形式,很少需要使用32bit的形式,这正如我们常说的那样,unicode通常用两个字节表示一个字符。
索引操作
s:="hi你好呀"
// 根据索引取出的是第n个字节,而非字符
fmt.Println(s[0]) // 104
//fmt.Println(s[len(s1)]) // 超出字符串索引范围导致panic异常
//fmt.Println(s[-1]) // 不支持负向索引导致panic异常
// ps:
go中s[i]访问的都是第i个字节而不是字符,因为go的字符串s用的是utf-8编码,是变长的,而变长的编码无法通过索引操作确定字符占用字节的个数,所以只能取字节了,这是它的缺点:
而python中s[i]访问的都是第i个字符,因为python3中字符串用是unicode编码,是定长的取子字符串
s1:="hi你好呀"
// 此处取的是子字符串,而不是字节,所以打印结果会被解码成字符
// 顾头不顾尾
fmt.Println(s1[0]) // 104
fmt.Println(string(s1[0])) // h
fmt.Println(s1[0:1]) // h
fmt.Println(s1[0:2]) // hi
fmt.Println(s1[0:3]) // hi�
fmt.Println(s1[0:4]) // hi�
fmt.Println(s1[0:5]) // hi你
fmt.Println(s1[:5]) // hi你,默认从0开始
fmt.Println(s1[2:]) // 你好呀,默认到末尾
fmt.Println(s1[:]) // hi你好呀,默认从头到末尾字符串不可修改
s:="hi你好呀"
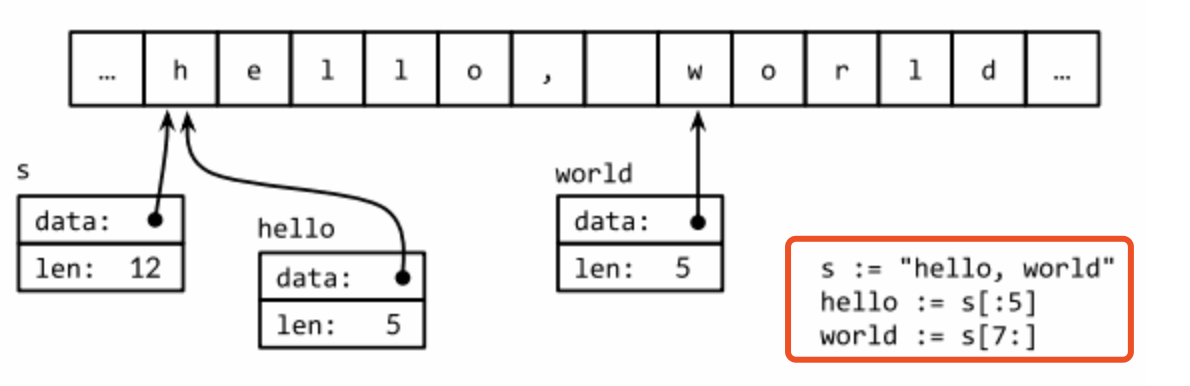
s[0] = 'L' // 编译错误: cannot assign to s[0]不变性意味如果两个字符串共享相同的底层数据的话也是安全的,这使得
-
1、复制任何长度的字符串代价是低廉的。
-
2、同样,一个字符串s和对应的子字符串切片s[7:]的操作也可以安全地共享相同的内存,因此字符串切片操作代价也是低廉的。
在这两种情况下都没有必要分配新的内存。 下图演示了一个字符串和两个字串共享相同的底层数据。
转义符号
在一个双引号包含的字符串面值中,可以用以反斜杠\开头的转义序列插入任意的数据。下面的换行、回车和制表符等是常见的ASCII控制代码的转义方式:
\n 换行
\r 回车
\t 制表符
\" 双引号
\\ 反斜杠
// 例如
fmt.Println("file_path := \"d:\\a\\b\\c.txt\"") // 输出:file_path := "d:\a\b\c.txt"
注意:
字符串是包含在双引号内的,如果双引号的字符串内还想再包含双引号,那就需要转义了,正如上例所示。但如果双引号内存在单引号,无需转义,会直接打印
fmt.Println("my name is 'egon'") // my name is 'egon'在go中单引号内包含的是字符类型,如果在字符的单引号内还想再包含单引号那也需要转义
fmt.Println('\'') // 单引号内表示的是字符类型,只能包含一个字符,如果该字符是单引号,那么必须转义反引号“
使用反引号代替双引号代表是原生字符,原生字符内没有转义操作,全部的内容都是字面的意思,会原样输出字符与换行等
s:=`
当你认清自己的时候
便\n\t\n\n不会再小瞧他人
\u4e0a
`
fmt.Println(s) // 输出如下内容
当你认清自己的时候
便\n\t\n\n不会再小瞧他人
\u4e0a
原生字符串面值用于编写正则表达式会很方便,因为正则表达式往往会包含很多反斜杠。原生字符串面值同时被广泛应用于HTML模板、JSON面值、命令行提示信息以及那些需要扩展到多行的场景。
了解unicode与utf-8
// ==========================> unicode <==========================
