一、本节的主题
诸如两地三中心、同城双活、异地双活等方案,都是为了实现跨机房的高可用
二、为何要跨机房实现高可用
在单个机房里玩 为了解决单点故障--------》我们在同一个机房里部署了服务器集群 并且在一个机房里--------》服务器双电源、服务器打散放置在不同机柜、交换机/路由器线路冗余 然而,你在单机房里做的集群再牛逼也没用,因为一个机房也是可能挂掉的!!! 一般来讲,建设一个机房的要求其实是很高的,地理位置、温湿度控制、备用电源等等, 机房厂商会在各方面做好防护。但即使这样,我们每隔一段时间还会看到这样的新闻: 2015 年 5 月 27 日,杭州市某地光纤被挖断,近 3 亿用户长达 5 小时无法访问支付宝 2021 年 7 月 13 日,B 站部分服务器机房发生故障,造成整站持续 3 个小时无法访问 2021 年 10 月 9 日,富途证券服务器机房发生电力闪断故障,造成用户 2 个小时无法登陆、交易 机房挂掉的概率很小,你职业生涯一辈子怕是也碰不上一次,费尽心机去做跨机房的高可用真的有意义吗? 答:系统架构的不同阶段,关注点是不一样的 体量很小的系统:重点关注「用户」规模、增长,这个阶段获取用户是一切。 等用户体量上来了:会重点关注「性能」,优化接口响应时间、页面打开速度等等,这个阶段更多是关注用户体验。 等体量再大到一定规模后你会发现:「可用性」就变得尤为重要。像微信、支付宝这种全民级的应用, 如果机房发生一次故障,那整个影响范围可以说是非常巨大的,此时你费尽心机去做的跨机房高可用就十分值得了 到底该怎么应对机房级别的故障呢? 想要抵御「机房」级别的风险,那应对方案就不能局限在一个机房内了。 需要做机房级别的冗余方案,也就是说,你需要再搭建1个或多个机房,来部署你的服务 大前提: 1、机房时间一致 2、专线 具体方案: 1、同城灾备 2、同城双活 3、两地三中心 4、伪异地双活 5、真正的异地双活 6、异地多活
三、跨机房高可用方案
同城灾备-冷备: B 机房只做备份数据,不提供服务,A机房故障时无法直接切到B机房让其投入使用
冷备场景下,A机房整个挂掉,需要 1、依据B机房来恢复数据到A机房,并重启修复A机房的服务,修复期间服务不可用,无法保证高可用 总结特点: 没啥高可用可言,B机房就是用来单纯防止数据丢失的
