一、面试问题
你的系统峰值qps多少,并发多少,架构是啥样子,如何抗的住的(硬件多少台、单台几颗cpu与多大内存)
例如:注册用户100万,每天日活几十万用户,每天请求量有几千万,高峰期QPS最大有5000/s+。从网关入口层进来的请求是5000/s的话,那你能画图说一下你负责的每个服务的接口的QPS是多少?然后你们的各个中间件,MySQL、Redis、ES、RocketMQ,他们各自的QPS都是多少?以及他们各自都部署了多少机器,每个机器什么配置?
二、须知
前提:高并发系统各不相同。比如
1、每秒百万并发的中间件系统
2、每日百亿请求的网关系统
3、瞬时每秒几十万请求的秒杀大促系统。
他们在应对高并发的时候,因为系统各自自身特点的不同,所以应对架构都是不一样的。
另外,比如电商平台中的订单系统、商品系统、库存系统,在高并发场景下的架构设计也是不同的,因为背后的业务场景什么的都不一样。
所以,这篇文章主要是给大家提供一个回答这类问题的思路,不涉及任何复杂架构设计,让你不至于在面试中被问到这个问题时,跟面试官大眼瞪小眼。
具体要真能在面试的时候回答好这个问题,建议各位参考一下本文思路,然后对你自己手头负责的系统多去思考一下,最好做一些相关的架构实践。
三、网站规模较小时
注册用户量总共就10万(用户量很少,日活用户按照不同系统的场景有区别)
我们取一个较为客观的比例,10%吧,每天活跃的用户就1万。
按照28法则,80%的用户访问集中在20%的时间段内
日活跃用户=10000
高峰期的活跃用户=10000 * 0.8=8000
高峰期每个用户平均发20个请求,总请求数=8000 * 20 = 160000
高峰期持续时间=24h * 0.2 = 4.8h,取个4h吧,即4*3600=14400秒
峰值qps=160000 / 14400 = 11
这个量级,跟高并发根本扯不上边
系统统层面每秒是10次请求
一个请求抵达应用程序后,应用程序为了处理该请求,通常会对数据库发起多次数据库操作,比如做做crud之类的。
假设每个请求会产生3次数据库操作,那数据库层每秒会接受30次请求
我们部署一台应用服务器:4c8G,加一台数据库服务器16c32G,完全够用了
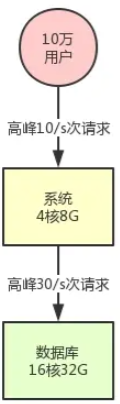
4c8G的应用服务,属于相对普通的服务器,抗个几百qps没问题
16c32G的服务器术语配置稍强的服务器,一般部署数据库这种重要组件,数据库软件本身比较笨重,然后结合16c32G的硬件配置,抗个上千qps也是没问题的