在很久以前,世界还是比较简单的,起码计算机世界就只有一个ASCII字符集:美国信息交换标准代码。ASCII,更准确地说是美国的ASCII,使用7bit来表示128个字符:包含英文字母的大小写、数字、各种标点符号和设置控制符。对于早期的计算机程序来说,这些就足够了,但是这也导致了世界上很多其他地区的用户无法直接使用自己的符号系统。随着互联网的发展,混合多种语言的数据变得很常见(译注:比如本身的英文原文或中文翻译都包含了ASCII、中文、日文等多种语言字符)。如何有效处理这些包含了各种语言的丰富多样的文本数据呢?
答案就是使用Unicode(http://unicode.org) ,它收集了这个世界上所有的符号系统,包括重音符号和其它变音符号,制表符和回车符,还有很多神秘的符号,在第八版本的Unicode标准收集了超过120,000个字符,涵盖超过100多种语言。这些在计算机程序和数据中是如何体现的呢?
// ==========================> unicode字符与unicode码点 <==========================
每个符号都被收录进了unicode中,称之为unicode字符,每一个unicode字符都被分配一个唯一的Unicode格式的数字,该数字称之为unincode的码点,通用的表示一个Unicode码点的数据类型是int32,也就是Go语言中的rune类型(rune是int32等价类型);它的同义词rune符文正是这个意思。
unicode遵循两种标准UCS-2和UCS-4,UCS-2用两个字节编码(go中对应的转义字符是\u),UCS-4用4个字节编码(go中对应的转义字符是\U),\uhhhh对应16bit的码点值,\Uhhhhhhhh对应32bit的码点值,其中h是一个十六进制数字;一般很少需要使用32bit的形式,这正如我们常说的那样,unicode通常用两个字节表示一个字符。
我们*可以*将一个符文序列表示为一个int32序列。这种编码方式叫UTF-32或UCS-4,每个Unicode码点都使用同样的大小32bit来表示。这种方式比较简单统一,但如果文本中包含的大多数都是英文字符的话,它会浪费很多存储空间,因为一个英文字符只需要8bit或1字节就能表示。而且我们常用的字符是远少于65,536个的,也就是说用16bit编码方式(UCS-2)就能表达常用字符。为了解决unicode的问题,utf-8应运而生。
// ==========================> utf-8 <==========================
前言:Utf-8就是unicode的一个标准,把unicode的内容进行了编排,它本质其实就是unicode,utf-8全称也是unicode的一个转换格式,在得到一个unicode后,我们通过将其按照utf-8的格式编排一下,更精简更美好
详细:
UTF8编码由Go语言之父Ken Thompson和Rob Pike共同发明的,现在已经是Unicode的标准。
UTF8全称(Unicode Transformation Format 8), 是一种将Unicode码点编码为字节序列的变长编码。
UTF8编码使用1到4个字节来表示每个Unicode码点,其中
- ASCII部分字符只使用1个字节
- 常用字符部分使用2或3个字节表示。
每个符号编码后第一个字节的高端bit位用于表示总共有多少编码个字节。如果第一个字节的高端bit为0,则表示对应7bit的ASCII字符,ASCII字符每个字符依然是一个字节,和传统的ASCII编码兼容。如果第一个字节的高端bit是110,则说明需要2个字节;后续的每个高端bit都以10开头。更大的Unicode码点也是采用类似的策略处理。
0xxxxxxx runes 0-127 (ASCII)
110xxxxx 10xxxxxx 128-2047 (values <128 unused)
1110xxxx 10xxxxxx 10xxxxxx 2048-65535 (values <2048 unused)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 65536-0x10ffff (other values unused)
utf-8这种变长的编码,因为变长而带来的缺点是:无法直接通过索引来访问第n个字符(python3中字符串被存成unicode的好处就是可以通过索引访问第n个字符,而这一点go语言是做不到的)