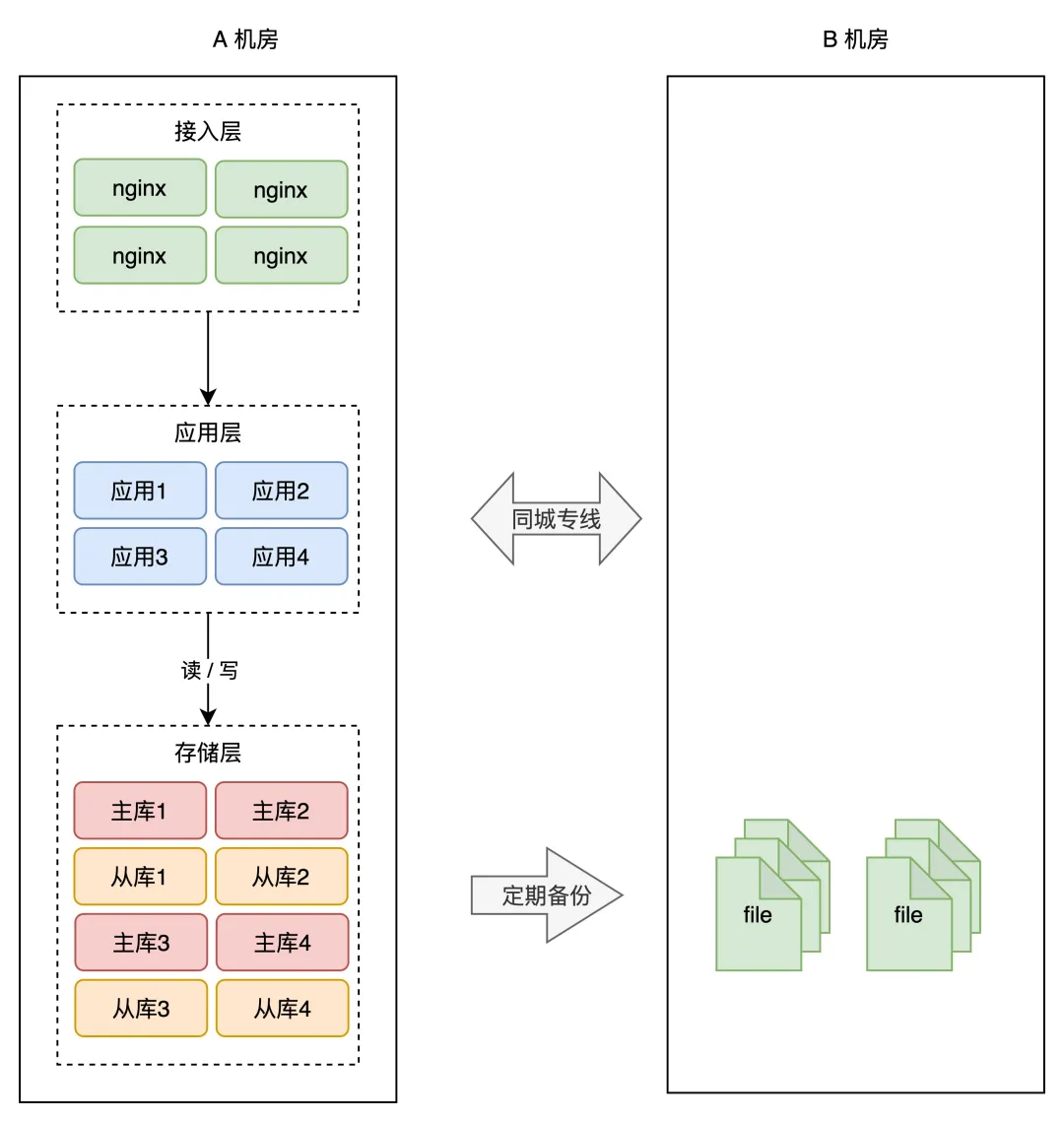
同城灾备-热备:A机房故障,B机房可以立即投入使用
热备场景下,A 机房整个挂掉,我们只需要做 2 件事即可: 1、B 机房所有从库提升为主库 2、DNS 指向 B 机房,接入流量,业务恢复 总结“同城灾备-热备”的特点: 1、B机房相当于A机房的镜像 2、注意数据是单向同步的 3、B机房平时并没有接入流量,直到故障的时候才会接入流量
1、平时B机房不接流量(战斗经验几乎为0),无法验证其是否可用,真的切流量那一刻咬不准是否可以如期工作 部署一个机房尚且会遇到版本不一致、资源不足、操作系统参数不一致的问题,再来个B机房,问题只会多不会少 2、B机房花了那么多做出来,只留做镜像,太浪费了 功夫要下载平时、并且要利用起来----》同城双活(B机房在平时就要参与战斗)
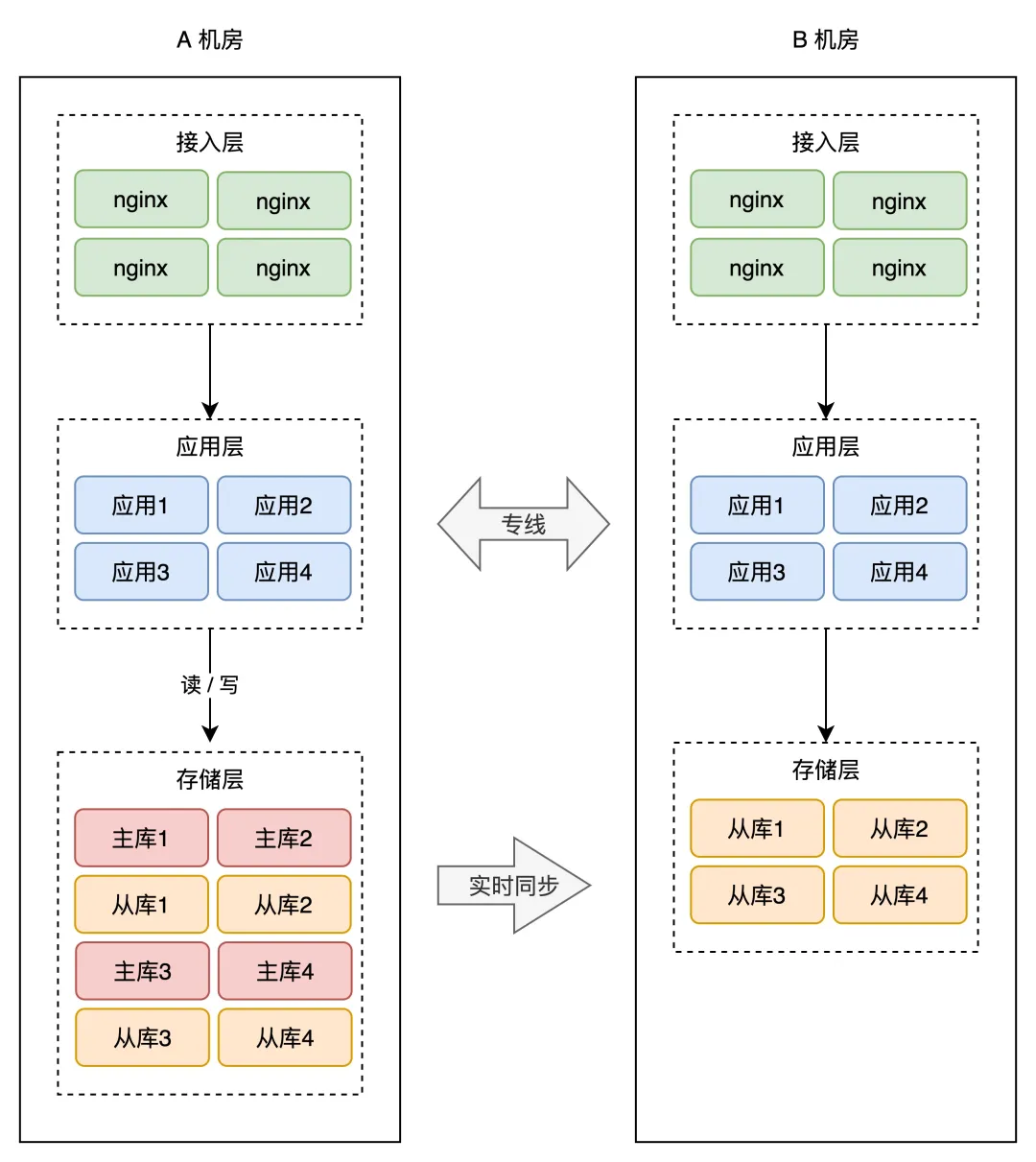
1、B机房接入流量,平时就参与战斗验证可用性,同时也可以分摊A机房的压力 2、如何让B机房有流量?把B机房的接入层IP也加入到DNS中,即DNS同时解析A、B两个机房的ip地址 3、底层数据库还是单向的主从 4、应用层需要做读写分离,(一般用中间件实现),即两个机房的「读」流量,可以读任意机房的存储, 但「写」流量,只允许写 A 机房,因为主库在 A 机房。 这会涉及到你用的所有存储,例如项目中用到了 MySQL、Redis、MongoDB 等等,操作这些数据库, 都需要区分读写请求,所以这块需要一定的业务「改造」成本。 5、两个机房部署在「同城」,物理距离比较近,而且两个机房用「专线」网络连接, 虽然跨机房访问的延迟比单个机房内要大一些,但整体的延迟还是可以接受的。 6、业务改造完成后,B 机房可以慢慢接入流量,从 10%、30%、50% 逐渐覆盖到 100%, 你可以持续观察 B 机房的业务是否存在问题,有问题及时修复,逐渐让 B 机房的工作能力,达到和 A 机房相同水平。 7、因为 B 机房实时接入了流量,此时如果 A 机房挂了,那我们就可以「大胆」地把 A 的流量, 全部切换到 B 机房,完成快速切换!