采用与数据库同等硬件配置的情况下,数据库因为本身软件比较笨重,也就大概抗个上千qps,而redis可以抗个上万,消息中间件可以抗个几十万
四、系统集群化部署-提升应用系统并发能力
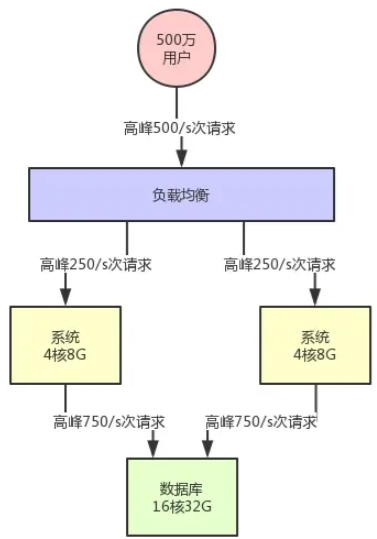
承接上一小节,注册用户量增长了50倍,上升到了500万,按经验取10%的活用用户,即每日活跃50万用户
采用与上一小节相同的计算方式,峰值qps也增长了50倍,
即
应用系统层峰值qps:500 qps
数据库峰值qps:1500 qps
按照16c32G的硬件服务器支撑数据库软件,抗个上千qps是没啥问题的(这个主要是要观察数据库所在机器的磁盘负载、网络负载、CPU负载、内存负载,按照我们的线上经验而言,那个配置的数据库在1500/s请求压力下是没问题的)
此时问题会集中在应用系统层,按照4c8G的配置,每秒请求打到500个,机器的cpu负载会比较高
此时我们可以引入负载均衡,代理多台4c8G的应用系统服务器,将500 qps均分,如下
五、数据库分库分表+读写分离->提升数据库抗并发能力
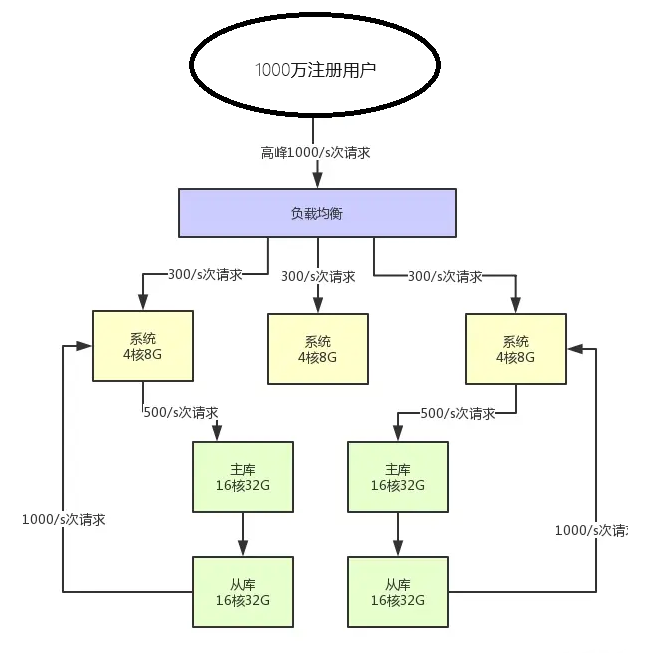
承接上一小节,用户量继续增长,在上一小节的基础上增长了2倍,注册用户达到了1000万,然后每天日活用户是100万。
指标在上一小节的基础上都翻了1倍
应用系统层峰值qps:1000 qps
数据库峰值qps:3000 qps
系统层面每秒要抗1000个请求:你可以继续通过集群化的方式来扩容,反正前面的负载均衡层会均匀分散流量过去的。
数据库层面每秒要抗3000个请求:这个就有点问题了。按照16C32G的这种硬件配置+数据库软件本身比较笨重的特点,一般超过3000qps就有问题了
你一定会发现线上的数据库负载越来越高。每次到了高峰期,磁盘IO、网络IO、内存消耗、CPU负载的压力都会很高,大家很担心数据库服务器能否抗住。
解决方案:就是把数据库的读与写拆分开,分别优化、分别提并发
答案就是:分库分表+读写分离+双主挂多从,
此时假设对数据库层面的读写并发是3000/s,其中写并发占到了1000/s,读并发占到了2000/s。
那么一旦分库分表之后,采用两台数据库服务器上部署主库来支撑写请求,每台服务器承载的写并发就是500/s。每台主库挂载一个服务器部署从库,那么2个从库每个从库支撑的读并发就是1000/s。
简单总结,并发量继续增长时,我们就需要focus在数据库层面:分库分表、读写分离。如下图
六、引入缓存->提升并发读效率
承接上一小节,如果注册用户量继续增大,你该怎么办???