但是UTF8也因为变长获得了很多额外的优点:首先UTF8编码比较紧凑,完全兼容ASCII码,并且可以自动同步:它可以通过向前回朔最多2个字节就能确定当前字符编码的开始字节的位置。它也是一个前缀编码,所以当从左向右解码时不会有任何歧义也并不需要向前查看(译注:像GBK之类的编码,如果不知道起点位置则可能会出现歧义)。没有任何字符的编码是其它字符编码的子串,或是其它编码序列的字串,因此搜索一个字符时只要搜索它的字节编码序列即可,不用担心前后的上下文会对搜索结果产生干扰。同时UTF8编码的顺序和Unicode码点的顺序一致,因此可以直接排序UTF8编码序列。同时因为没有嵌入的NUL(0)字节,可以很好地兼容那些使用NUL作为字符串结尾的编程语言。
Go语言的源文件采用UTF8编码,并且Go语言处理UTF8编码的文本也很出色。unicode包提供了诸多处理rune字符相关功能的函数(比如区分字母和数组,或者是字母的大写和小写转换等),unicode/utf8包则提供了用于rune字符序列的UTF8编码和解码的功能。
更多关于字符编码的知识请参考
https://www.cnblogs.com/linhaifeng/articles/5950339.html
https://baike.baidu.com/item/Unicode/750500?fr=aladdin
https://www.kancloud.cn/lbb4511/gopl/1107841
https://www.kancloud.cn/lbb4511/gopl/1107842rune与byte
什么是rune?
// rune类型介绍
在unicode编码里,每个字符都对应为一个码点,一个码点就是一个数字,该数字对应go语言中的rune类型(rune是int32等价类型)
// rune类型示例
rune表达的是字符类型,存放字符需要用单引号包含,注意单引号内有且仅有一个字符
s1:='汪'
fmt.Println(s1)
fmt.Printf("%T",s1) // int32,即rune类型
s2:='汪汪' // 编译错误:invalid character literal (more than one character)
// rune类型中包含转义符
单引号字符必须转义
'\''
Unicode转义也可以使用在rune字符中。下面三个字符是等价的:
'世'
'\u4e16'
'\U00004e16'
对于小于256码点值可以写在一个十六进制转义字节中,例如'\x41'对应字符'A',但是对于更大的码点则必须使用\u或\U转义形式,因此,'\xe4\xb8\x96'并不是一个合法的rune字符,虽然这三个字节对应一个有效的UTF8编码的码点。
// ps
整型数字转换成ASCII字符
num := rune(90)
fmt.Println(string(num))
字符'A'被存成了int32,rune就是int32的别名
x:='A'
fmt.Println(x) // 65
fmt.Printf("%T\n",x) // int32
fmt.Println(string(x)) // A什么是byte?
字符串底层就是一个由byte组成的数组
//1、存字符串
1.1、存的时候,字符串内包含的可以直接就是现成的一个个byte,如s2:="\xe5\xb3\xb0",并且每一个byte都可以是任意byte
1.2、但是,存的时候,字符串内包含的也可以是字符/字符串面值,如下字符串由字符串面值构成,会按照utf-8格式编码成13个字节,然后存入底层数组
import "unicode/utf8"
s := "Hello, 世界"
fmt.Println(len(s)) // "13",代表底层数组中有13个字节
fmt.Println(utf8.RuneCountInString(s)) // "9",代表上述13个字节对应9个Unicode字符:
//2、读字符串
打印字符串时,会从底层数组中取出byte然后按照utf-8个格式转换成字符,如果当初存的时候无法无天,打印字符串的时候便有可能会出现乱码循环字符串的两种方式
- 1、依赖索引