同城双活的问题:
2个机房在物理层面还是处于「一个城市」内,如果是整个城市发生自然灾害,例如地震、水灾(河南水灾刚过去不久), 那 2 个机房依旧存在「全局覆没」的风险。
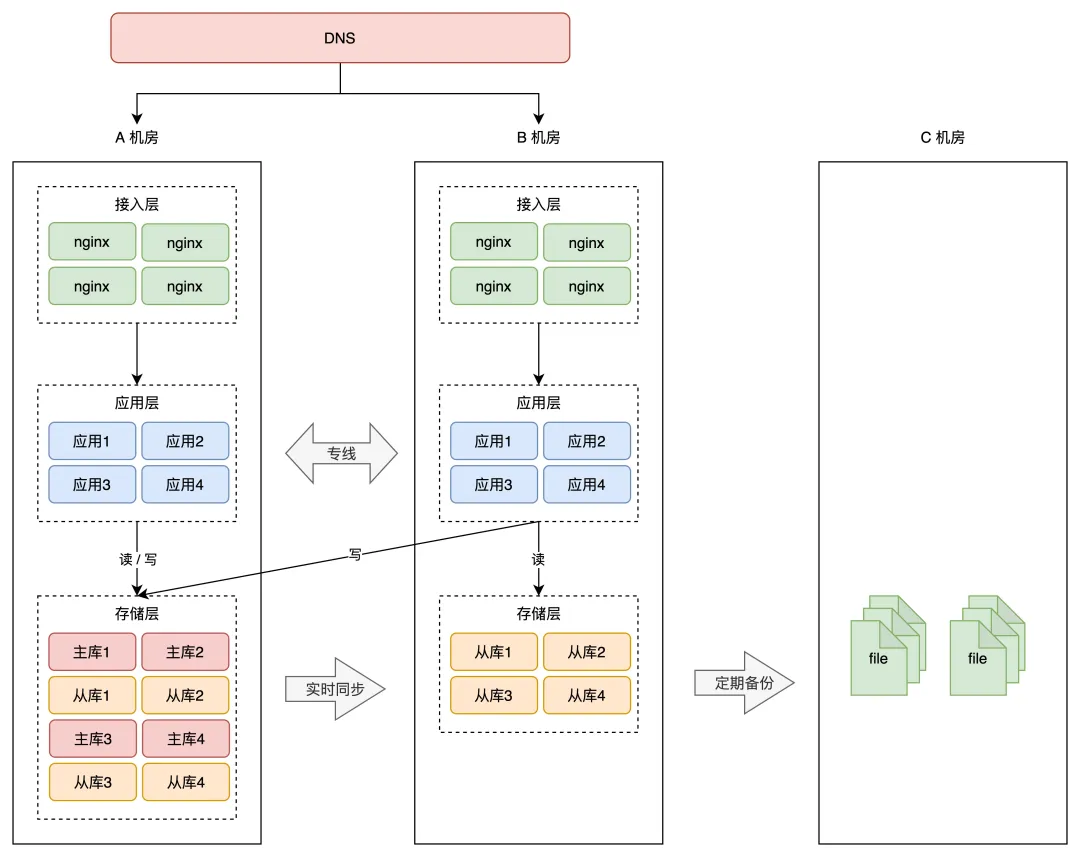
两地三中心:在同城双活的基础上,加一个异地冷备中心定期备份数据(冷备就行)
通常建议第三个异地机房的距离同成双活机房要在 1000 公里以上,这样才能应对城市级别的灾难。 假设之前的 A、B 机房在北京,那这次新部署的 C 机房可以放在上海。
两地是指 2 个城市,三中心是指有 3 个机房,其中 2 个机房在同一个城市,并且同时提供服务,第 3 个机房部署在异地,只做数据灾备。
这种架构方案,通常用在银行、金融、政企相关的项目中。它的问题还是前面所说的,启用灾备机房需要时间,而且启用后的服务,不确定能否如期工作。
所以,要想真正的抵御城市级别的故障,越来越多的互联网公司,开始实施「异地双活」。
这里,我们还是分析 2 个机房的架构情况。我们不再把 A、B 机房部署在同一个城市,而是分开部署,例如 A 机房放在北京,B 机房放在上海。
前面我们讲了同城双活,那异地双活是不是直接「照搬」同城双活的模式去部署就可以了呢?