很好办,加机器就行
系统层:比如说系统层面不停加机器,就可以承载更高的并发请求。
数据库层:数据库层面如果写入并发越来越高,就扩容加数据库服务器,通过分库分表是可以支持扩容机器的,如果数据库层面的读并发越来越高,就扩容加更多的从库。
但是,单纯的增加数据库实例/服务的数量是不对的,性价比不高
因为数据库其实本身不是用来承载高并发请求的,所以通常来说,数据库单机每秒承载的并发就在几千的数量级,而且数据库使用的机器都是比较高配置,比较昂贵的机器,成本很高
同等配置下,数据库能抗个几千qps,redis缓存可以抗住上万qps,甚至数十万,对高并发的承载能力比数据库系统要高出一到两个数量级。
所以在高并发架构里通常都有缓存这个环节,缓存系统的设计就是为了承载高并发而生。
切记,引入缓存是为了优化读并发,而不是写并发,所以场景一定是写少、读多,才能引入缓存集群,如此便可以用更少的机器资源承载更高的并发
比如说上一小节的图里,读请求目前是每秒2000/s,两个从库各自抗了1000/s读请求,但是其中可能每秒1800次的读请求都是可以直接读缓存里的不怎么变化的数据的。
那么此时你一旦引入缓存集群,就可以抗下来这1800/s读请求,落到数据库层面的读请求就200/s。
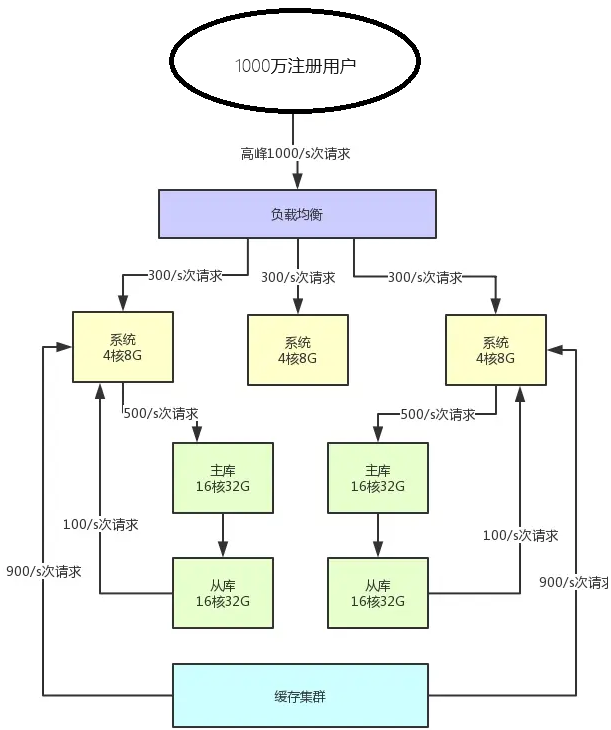
上述架构的好处是:
可能未来你的系统读请求每秒都几万次了,但是可能80%~90%都是通过缓存集群来读的,而缓存集群里的机器可能单机每秒都可以支撑几万读请求,所以耗费机器资源很少,可能就两三台机器就够了。
你要是换成是数据库来试一下,可能就要不停的加从库到10台、20台机器才能抗住每秒几万的读并发,那个成本是极高的。
总结:
不要盲目进行数据库扩容,数据库服务器成本昂贵,且本身就不是用来承载高并发的 ,针对写少读多的请求,引入缓存集群,用缓存集群抗住大量的读请求
七、引入消息中间件集群->提升并发写效率
接着再来看看数据库写这块的压力,其实是跟读类似的。
不能靠单纯的增加数据库实例/服务器个数来增强
当然你说我增加数据库实例/服务个数能不能行,担任也可以,但是同理,你耗费的机器资源是很大的,这个就是数据库系统的特点所决定的。
相同的资源下,数据库系统太重太复杂,所以并发承载能力就在几千/s的量级,所以此时你需要引入别的一些技术。
比如说消息中间件技术,也就是MQ集群,他是非常好的做写请求异步化处理,实现削峰填谷的效果。
承接上一小节,对于写操作,你现在每秒是1000/s次写请求,其中比如