事情没你想的那么简单。
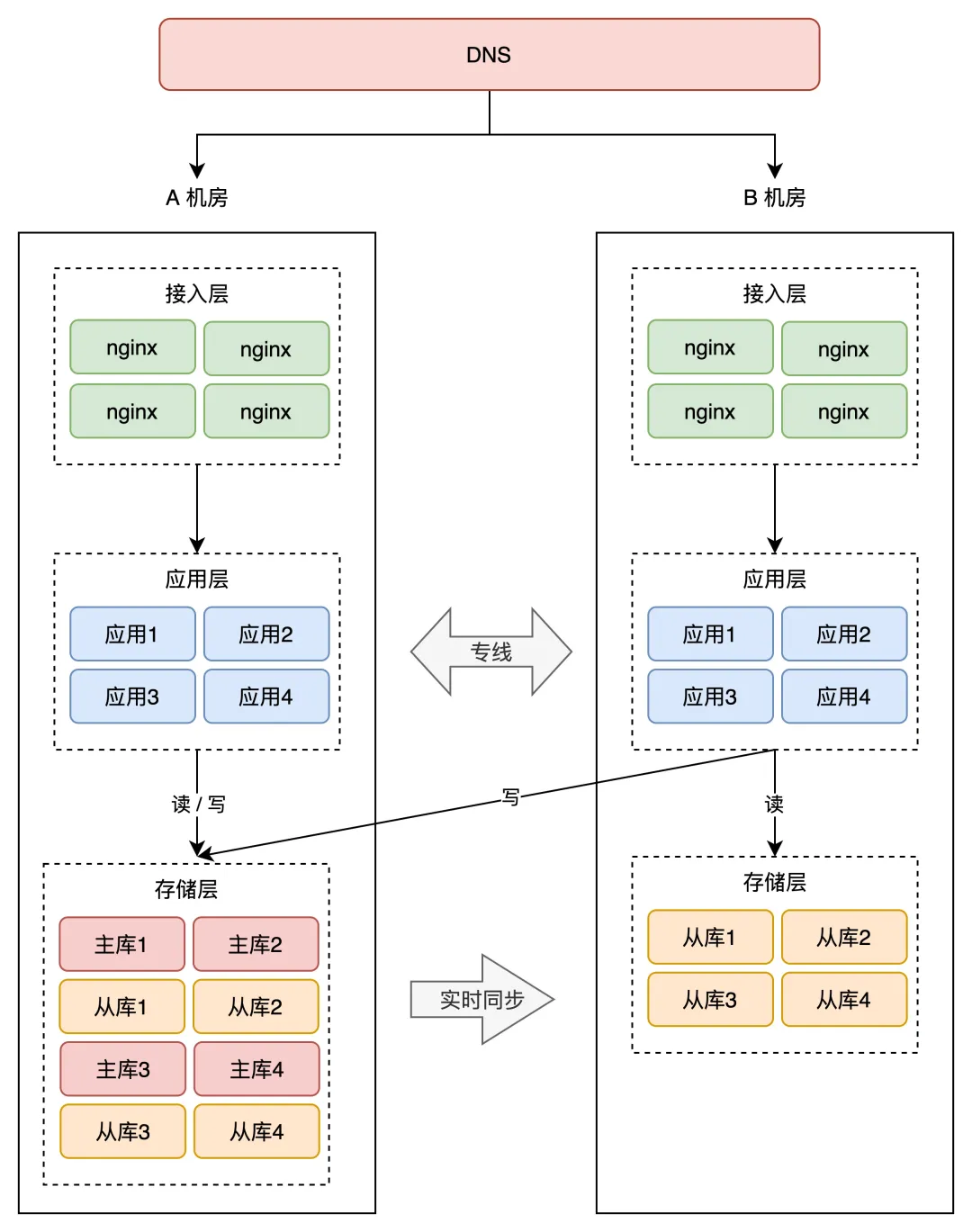
如果还是按照同城双活的架构来部署,那异地双活的架构就是这样的:
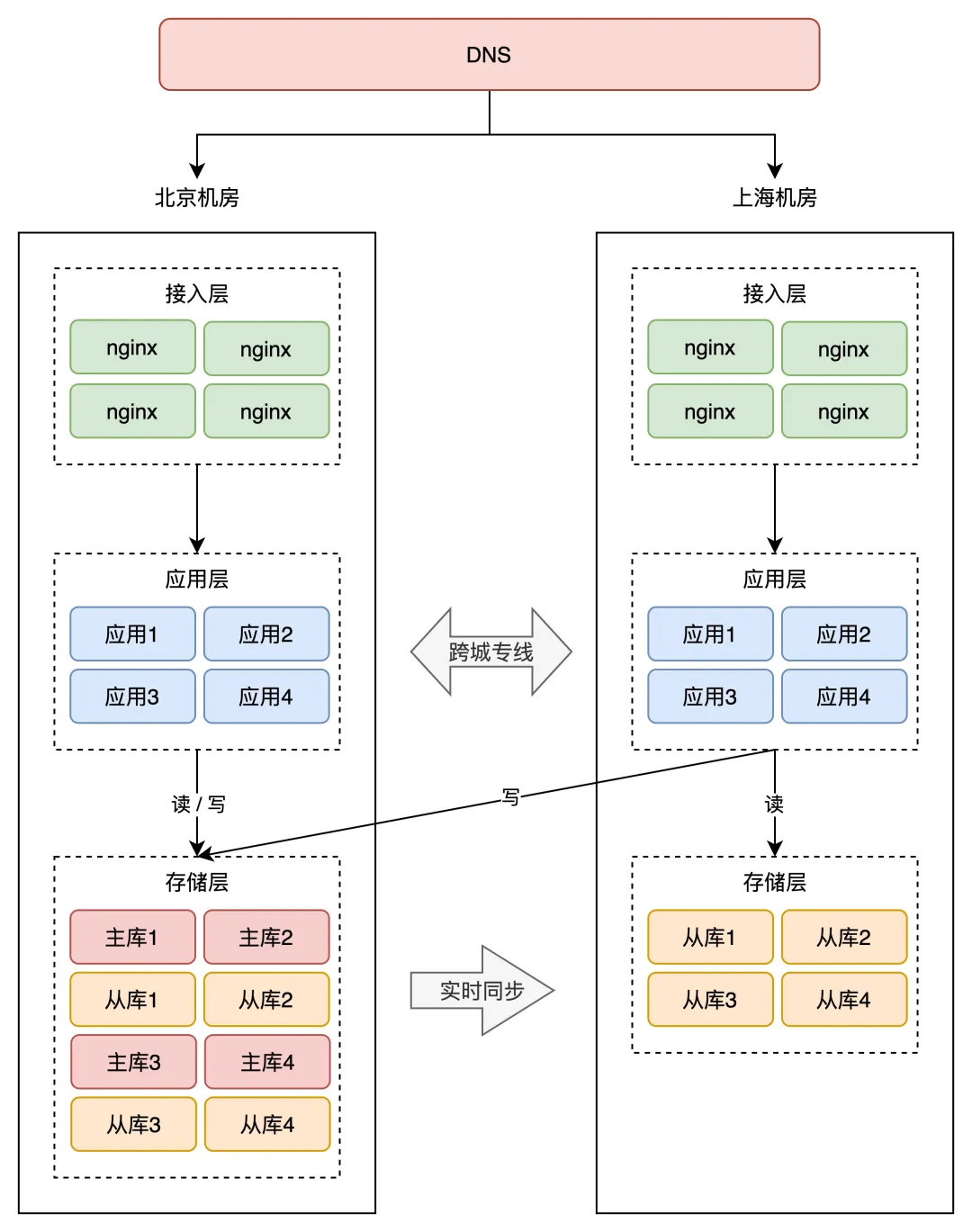
注意看,两个机房的网络是通过「跨城专线」连通的。
此时两个机房都接入流量,那上海机房的请求,可能要去读写北京机房的存储,这里存在一个很大的问题:网络延迟。 因为两个机房距离较远,受到物理距离的限制,现在,两地之间的网络延迟就变成了「不可忽视」的因素了。 北京到上海的距离大约 1300 公里, 即使架设一条高速的「网络专线」,光纤以光速传输,一个来回也需要近 10ms 的延迟。 况且,网络线路之间还会经历各种路由器、交换机等网络设备, 实际延迟可能会达到 30ms ~ 100ms,如果网络发生抖动,延迟甚至会达到 1 秒。
不止是延迟,远距离的网络专线质量,是远远达不到机房内网络质量的, 专线网络经常会发生延迟、丢包、甚至中断的情况。总之,不能过度信任和依赖「跨城专线」。
你可能会问,这点延迟对业务影响很大吗?影响非常大!
试想,一个客户端请求打到上海机房,上海机房要去读写北京机房的存储,一次跨机房访问延迟就达到了 30ms, 这大致是机房内网网络(0.5ms)访问速度的60倍(30ms / 0.5ms),一次请求慢60倍,来回往返就要慢 100 倍以上 而我们在 App 打开一个页面,可能会访问后端几十个 API,每次都跨机房访问, 整个页面的响应延迟有可能就达到了秒级,这个性能简直惨不忍睹,难以接受。 看到了么,虽然我们只是简单的把机房部署在了「异地」,但「同城双活」的架构模型,在这里就不适用了, 还是按照这种方式部署,这是「伪异地双活」!那如何做到真正的异地双活呢?
前提:
避免跨机房的[调用]、来规避跨机房的延迟问题
结论:
每个机房都只能读写自己机房的数据
实现:
1、底层数据库、redis、mongod等都是双向的主从,即主主模式 mysql自己就支持主主,而redis、mongod默认不支持、需要单独开发中间件,或使用阿里的 以及有状态的RabbitMQ、Kafka也需要开发双向同步中间件,支持任何机房写入数据会自动同步到另外一个机房 开源的中间件: 例如阿里的 Canal、RedisShake、MongoShake,可分别在两个机房同步 MySQL、Redis、MongoDB 数据。 很多有能力的公司,也会采用自研同步中间件的方式来做,例如饿了么、携程、美团都开发了自己的同步中间件。 2、dns指向两个机房的地址
整个架构如下图
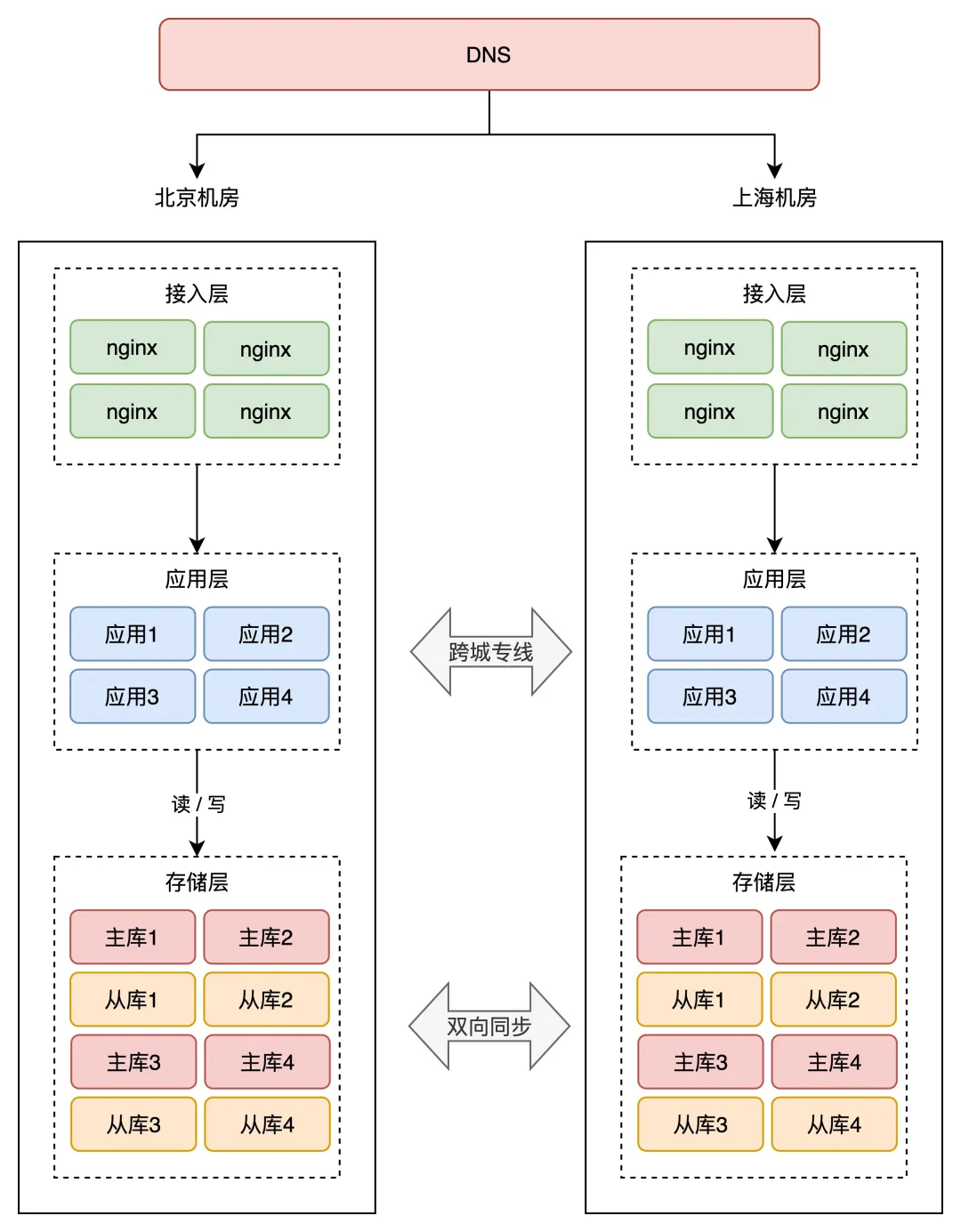
跨城双主的问题
双主有一个问题,就是同一个用户的并发请求由dns解析到了两个机房,写的是同一份数据,导致冲突 例如: 1、用户短时间内发了 2 个修改请求,都是修改同一条数据 2、一个请求落在北京机房,修改 X = 1(还未同步到上海机房) 3、另一个请求落在上海机房,修改 X = 2(还未同步到北京机房) 4、两个机房以哪个为准? 也就是说,在很短的时间内,同一个用户修改同一条数据,两个机房无法确认谁先谁后,数据发生「冲突」。