1、500次请求是必须请求过来立马写入数据库中的
2、但是另外500次写请求是可以允许异步化等待个几十秒,甚至几分钟后才落入数据库内的。
那么此时你完全可以引入消息中间件集群,把允许异步化的每秒500次请求写入MQ,然后基于MQ做一个削峰填谷。比如就以平稳的100/s的速度消费出来然后落入数据库中即可,此时就会大幅度降低数据库的写入压力。
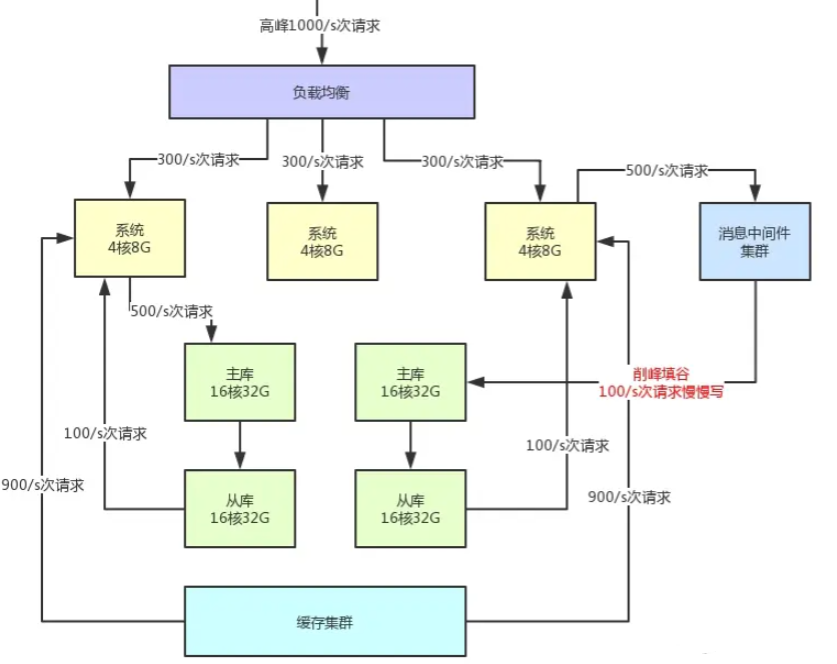
大家看上面的架构图,首先消息中间件系统本身也是为高并发而生,所以通常单机都是支撑几万甚至十万级的并发请求的。
所以,他本身也跟缓存系统一样,可以用很少的资源支撑很高的并发请求,用他来支撑部分允许异步化的高并发写入是没问题的,比使用数据库直接支撑那部分高并发请求要减少很多的机器使用量。
而且经过消息中间件的削峰填谷之后,比如就用稳定的100/s的速度写数据库,那么数据库层面接收的写请求压力,不就成了500/s + 100/s = 600/s了么?
总结:
系统层面:集群化
数据库层面:分库分表+读写分离 针对读多写少的请求,引入缓存集群 针对高写入的压力,引入消息中间件集群,
八、其他
参考:https://egonlin.com/?cat=455
九、学员问题
1、如果是微服务架构,高峰期时,如何搞清楚每个微服务对外暴漏的接口所经受的qps
答:需要搞清楚具体业务请求流程,以某一个请求为例,搞清楚请求链路,比如请求先到了serviceA、又到了serviceB、然后到了serviceC
通过负载均衡分发过来的流量为300qps,需要由serviceA、serivceB、serviceC来完成,那这三个微服务接口接受到的峰值qps都是300
所以,一定要结合业务,搞清楚业务请求链路
2、微服务是服务部署的?
学员的思路:
微服务架构下高并发场景,每个微服务都可能扩展为一个集群,部一个专门的负载均衡代理这多个副本,对于同一个微服务,例如serviceA,要部署在一台服务器上,它的一个副本应该部署在另外一台机器上
反问学员:为何同一个微服务的多个副本要部署在不同的服务器上呢?
学员答:因为要考虑到服务器的单独故障问题
回答的很好,那如果我解决了单点故障问题,例如某一台主机挂掉,其上的所有服务可以自动漂移到其他物理节点上,是不是说同一个微服务就不再受节点的单点故障限制了,既可以部署到一个服务器,也可以是不同服务器,谁的资源充足更适合跑新副本 ,那就用谁!没错,确实是这个样子,k8s就可以帮我们解决这个问题