解决方案一:数据同步中间件开发合并数据、解决冲突的能力(该方案依赖主从机房时钟同步)
这个方案实现起来比较复杂,要想合并数据,就必须要区分出「先后」顺序。 我们很容易想到的方案,就是以「时间」为标尺,以「后到达」的请求为准。 但这种方案需要两个机房的「时钟」严格保持一致才行,否则很容易出现问题。例如: 1、第 1 个请求落到北京机房,北京机房时钟是 10:01,修改 X = 1 2、第 2 个请求落到上海机房,上海机房时钟是 10:00,修改 X = 2 因为北京机房的时间「更晚」,那最终结果就会是 X = 1。但这里其实应该以第 2 个请求为准,X = 2 才对。 可见,完全「依赖」时钟的冲突解决方案,不太严谨。 所以,通常会采用第二种方案,从「源头」就避免数据冲突的发生。
解决方案二:从源头规避冲突发生,即在最上层接入流量时,就不要让冲突的情况发生
在接入层之上,再部署一个「路由层」(通常部署在云服务器上),自己可以配置路由规则,把用户「分流」到不同的机房内,并且 后续访问就固定在该机房,如此便从根源上避免「跨机房」。(dns---》路由层----〉主、从机房)
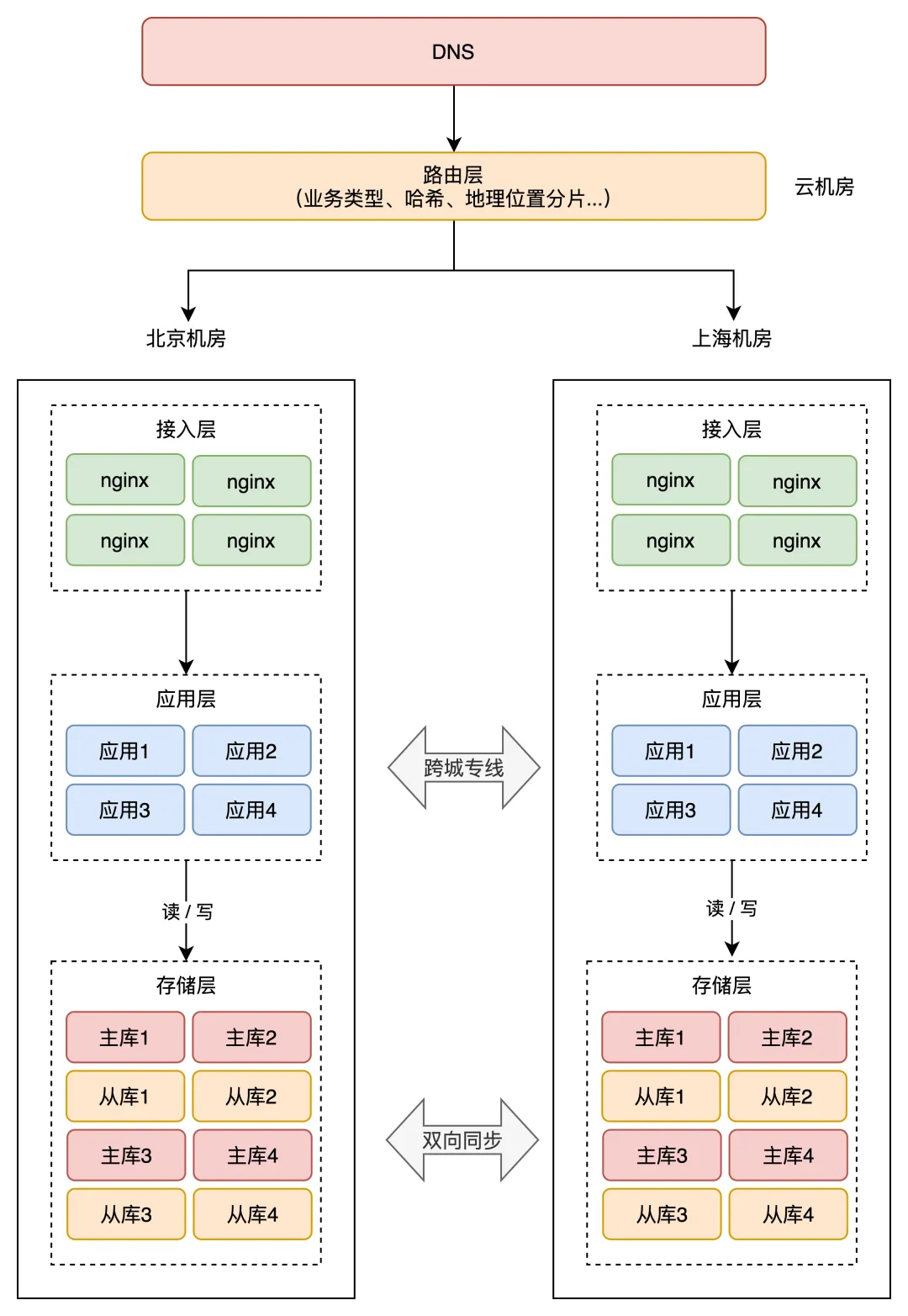
但这个路由规则,具体怎么定呢?有很多,常见的有 3 类:
1、按业务类型分片 1、2应用只读写北京机房存储,3、4应用只读写南京机房存储 举例: 假设我们一共有 4 个应用,北京和上海机房都部署这些应用。 但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。 2、直接哈希分片 例如根据用户id hash得到机房编号,以此控制固定路由到某个机房 举例: 一共 200 个用户,根据用户 ID 计算哈希值,然后根据路由规则, 把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房, 这样,就避免了同一个用户修改同一条数据的情况发生。 3、按地理位置分片 例如打车、外卖就非常适合 举例: 北京、河北地区的用户点餐,请求只会打到北京机房,而上海、浙江地区的用户,请求则只会打到上海机房。 这样的分片规则,也能避免数据冲突。
异地多活:有多种实现,建议采用星型同步:即有一个中心机房,其他都跟他同步
理解了异地双活,那「异地多活」顾名思义,就是在异地双活的基础上,部署多个机房即可。
架构可以是这样:任一存储层都与其他机房的存储层同步(这种并非是星型同步,会有问题,往下看)
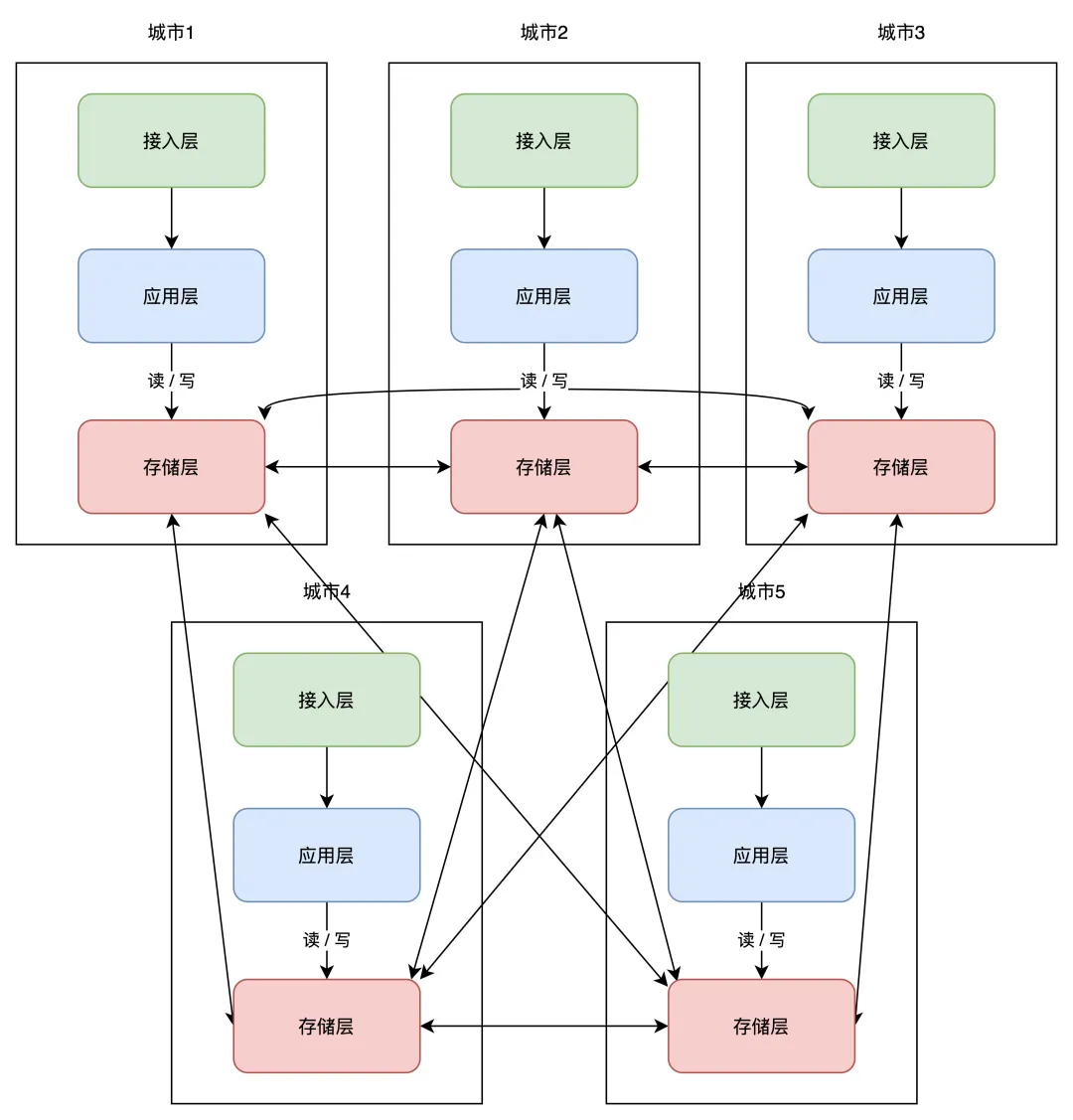
这些服务按照「单元化」的部署方式,可以让每个机房部署在任意地区,随时扩展新机房,你只需要在最上层定义好分片规则就好了。
但这里还有一个小问题,随着扩展的机房越来越多,当一个机房写入数据后,需要同步的机房也越来越多,这个实现复杂度会比较高。
所以业界又把这一架构又做了进一步优化,把「网状」架构升级为「星状」:
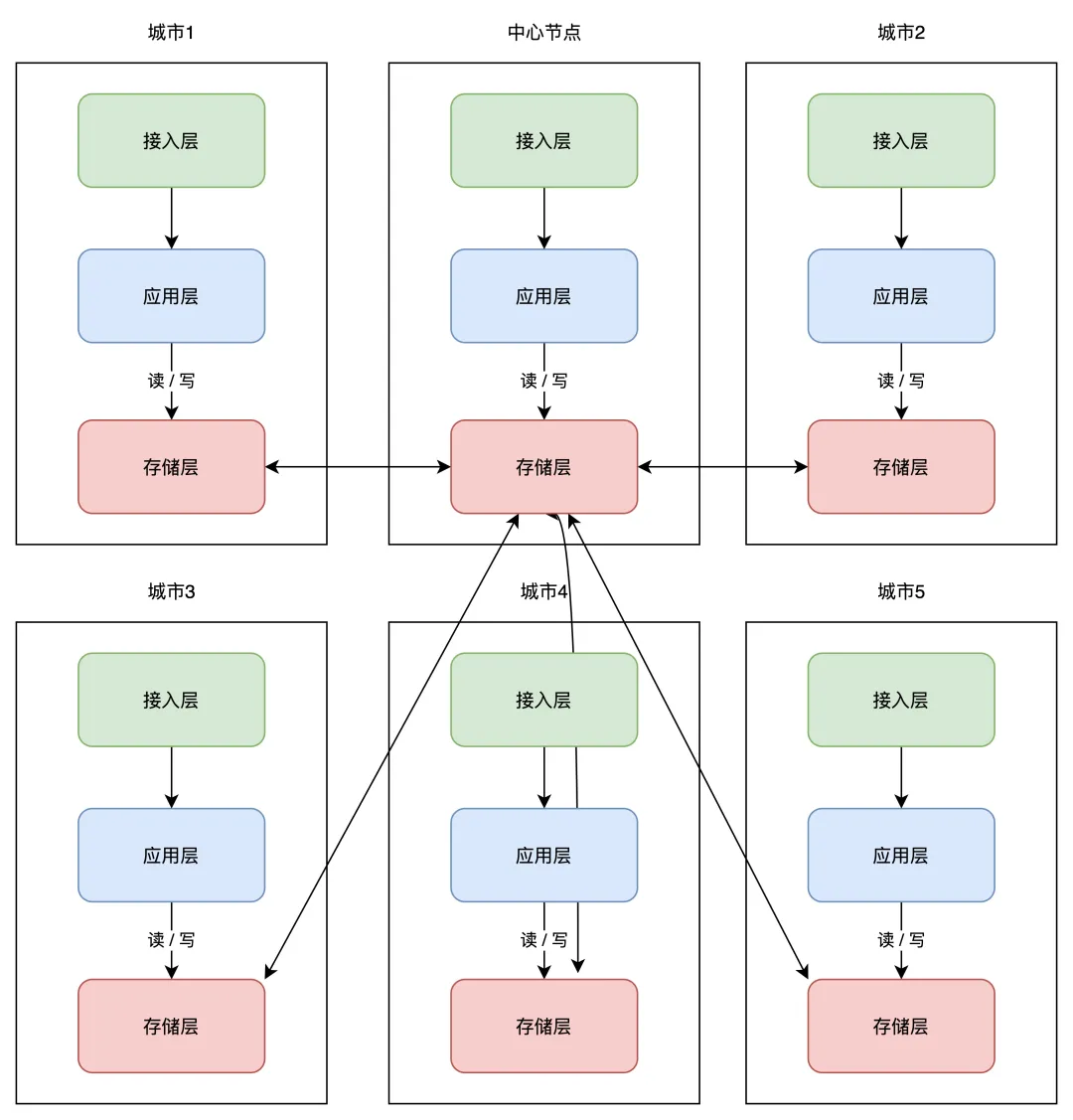
这种方案必须设立一个「中心机房」,任意机房写入数据后,都只同步到中心机房,再由中心机房同步至其它机房。
这样做的好处是,一个机房写入数据,只需要同步数据到中心机房即可,不需要再关心一共部署了多少个机房,实现复杂度大大「简化」。
但与此同时,这个中心机房的「稳定性」要求会比较高。不过也还好,即使中心机房发生故障,我们也可以把任意一个机房,提升为中心机房,继续按照之前的架构提供服务。
至此,我们的系统彻底实现了「异地多活」!
多活的优势在于,可以任意扩展机房「就近」部署。任意机房发生故障,可以完成快速「切换」,大大提高了系统的可用性。
同时,我们也再也不用担心系统规模的增长,因为这套架构具有极强的「扩展能力」。
前提:
机房时间一致
专线
同城灾备:
1、底层数据采用的是单向的主从
2、另外一个机房做备份,主机房故障后,dns指向从机房
同城双活:
1、底层数据采用的依然是单向主从
2、dns同时解析主、从两个机房的地址
两地三中心:
1、同城双活的基础上,加一个异地冷备中心定期备份数据
异地双活:
1、底层数据库、redis、mongod等都是双向的主从,即主主模式,mysql自己就支持,redis、mongod需要单独开发中间件,
或使用阿里的 redisshake、mongoshake
2、dns指向两个机房的地址
3、双主有一个问题,就是同一个用户的并发请求由dns解析到了两个机房,写的是同一份数据,导致冲突
解决方案:
方案1、数据同步中间件开发合并数据、解决冲突的能力(该方案依赖主从机房时钟同步)
方案2、从源头规避冲突发生
增量一个路由层,控制流量转发
dns---》路由层----〉主、从机房
最常见的路由分片规则:目的是为了让用户在一个机房完成业务闭环,防止出现跨机房访问
按业务类型分片:1、2应用只读写北京机房存储,3、4应用只读写南京机房存储
直接hash分片:例如根据用户id hash得到机房编号,以此控制固定路由到某个机房
按照地理位置分:例如打车、外卖就非常适合
4、部分例如库存这种应用,要求强一致性,那就不做异地双活,就是单机房,单向主从
异地多活:
星型同步:有一个中心机房,其他都跟他同步
详见原文:https://mp.weixin.qq.com/s/hWCmnsa3rdtMFTE_BSyg2w